 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MDT3D: Multi-Dataset Training for LiDAR 3D Object Detection Generalization
Aug 02, 2023
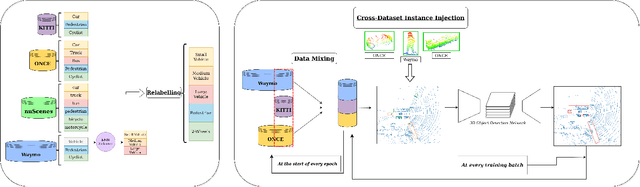
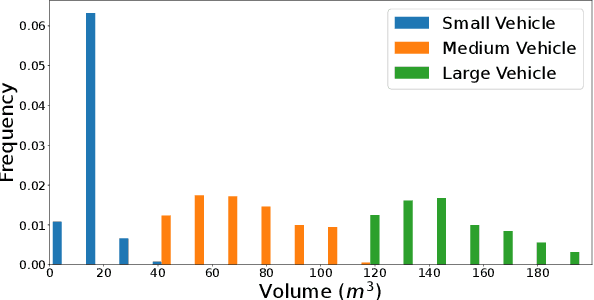


Supervised 3D Object Detection models have been displaying increasingly better performance in single-domain cases where the training data comes from the same environment and sensor as the testing data. However, in real-world scenarios data from the target domain may not be available for finetuning or for domain adaptation methods. Indeed, 3D object detection models trained on a source dataset with a specific point distribution have shown difficulties in generalizing to unseen datasets. Therefore, we decided to leverage the information available from several annotated source datasets with our Multi-Dataset Training for 3D Object Detection (MDT3D) method to increase the robustness of 3D object detection models when tested in a new environment with a different sensor configuration. To tackle the labelling gap between datasets, we used a new label mapping based on coarse labels. Furthermore, we show how we managed the mix of datasets during training and finally introduce a new cross-dataset augmentation method: cross-dataset object injection. We demonstrate that this training paradigm shows improvements for different types of 3D object detection models. The source code and additional results for this research project will be publicly available on GitHub for interested parties to access and utilize: https://github.com/LouisSF/MDT3D
More Context, Less Distraction: Visual Classification by Inferring and Conditioning on Contextual Attributes
Aug 02, 2023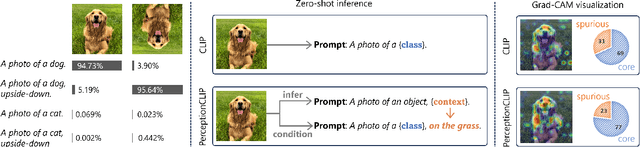

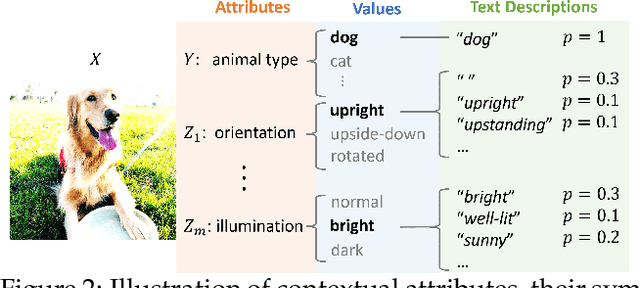
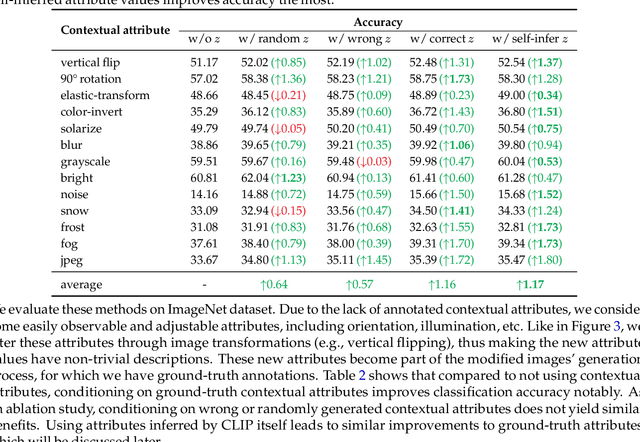
CLIP, as a foundational vision language model, is widely used in zero-shot image classification due to its ability to understand various visual concepts and natural language descriptions. However, how to fully leverage CLIP's unprecedented human-like understanding capabilities to achieve better zero-shot classification is still an open question. This paper draws inspiration from the human visual perception process: a modern neuroscience view suggests that in classifying an object, humans first infer its class-independent attributes (e.g., background and orientation) which help separate the foreground object from the background, and then make decisions based on this information. Inspired by this, we observe that providing CLIP with contextual attributes improves zero-shot classification and mitigates reliance on spurious features. We also observe that CLIP itself can reasonably infer the attributes from an image. With these observations, we propose a training-free, two-step zero-shot classification method named PerceptionCLIP. Given an image, it first infers contextual attributes (e.g., background) and then performs object classification conditioning on them. Our experiments show that PerceptionCLIP achieves better generalization, group robustness, and better interpretability. For example, PerceptionCLIP with ViT-L/14 improves the worst group accuracy by 16.5% on the Waterbirds dataset and by 3.5% on CelebA.
Push to know! -- Visuo-Tactile based Active Object Parameter Inference with Dual Differentiable Filtering
Aug 02, 2023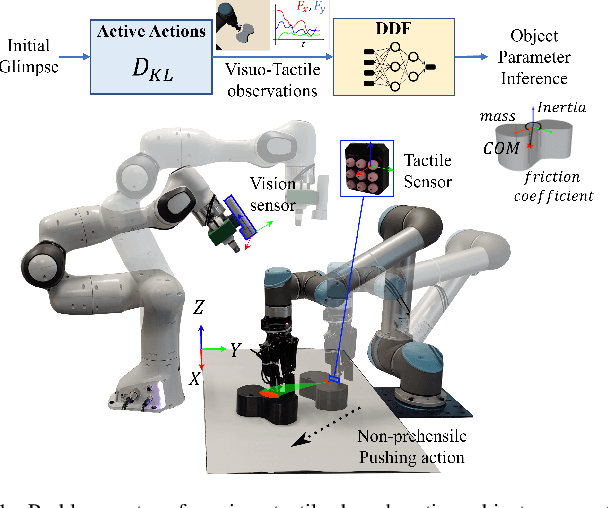
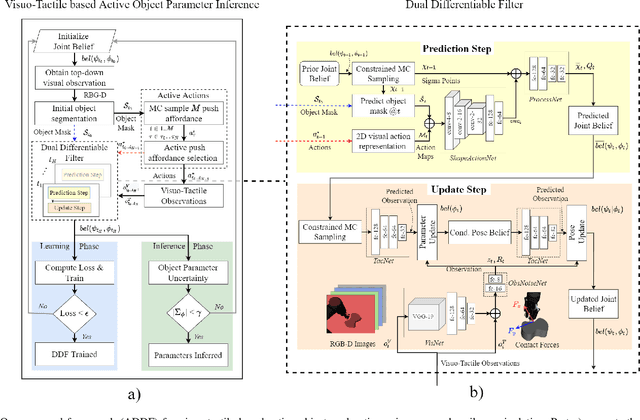
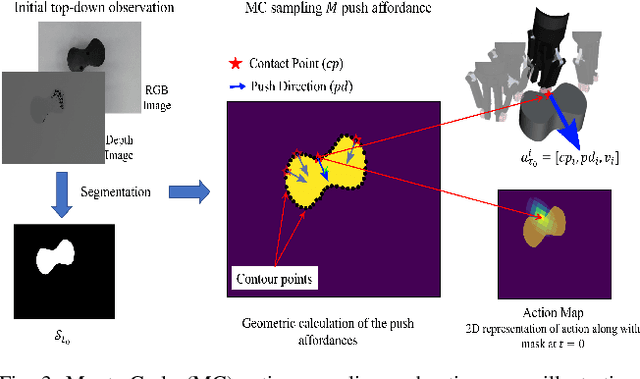
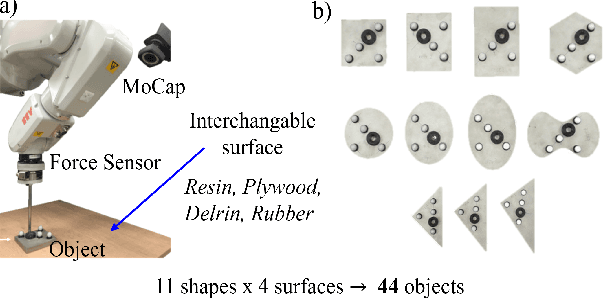
For robotic systems to interact with objects in dynamic environments, it is essential to perceive the physical properties of the objects such as shape, friction coefficient, mass, center of mass, and inertia. This not only eases selecting manipulation action but also ensures the task is performed as desired. However, estimating the physical properties of especially novel objects is a challenging problem, using either vision or tactile sensing. In this work, we propose a novel framework to estimate key object parameters using non-prehensile manipulation using vision and tactile sensing. Our proposed active dual differentiable filtering (ADDF) approach as part of our framework learns the object-robot interaction during non-prehensile object push to infer the object's parameters. Our proposed method enables the robotic system to employ vision and tactile information to interactively explore a novel object via non-prehensile object push. The novel proposed N-step active formulation within the differentiable filtering facilitates efficient learning of the object-robot interaction model and during inference by selecting the next best exploratory push actions (where to push? and how to push?). We extensively evaluated our framework in simulation and real-robotic scenarios, yielding superior performance to the state-of-the-art baseline.
Dynamic Token Pruning in Plain Vision Transformers for Semantic Segmentation
Aug 02, 2023
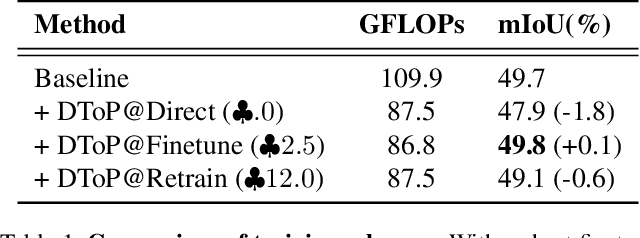
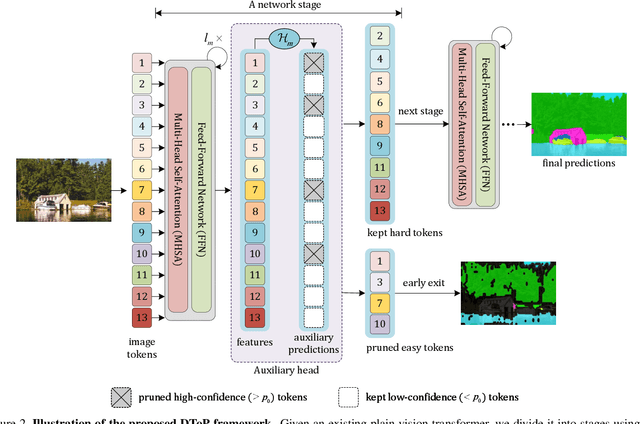
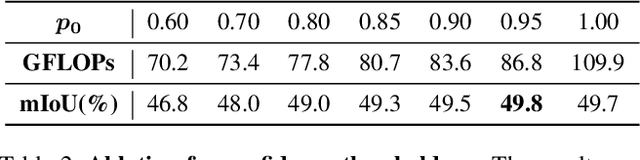
Vision transformers have achieved leading performance on various visual tasks yet still suffer from high computational complexity. The situation deteriorates in dense prediction tasks like semantic segmentation, as high-resolution inputs and outputs usually imply more tokens involved in computations. Directly removing the less attentive tokens has been discussed for the image classification task but can not be extended to semantic segmentation since a dense prediction is required for every patch. To this end, this work introduces a Dynamic Token Pruning (DToP) method based on the early exit of tokens for semantic segmentation. Motivated by the coarse-to-fine segmentation process by humans, we naturally split the widely adopted auxiliary-loss-based network architecture into several stages, where each auxiliary block grades every token's difficulty level. We can finalize the prediction of easy tokens in advance without completing the entire forward pass. Moreover, we keep $k$ highest confidence tokens for each semantic category to uphold the representative context information. Thus, computational complexity will change with the difficulty of the input, akin to the way humans do segmentation. Experiments suggest that the proposed DToP architecture reduces on average $20\% - 35\%$ of computational cost for current semantic segmentation methods based on plain vision transformers without accuracy degradation.
SubT-MRS: A Subterranean, Multi-Robot, Multi-Spectral and Multi-Degraded Dataset for Robust SLAM
Aug 02, 2023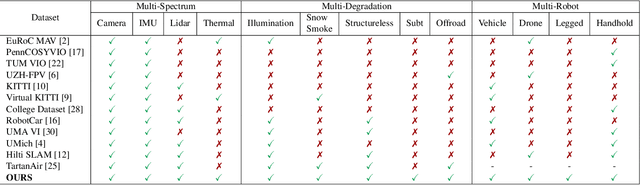

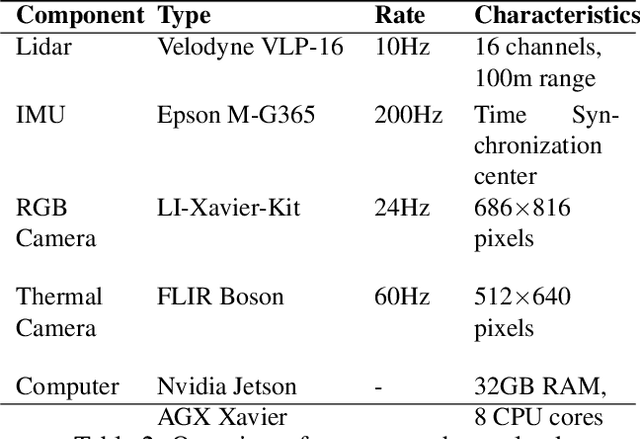

In recent years, significant progress has been made in the field of simultaneous localization and mapping (SLAM) research. However, current state-of-the-art solutions still struggle with limited accuracy and robustness in real-world applications. One major reason is the lack of datasets that fully capture the conditions faced by robots in the wild. To address this problem, we present SubT-MRS, an extremely challenging real-world dataset designed to push the limits of SLAM and perception algorithms. SubT-MRS is a multi-modal, multi-robot dataset collected mainly from subterranean environments having multi-degraded conditions including structureless corridors, varying lighting conditions, and perceptual obscurants such as smoke and dust. Furthermore, the dataset packages information from a diverse range of time-synchronized sensors, including LiDAR, visual cameras, thermal cameras, and IMUs captured using varied vehicular motions like aerial, legged, and wheeled, to support research in sensor fusion, which is essential for achieving accurate and robust robotic perception in complex environments. To evaluate the accuracy of SLAM systems, we also provide a dense 3D model with sub-centimeter-level accuracy, as well as accurate 6DoF ground truth. Our benchmarking approach includes several state-of-the-art methods to demonstrate the challenges our datasets introduce, particularly in the case of multi-degraded environments.
Machine Learning-Based Diabetes Detection Using Photoplethysmography Signal Features
Aug 02, 2023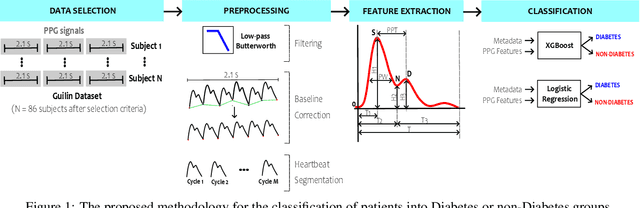

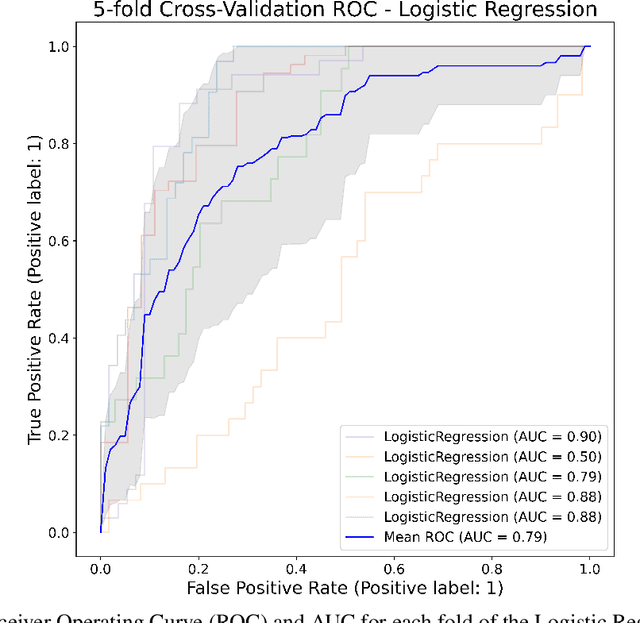

Diabetes is a prevalent chronic condition that compromises the health of millions of people worldwide. Minimally invasive methods are needed to prevent and control diabetes but most devices for measuring glucose levels are invasive and not amenable for continuous monitoring. Here, we present an alternative method to overcome these shortcomings based on non-invasive optical photoplethysmography (PPG) for detecting diabetes. We classify non-Diabetic and Diabetic patients using the PPG signal and metadata for training Logistic Regression (LR) and eXtreme Gradient Boosting (XGBoost) algorithms. We used PPG signals from a publicly available dataset. To prevent overfitting, we divided the data into five folds for cross-validation. By ensuring that patients in the training set are not in the testing set, the model's performance can be evaluated on unseen subjects' data, providing a more accurate assessment of its generalization. Our model achieved an F1-Score and AUC of $58.8\pm20.0\%$ and $79.2\pm15.0\%$ for LR and $51.7\pm16.5\%$ and $73.6\pm17.0\%$ for XGBoost, respectively. Feature analysis suggested that PPG morphological features contains diabetes-related information alongside metadata. Our findings are within the same range reported in the literature, indicating that machine learning methods are promising for developing remote, non-invasive, and continuous measurement devices for detecting and preventing diabetes.
Entropy Neural Estimation for Graph Contrastive Learning
Jul 26, 2023
Contrastive learning on graphs aims at extracting distinguishable high-level representations of nodes. In this paper, we theoretically illustrate that the entropy of a dataset can be approximated by maximizing the lower bound of the mutual information across different views of a graph, \ie, entropy is estimated by a neural network. Based on this finding, we propose a simple yet effective subset sampling strategy to contrast pairwise representations between views of a dataset. In particular, we randomly sample nodes and edges from a given graph to build the input subset for a view. Two views are fed into a parameter-shared Siamese network to extract the high-dimensional embeddings and estimate the information entropy of the entire graph. For the learning process, we propose to optimize the network using two objectives, simultaneously. Concretely, the input of the contrastive loss function consists of positive and negative pairs. Our selection strategy of pairs is different from previous works and we present a novel strategy to enhance the representation ability of the graph encoder by selecting nodes based on cross-view similarities. We enrich the diversity of the positive and negative pairs by selecting highly similar samples and totally different data with the guidance of cross-view similarity scores, respectively. We also introduce a cross-view consistency constraint on the representations generated from the different views. This objective guarantees the learned representations are consistent across views from the perspective of the entire graph. We conduct extensive experiments on seven graph benchmarks, and the proposed approach achieves competitive performance compared to the current state-of-the-art methods. The source code will be publicly released once this paper is accepted.
* ACM MM 2023 accepted
VideoPro: A Visual Analytics Approach for Interactive Video Programming
Aug 01, 2023
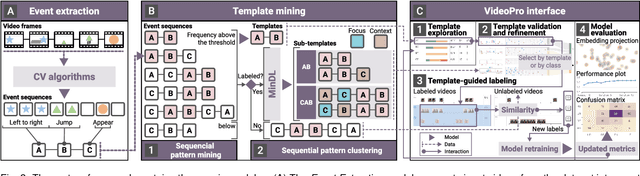
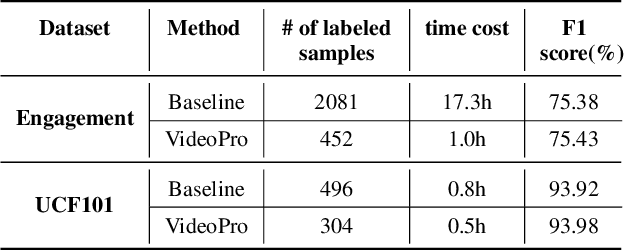

Constructing supervised machine learning models for real-world video analysis require substantial labeled data, which is costly to acquire due to scarce domain expertise and laborious manual inspection. While data programming shows promise in generating labeled data at scale with user-defined labeling functions, the high dimensional and complex temporal information in videos poses additional challenges for effectively composing and evaluating labeling functions. In this paper, we propose VideoPro, a visual analytics approach to support flexible and scalable video data programming for model steering with reduced human effort. We first extract human-understandable events from videos using computer vision techniques and treat them as atomic components of labeling functions. We further propose a two-stage template mining algorithm that characterizes the sequential patterns of these events to serve as labeling function templates for efficient data labeling. The visual interface of VideoPro facilitates multifaceted exploration, examination, and application of the labeling templates, allowing for effective programming of video data at scale. Moreover, users can monitor the impact of programming on model performance and make informed adjustments during the iterative programming process. We demonstrate the efficiency and effectiveness of our approach with two case studies and expert interviews.
PressureTransferNet: Human Attribute Guided Dynamic Ground Pressure Profile Transfer using 3D simulated Pressure Maps
Aug 01, 2023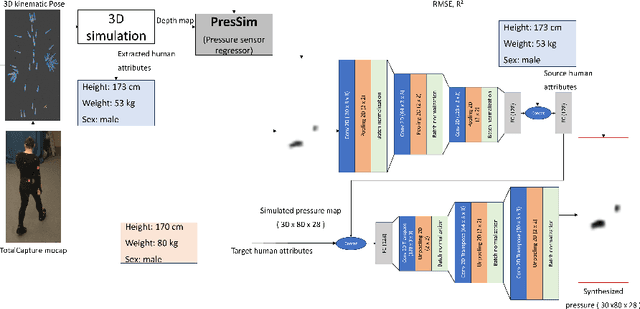
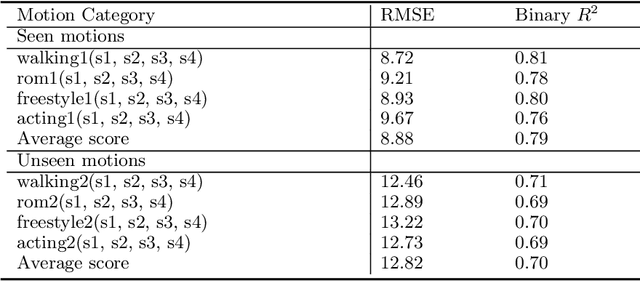

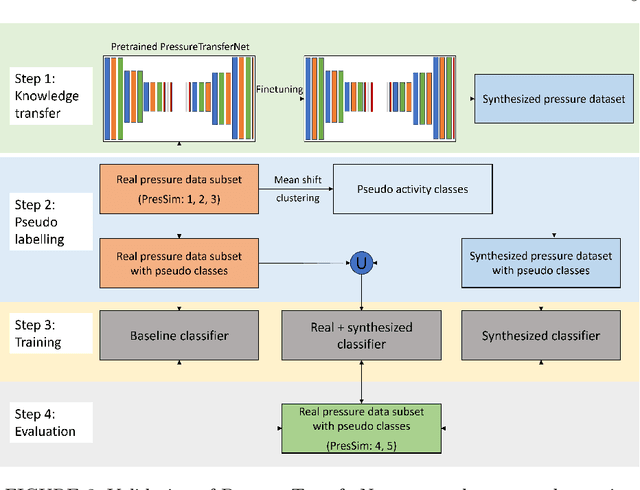
We propose PressureTransferNet, a novel method for Human Activity Recognition (HAR) using ground pressure information. Our approach generates body-specific dynamic ground pressure profiles for specific activities by leveraging existing pressure data from different individuals. PressureTransferNet is an encoder-decoder model taking a source pressure map and a target human attribute vector as inputs, producing a new pressure map reflecting the target attribute. To train the model, we use a sensor simulation to create a diverse dataset with various human attributes and pressure profiles. Evaluation on a real-world dataset shows its effectiveness in accurately transferring human attributes to ground pressure profiles across different scenarios. We visually confirm the fidelity of the synthesized pressure shapes using a physics-based deep learning model and achieve a binary R-square value of 0.79 on areas with ground contact. Validation through classification with F1 score (0.911$\pm$0.015) on physical pressure mat data demonstrates the correctness of the synthesized pressure maps, making our method valuable for data augmentation, denoising, sensor simulation, and anomaly detection. Applications span sports science, rehabilitation, and bio-mechanics, contributing to the development of HAR systems.
A Novel Temporal Multi-Gate Mixture-of-Experts Approach for Vehicle Trajectory and Driving Intention Prediction
Aug 01, 2023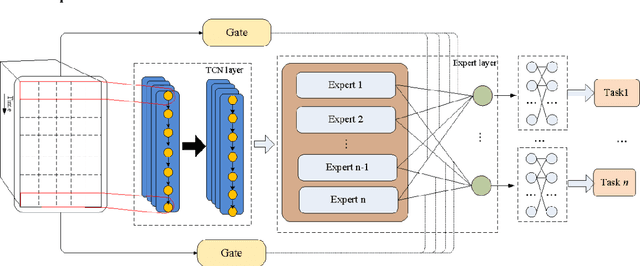
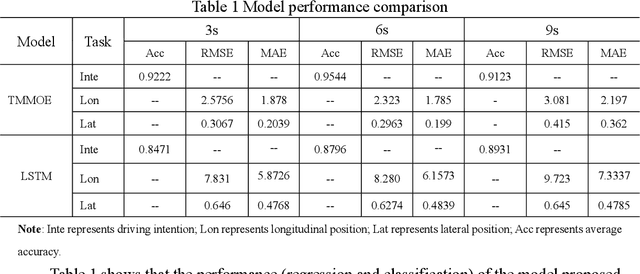
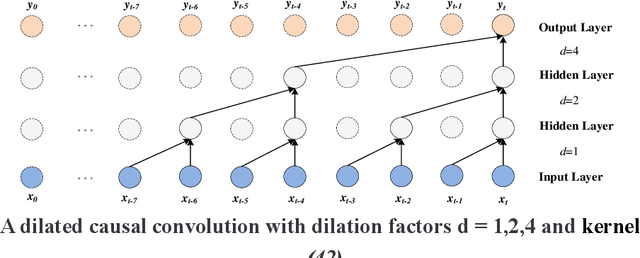
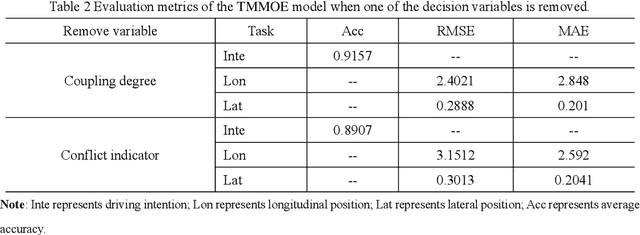
Accurate Vehicle Trajectory Prediction is critical for automated vehicles and advanced driver assistance systems. Vehicle trajectory prediction consists of two essential tasks, i.e., longitudinal position prediction and lateral position prediction. There is a significant correlation between driving intentions and vehicle motion. In existing work, the three tasks are often conducted separately without considering the relationships between the longitudinal position, lateral position, and driving intention. In this paper, we propose a novel Temporal Multi-Gate Mixture-of-Experts (TMMOE) model for simultaneously predicting the vehicle trajectory and driving intention. The proposed model consists of three layers: a shared layer, an expert layer, and a fully connected layer. In the model, the shared layer utilizes Temporal Convolutional Networks (TCN) to extract temporal features. Then the expert layer is built to identify different information according to the three tasks. Moreover, the fully connected layer is used to integrate and export prediction results. To achieve better performance, uncertainty algorithm is used to construct the multi-task loss function. Finally, the publicly available CitySim dataset validates the TMMOE model, demonstrating superior performance compared to the LSTM model, achieving the highest classification and regression results. Keywords: Vehicle trajectory prediction, driving intentions Classification, Multi-task