 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining
Jul 27, 2023
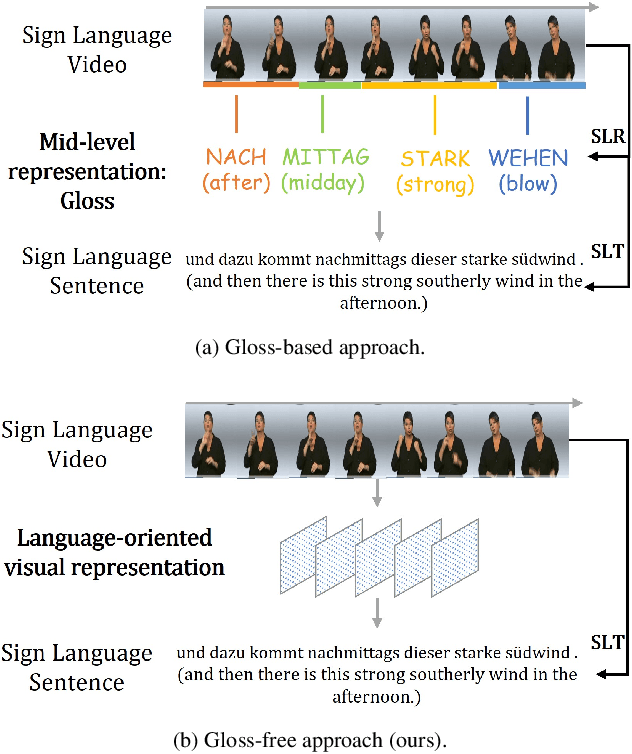
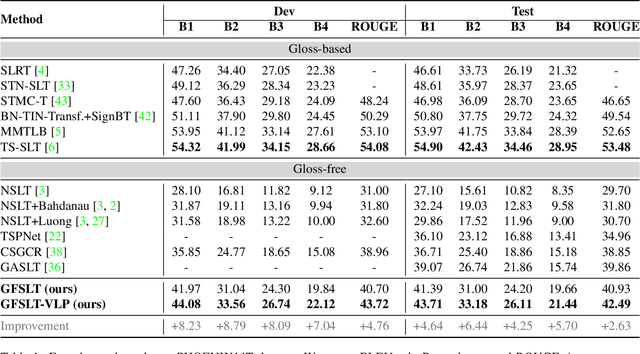
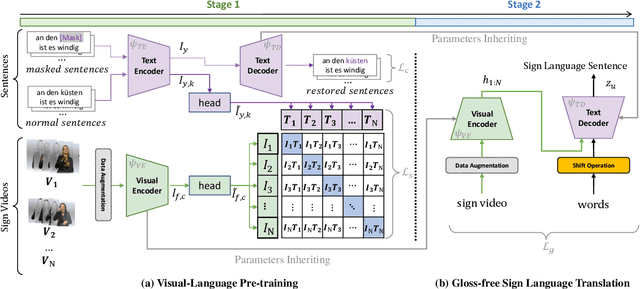
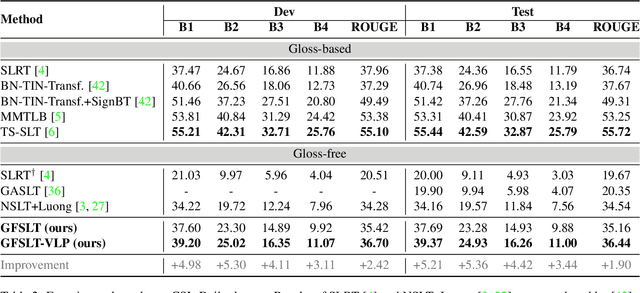
Sign Language Translation (SLT) is a challenging task due to its cross-domain nature, involving the translation of visual-gestural language to text. Many previous methods employ an intermediate representation, i.e., gloss sequences, to facilitate SLT, thus transforming it into a two-stage task of sign language recognition (SLR) followed by sign language translation (SLT). However, the scarcity of gloss-annotated sign language data, combined with the information bottleneck in the mid-level gloss representation, has hindered the further development of the SLT task. To address this challenge, we propose a novel Gloss-Free SLT based on Visual-Language Pretraining (GFSLT-VLP), which improves SLT by inheriting language-oriented prior knowledge from pre-trained models, without any gloss annotation assistance. Our approach involves two stages: (i) integrating Contrastive Language-Image Pre-training (CLIP) with masked self-supervised learning to create pre-tasks that bridge the semantic gap between visual and textual representations and restore masked sentences, and (ii) constructing an end-to-end architecture with an encoder-decoder-like structure that inherits the parameters of the pre-trained Visual Encoder and Text Decoder from the first stage. The seamless combination of these novel designs forms a robust sign language representation and significantly improves gloss-free sign language translation. In particular, we have achieved unprecedented improvements in terms of BLEU-4 score on the PHOENIX14T dataset (>+5) and the CSL-Daily dataset (>+3) compared to state-of-the-art gloss-free SLT methods. Furthermore, our approach also achieves competitive results on the PHOENIX14T dataset when compared with most of the gloss-based methods. Our code is available at https://github.com/zhoubenjia/GFSLT-VLP.
MCPA: Multi-scale Cross Perceptron Attention Network for 2D Medical Image Segmentation
Jul 27, 2023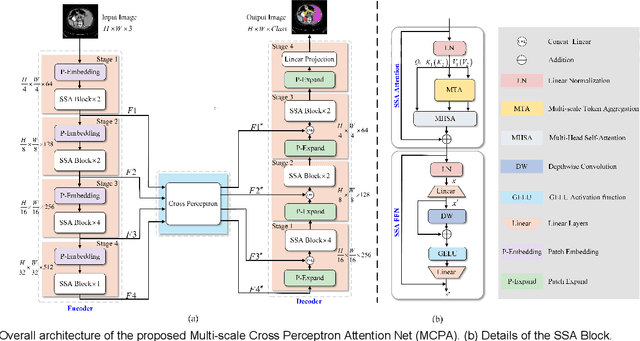
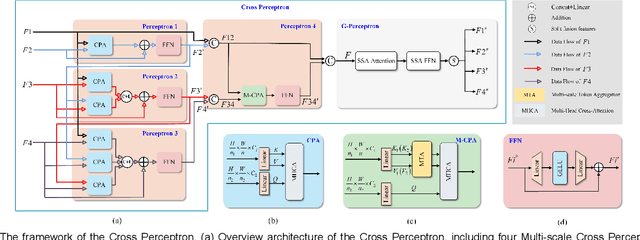
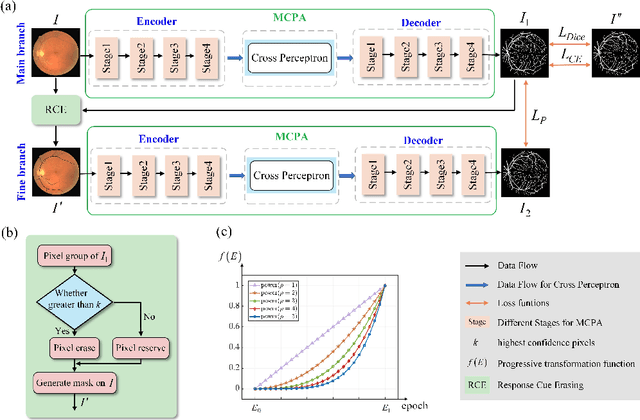
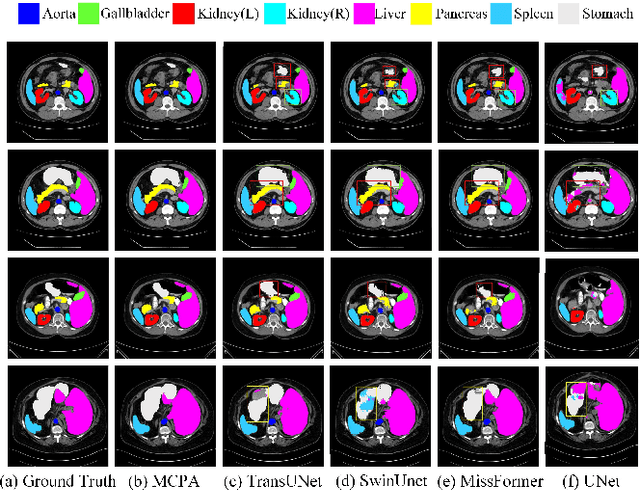
The UNet architecture, based on Convolutional Neural Networks (CNN), has demonstrated its remarkable performance in medical image analysis. However, it faces challenges in capturing long-range dependencies due to the limited receptive fields and inherent bias of convolutional operations. Recently, numerous transformer-based techniques have been incorporated into the UNet architecture to overcome this limitation by effectively capturing global feature correlations. However, the integration of the Transformer modules may result in the loss of local contextual information during the global feature fusion process. To overcome these challenges, we propose a 2D medical image segmentation model called Multi-scale Cross Perceptron Attention Network (MCPA). The MCPA consists of three main components: an encoder, a decoder, and a Cross Perceptron. The Cross Perceptron first captures the local correlations using multiple Multi-scale Cross Perceptron modules, facilitating the fusion of features across scales. The resulting multi-scale feature vectors are then spatially unfolded, concatenated, and fed through a Global Perceptron module to model global dependencies. Furthermore, we introduce a Progressive Dual-branch Structure to address the semantic segmentation of the image involving finer tissue structures. This structure gradually shifts the segmentation focus of MCPA network training from large-scale structural features to more sophisticated pixel-level features. We evaluate our proposed MCPA model on several publicly available medical image datasets from different tasks and devices, including the open large-scale dataset of CT (Synapse), MRI (ACDC), fundus camera (DRIVE, CHASE_DB1, HRF), and OCTA (ROSE). The experimental results show that our MCPA model achieves state-of-the-art performance. The code is available at https://github.com/simonustc/MCPA-for-2D-Medical-Image-Segmentation.
Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts
Jul 14, 2023
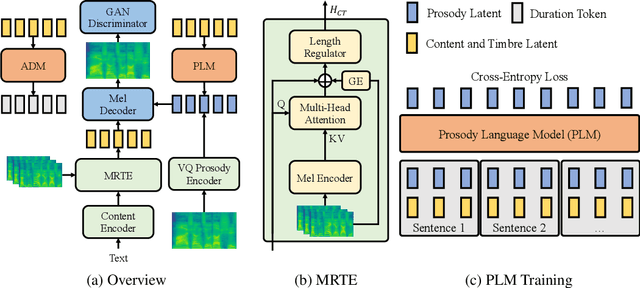
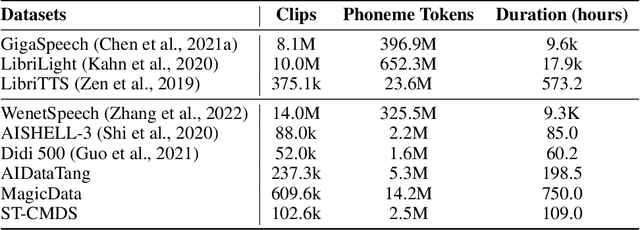
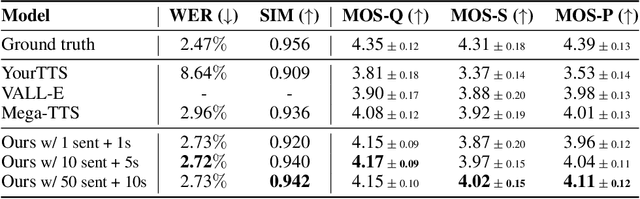
Zero-shot text-to-speech aims at synthesizing voices with unseen speech prompts. Previous large-scale multispeaker TTS models have successfully achieved this goal with an enrolled recording within 10 seconds. However, most of them are designed to utilize only short speech prompts. The limited information in short speech prompts significantly hinders the performance of fine-grained identity imitation. In this paper, we introduce Mega-TTS 2, a generic zero-shot multispeaker TTS model that is capable of synthesizing speech for unseen speakers with arbitrary-length prompts. Specifically, we 1) design a multi-reference timbre encoder to extract timbre information from multiple reference speeches; 2) and train a prosody language model with arbitrary-length speech prompts; With these designs, our model is suitable for prompts of different lengths, which extends the upper bound of speech quality for zero-shot text-to-speech. Besides arbitrary-length prompts, we introduce arbitrary-source prompts, which leverages the probabilities derived from multiple P-LLM outputs to produce expressive and controlled prosody. Furthermore, we propose a phoneme-level auto-regressive duration model to introduce in-context learning capabilities to duration modeling. Experiments demonstrate that our method could not only synthesize identity-preserving speech with a short prompt of an unseen speaker but also achieve improved performance with longer speech prompts. Audio samples can be found in https://mega-tts.github.io/mega2_demo/.
Soft-IntroVAE for Continuous Latent space Image Super-Resolution
Jul 18, 2023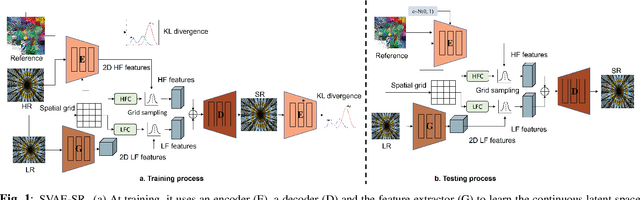
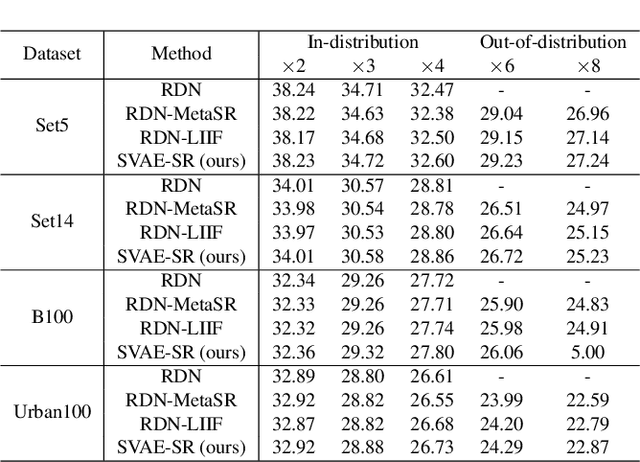
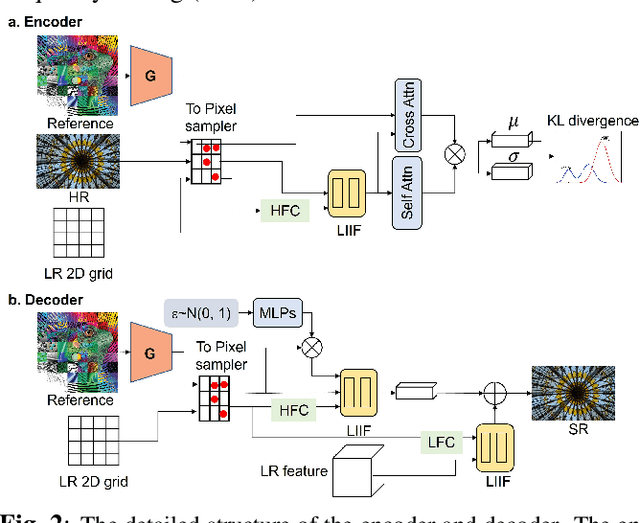
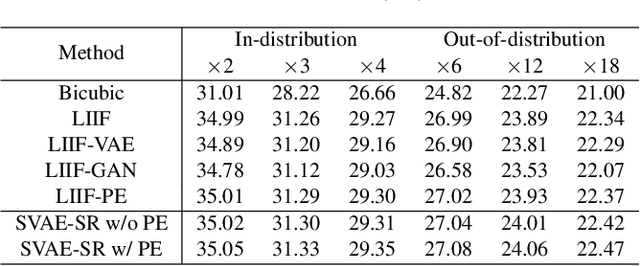
Continuous image super-resolution (SR) recently receives a lot of attention from researchers, for its practical and flexible image scaling for various displays. Local implicit image representation is one of the methods that can map the coordinates and 2D features for latent space interpolation. Inspired by Variational AutoEncoder, we propose a Soft-introVAE for continuous latent space image super-resolution (SVAE-SR). A novel latent space adversarial training is achieved for photo-realistic image restoration. To further improve the quality, a positional encoding scheme is used to extend the original pixel coordinates by aggregating frequency information over the pixel areas. We show the effectiveness of the proposed SVAE-SR through quantitative and qualitative comparisons, and further, illustrate its generalization in denoising and real-image super-resolution.
* 5 pages, 4 figures
Component-wise Power Estimation of Electrical Devices Using Thermal Imaging
Jul 18, 2023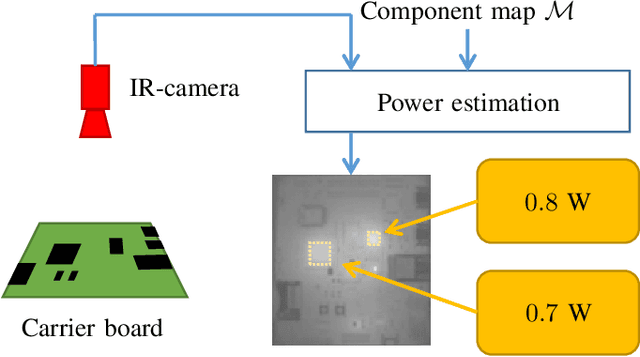
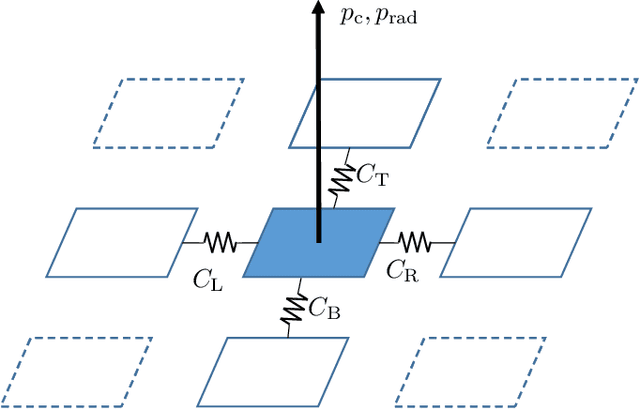
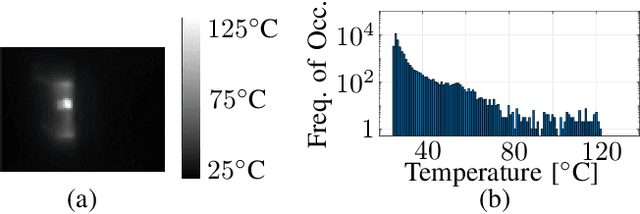
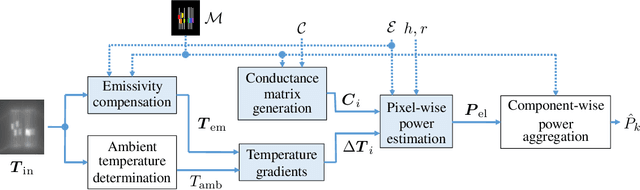
This paper presents a novel method to estimate the power consumption of distinct active components on an electronic carrier board by using thermal imaging. The components and the board can be made of heterogeneous material such as plastic, coated microchips, and metal bonds or wires, where a special coating for high emissivity is not required. The thermal images are recorded when the components on the board are dissipating power. In order to enable reliable estimates, a segmentation of the thermal image must be available that can be obtained by manual labeling, object detection methods, or exploiting layout information. Evaluations show that with low-resolution consumer infrared cameras and dissipated powers larger than 300mW, mean estimation errors of 10% can be achieved.
* 10 pages, 8 figures
On the Effectiveness of Speech Self-supervised Learning for Music
Jul 11, 2023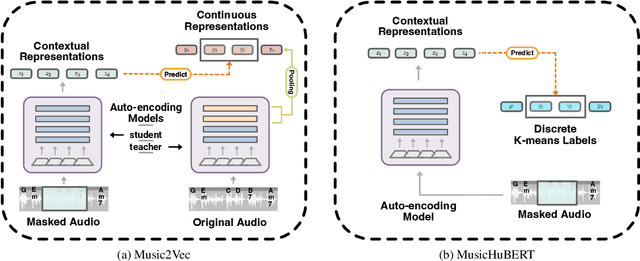
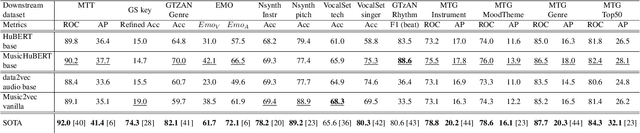

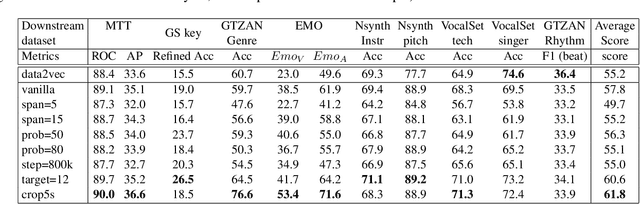
Self-supervised learning (SSL) has shown promising results in various speech and natural language processing applications. However, its efficacy in music information retrieval (MIR) still remains largely unexplored. While previous SSL models pre-trained on music recordings may have been mostly closed-sourced, recent speech models such as wav2vec2.0 have shown promise in music modelling. Nevertheless, research exploring the effectiveness of applying speech SSL models to music recordings has been limited. We explore the music adaption of SSL with two distinctive speech-related models, data2vec1.0 and Hubert, and refer to them as music2vec and musicHuBERT, respectively. We train $12$ SSL models with 95M parameters under various pre-training configurations and systematically evaluate the MIR task performances with 13 different MIR tasks. Our findings suggest that training with music data can generally improve performance on MIR tasks, even when models are trained using paradigms designed for speech. However, we identify the limitations of such existing speech-oriented designs, especially in modelling polyphonic information. Based on the experimental results, empirical suggestions are also given for designing future musical SSL strategies and paradigms.
The impact of individual information exchange strategies on the distribution of social wealth
Apr 02, 2023
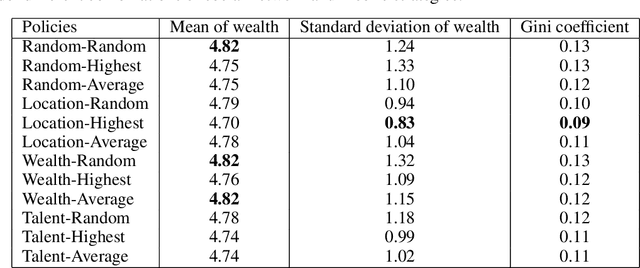
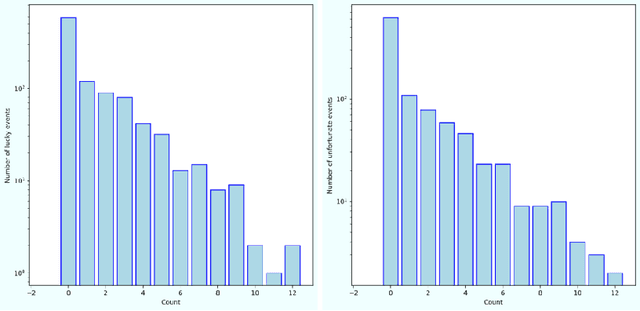
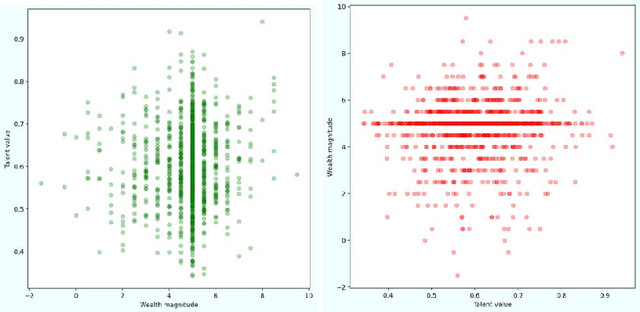
Wealth distribution is a complex and critical aspect of any society. Information exchange is considered to have played a role in shaping wealth distribution patterns, but the specific dynamic mechanism is still unclear. In this research, we used simulation-based methods to investigate the impact of different modes of information exchange on wealth distribution. We compared different combinations of information exchange strategies and moving strategies, analyzed their impact on wealth distribution using classic wealth distribution indicators such as the Gini coefficient. Our findings suggest that information exchange strategies have significant impact on wealth distribution and that promoting more equitable access to information and resources is crucial in building a just and equitable society for all.
Testing different Log Bases For Vector Model Weighting Technique
Jul 12, 2023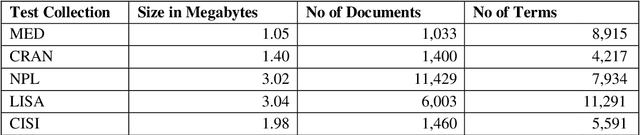
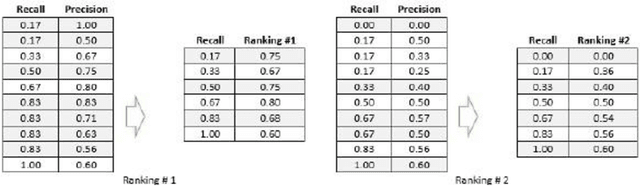
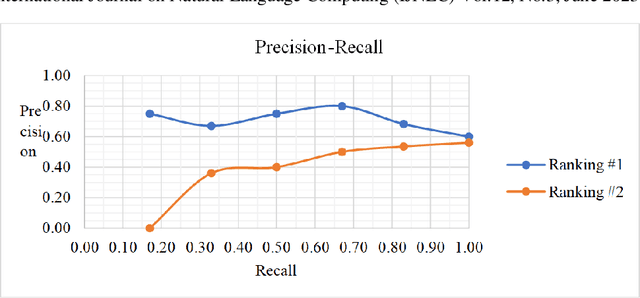
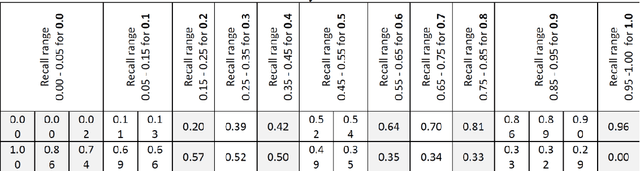
Information retrieval systems retrieves relevant documents based on a query submitted by the user. The documents are initially indexed and the words in the documents are assigned weights using a weighting technique called TFIDF which is the product of Term Frequency (TF) and Inverse Document Frequency (IDF). TF represents the number of occurrences of a term in a document. IDF measures whether the term is common or rare across all documents. It is computed by dividing the total number of documents in the system by the number of documents containing the term and then computing the logarithm of the quotient. By default, we use base 10 to calculate the logarithm. In this paper, we are going to test this weighting technique by using a range of log bases from 0.1 to 100.0 to calculate the IDF. Testing different log bases for vector model weighting technique is to highlight the importance of understanding the performance of the system at different weighting values. We use the documents of MED, CRAN, NPL, LISA, and CISI test collections that scientists assembled explicitly for experiments in data information retrieval systems.
* 15 pages, 7 figures, vector model, logarithms, tfidf
Mathematical Characterization of Signal Semantics and Rethinking of the Mathematical Theory of Information
Mar 26, 2023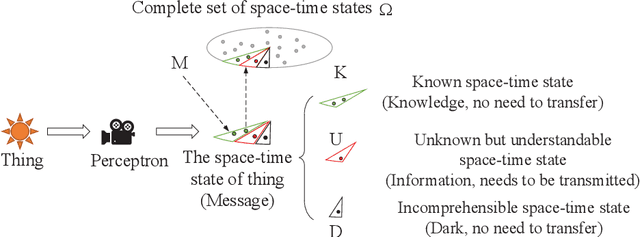
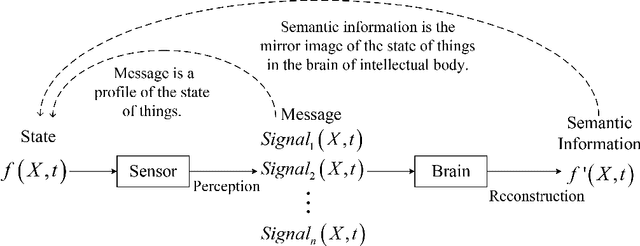
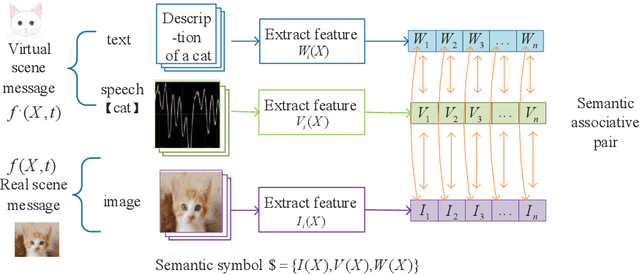
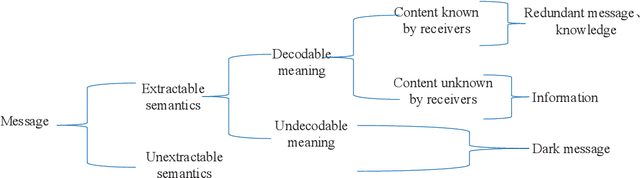
Shannon information theory is established based on probability and bits, and the communication technology based on this theory realizes the information age. The original goal of Shannon's information theory is to describe and transmit information content. However, due to information is related to cognition, and cognition is considered to be subjective, Shannon information theory is to describe and transmit information-bearing signals. With the development of the information age to the intelligent age, the traditional signal-oriented processing needs to be upgraded to content-oriented processing. For example, chat generative pre-trained transformer (ChatGPT) has initially realized the content processing capability based on massive data. For many years, researchers have been searching for the answer to what the information content in the signal is, because only when the information content is mathematically and accurately described can information-based machines be truly intelligent. This paper starts from rethinking the essence of the basic concepts of the information, such as semantics, meaning, information and knowledge, presents the mathematical characterization of the information content, investigate the relationship between them, studies the transformation from Shannon's signal information theory to semantic information theory, and therefore proposes a content-oriented semantic communication framework. Furthermore, we propose semantic decomposition and composition scheme to achieve conversion between complex and simple semantics. Finally, we verify the proposed characterization of information-related concepts by implementing evolvable knowledge-based semantic recognition.
Building and Road Segmentation Using EffUNet and Transfer Learning Approach
Jul 08, 2023In city, information about urban objects such as water supply, railway lines, power lines, buildings, roads, etc., is necessary for city planning. In particular, information about the spread of these objects, locations and capacity is needed for the policymakers to make impactful decisions. This thesis aims to segment the building and roads from the aerial image captured by the satellites and UAVs. Many different architectures have been proposed for the semantic segmentation task and UNet being one of them. In this thesis, we propose a novel architecture based on Google's newly proposed EfficientNetV2 as an encoder for feature extraction with UNet decoder for constructing the segmentation map. Using this approach we achieved a benchmark score for the Massachusetts Building and Road dataset with an mIOU of 0.8365 and 0.9153 respectively.