 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezing Capacity from Multimodal Large Language Models for Subject-driven Generation
May 25, 2026Subject-driven image generation aims to synthesize new images that preserve the identity of the given subject while following textual instructions. Existing approaches often encode text and reference images separately. This limits cross-modal reasoning abilities and causes copy-paste artifacts. Recent frameworks that connect multimodal models and diffusion models improve instruction following, but largely overlook identity preservation. To address these limitations, we condition diffusion models on Multimodal Large Language Models (MLLMs) that jointly encode text and reference images, and augment it with VAE-based identity conditioning. A novel Dual Layer Aggregation (DLA) module is designed to aggregate multi-level MLLM features for optimal conditioning, and a multi-stage denoising strategy is applied to progressively balance the semantic information from MLLM and fine-detail identity from VAE during inference. Extensive experiments demonstrate that our approach harmonizes multimodal understanding with identity preservation, mitigates copy-paste issues, and achieves superior performance regarding human preference on subject-driven image generation. Our project website is available at https://zsh2000.github.io/squeeze-mllm-subject-gen/.
Good Token Hunting: A Hitchhiker's Guide to Token Selection for Visual Geometry Transformers
May 22, 2026Visual geometry transformers have become powerful architectures for multi-view 3D reconstruction, enabling joint prediction of multiple 3D attributes in a feed-forward manner. However, their computational cost grows quadratically with the input sequence length due to the global attention layers inside these models. This limits both their scalability and efficiency. In this work, we address this challenge with a simple yet general strategy: restricting the number of key/value tokens that each query interacts with during global attention. To achieve effective token selection, we introduce a two-stage framework. First, an inter-frame selection step operates at the frame level to identify frames that should be preserved. Second, an intra-frame selection step further discards more redundant tokens within the selected frames. Our analysis highlights the advantage of a diversity-based strategy for inter-frame selection, which ensures broad coverage of the scene. For intra-frame selection, we show that layer-aware sparsification is necessary, with the selection process guided by the entropy of the global attention pattern. Our approach offers a superior speed-accuracy trade-off compared to existing solutions. Extensive experiments show that it accelerates visual geometry transformers by over 85% for scenes with 500 images while maintaining, or even improving, baseline performance, which hints that how our token selection strategy can play a crucial role in future applications of visual geometry transformers. Our project website is available at https://zsh2000.github.io/good-token-hunting.github.io.
Diff-2-in-1: Bridging Generation and Dense Perception with Diffusion Models
Nov 07, 2024



Beyond high-fidelity image synthesis, diffusion models have recently exhibited promising results in dense visual perception tasks. However, most existing work treats diffusion models as a standalone component for perception tasks, employing them either solely for off-the-shelf data augmentation or as mere feature extractors. In contrast to these isolated and thus sub-optimal efforts, we introduce a unified, versatile, diffusion-based framework, Diff-2-in-1, that can simultaneously handle both multi-modal data generation and dense visual perception, through a unique exploitation of the diffusion-denoising process. Within this framework, we further enhance discriminative visual perception via multi-modal generation, by utilizing the denoising network to create multi-modal data that mirror the distribution of the original training set. Importantly, Diff-2-in-1 optimizes the utilization of the created diverse and faithful data by leveraging a novel self-improving learning mechanism. Comprehensive experimental evaluations validate the effectiveness of our framework, showcasing consistent performance improvements across various discriminative backbones and high-quality multi-modal data generation characterized by both realism and usefulness.
Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
Sep 05, 2024



Complex 3D scene understanding has gained increasing attention, with scene encoding strategies playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present a comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image-based, video-based, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluations yield key findings: DINOv2 demonstrates superior performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, and language-pretrained models show unexpected limitations in language-related tasks. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene-understanding tasks.
Multi-task View Synthesis with Neural Radiance Fields
Sep 29, 2023



Multi-task visual learning is a critical aspect of computer vision. Current research, however, predominantly concentrates on the multi-task dense prediction setting, which overlooks the intrinsic 3D world and its multi-view consistent structures, and lacks the capability for versatile imagination. In response to these limitations, we present a novel problem setting -- multi-task view synthesis (MTVS), which reinterprets multi-task prediction as a set of novel-view synthesis tasks for multiple scene properties, including RGB. To tackle the MTVS problem, we propose MuvieNeRF, a framework that incorporates both multi-task and cross-view knowledge to simultaneously synthesize multiple scene properties. MuvieNeRF integrates two key modules, the Cross-Task Attention (CTA) and Cross-View Attention (CVA) modules, enabling the efficient use of information across multiple views and tasks. Extensive evaluation on both synthetic and realistic benchmarks demonstrates that MuvieNeRF is capable of simultaneously synthesizing different scene properties with promising visual quality, even outperforming conventional discriminative models in various settings. Notably, we show that MuvieNeRF exhibits universal applicability across a range of NeRF backbones. Our code is available at https://github.com/zsh2000/MuvieNeRF.
3D-LLM: Injecting the 3D World into Large Language Models
Jul 24, 2023Large language models (LLMs) and Vision-Language Models (VLMs) have been proven to excel at multiple tasks, such as commonsense reasoning. Powerful as these models can be, they are not grounded in the 3D physical world, which involves richer concepts such as spatial relationships, affordances, physics, layout, and so on. In this work, we propose to inject the 3D world into large language models and introduce a whole new family of 3D-LLMs. Specifically, 3D-LLMs can take 3D point clouds and their features as input and perform a diverse set of 3D-related tasks, including captioning, dense captioning, 3D question answering, task decomposition, 3D grounding, 3D-assisted dialog, navigation, and so on. Using three types of prompting mechanisms that we design, we are able to collect over 300k 3D-language data covering these tasks. To efficiently train 3D-LLMs, we first utilize a 3D feature extractor that obtains 3D features from rendered multi- view images. Then, we use 2D VLMs as our backbones to train our 3D-LLMs. By introducing a 3D localization mechanism, 3D-LLMs can better capture 3D spatial information. Experiments on ScanQA show that our model outperforms state-of-the-art baselines by a large margin (e.g., the BLEU-1 score surpasses state-of-the-art score by 9%). Furthermore, experiments on our held-in datasets for 3D captioning, task composition, and 3D-assisted dialogue show that our model outperforms 2D VLMs. Qualitative examples also show that our model could perform more tasks beyond the scope of existing LLMs and VLMs. Project Page: : https://vis-www.cs.umass.edu/3dllm/.
Beyond RGB: Scene-Property Synthesis with Neural Radiance Fields
Jun 09, 2022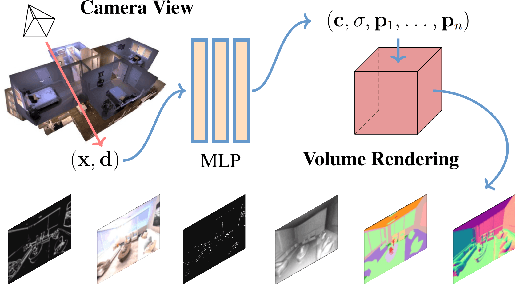
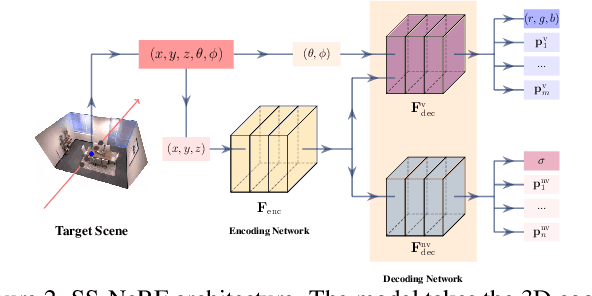

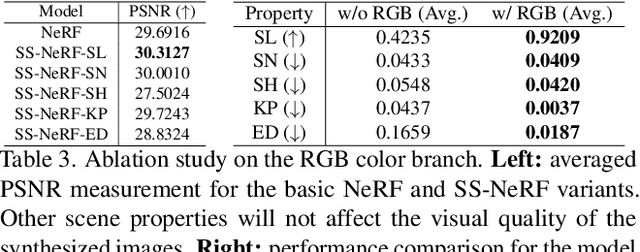
Comprehensive 3D scene understanding, both geometrically and semantically, is important for real-world applications such as robot perception. Most of the existing work has focused on developing data-driven discriminative models for scene understanding. This paper provides a new approach to scene understanding, from a synthesis model perspective, by leveraging the recent progress on implicit 3D representation and neural rendering. Building upon the great success of Neural Radiance Fields (NeRFs), we introduce Scene-Property Synthesis with NeRF (SS-NeRF) that is able to not only render photo-realistic RGB images from novel viewpoints, but also render various accurate scene properties (e.g., appearance, geometry, and semantics). By doing so, we facilitate addressing a variety of scene understanding tasks under a unified framework, including semantic segmentation, surface normal estimation, reshading, keypoint detection, and edge detection. Our SS-NeRF framework can be a powerful tool for bridging generative learning and discriminative learning, and thus be beneficial to the investigation of a wide range of interesting problems, such as studying task relationships within a synthesis paradigm, transferring knowledge to novel tasks, facilitating downstream discriminative tasks as ways of data augmentation, and serving as auto-labeller for data creation.