 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Visuo-Tactile Object Perception
Apr 02, 2026Estimating physical properties is critical for safe and efficient autonomous robotic manipulation, particularly during contact-rich interactions. In such settings, vision and tactile sensing provide complementary information about object geometry, pose, inertia, stiffness, and contact dynamics, such as stick-slip behavior. However, these properties are only indirectly observable and cannot always be modeled precisely (e.g., deformation in non-rigid objects coupled with nonlinear contact friction), making the estimation problem inherently complex and requiring sustained exploitation of visuo-tactile sensory information during action. Existing visuo-tactile perception frameworks have primarily emphasized forceful sensor fusion or static cross-modal alignment, with limited consideration of how uncertainty and beliefs about object properties evolve over time. Inspired by human multi-sensory perception and active inference, we propose the Cross-Modal Latent Filter (CMLF) to learn a structured, causal latent state-space of physical object properties. CMLF supports bidirectional transfer of cross-modal priors between vision and touch and integrates sensory evidence through a Bayesian inference process that evolves over time. Real-world robotic experiments demonstrate that CMLF improves the efficiency and robustness of latent physical properties estimation under uncertainty compared to baseline approaches. Beyond performance gains, the model exhibits perceptual coupling phenomena analogous to those observed in humans, including susceptibility to cross-modal illusions and similar trajectories in learning cross-sensory associations. Together, these results constitutes a significant step toward generalizable, robust and physically consistent cross-modal integration for robotic multi-sensory perception.
ArtReg: Visuo-Tactile based Pose Tracking and Manipulation of Unseen Articulated Objects
Nov 09, 2025



Robots operating in real-world environments frequently encounter unknown objects with complex structures and articulated components, such as doors, drawers, cabinets, and tools. The ability to perceive, track, and manipulate these objects without prior knowledge of their geometry or kinematic properties remains a fundamental challenge in robotics. In this work, we present a novel method for visuo-tactile-based tracking of unseen objects (single, multiple, or articulated) during robotic interaction without assuming any prior knowledge regarding object shape or dynamics. Our novel pose tracking approach termed ArtReg (stands for Articulated Registration) integrates visuo-tactile point clouds in an unscented Kalman Filter formulation in the SE(3) Lie Group for point cloud registration. ArtReg is used to detect possible articulated joints in objects using purposeful manipulation maneuvers such as pushing or hold-pulling with a two-robot team. Furthermore, we leverage ArtReg to develop a closed-loop controller for goal-driven manipulation of articulated objects to move the object into the desired pose configuration. We have extensively evaluated our approach on various types of unknown objects through real robot experiments. We also demonstrate the robustness of our method by evaluating objects with varying center of mass, low-light conditions, and with challenging visual backgrounds. Furthermore, we benchmarked our approach on a standard dataset of articulated objects and demonstrated improved performance in terms of pose accuracy compared to state-of-the-art methods. Our experiments indicate that robust and accurate pose tracking leveraging visuo-tactile information enables robots to perceive and interact with unseen complex articulated objects (with revolute or prismatic joints).
Edge Training and Inference with Analog ReRAM Technology for Hand Gesture Recognition
Feb 25, 2025


Tactile hand gesture recognition is a crucial task for user control in the automotive sector, where Human-Machine Interactions (HMI) demand low latency and high energy efficiency. This study addresses the challenges of power-constrained edge training and inference by utilizing analog Resistive Random Access Memory (ReRAM) technology in conjunction with a real tactile hand gesture dataset. By optimizing the input space through a feature engineering strategy, we avoid relying on large-scale crossbar arrays, making the system more suitable for edge deployment. Through realistic hardware-aware simulations that account for device non-idealities derived from experimental data, we demonstrate the functionalities of our analog ReRAM-based analog in-memory computing for on-chip training, utilizing the state-of-the-art Tiki-Taka algorithm. Furthermore, we validate the classification accuracy of approximately 91.4% for post-deployment inference of hand gestures. The results highlight the potential of analog ReRAM technology and crossbar architecture with fully parallelized matrix computations for real-time HMI systems at the Edge.
Predictive Visuo-Tactile Interactive Perception Framework for Object Properties Inference
Nov 13, 2024Interactive exploration of the unknown physical properties of objects such as stiffness, mass, center of mass, friction coefficient, and shape is crucial for autonomous robotic systems operating continuously in unstructured environments. Precise identification of these properties is essential to manipulate objects in a stable and controlled way, and is also required to anticipate the outcomes of (prehensile or non-prehensile) manipulation actions such as pushing, pulling, lifting, etc. Our study focuses on autonomously inferring the physical properties of a diverse set of various homogeneous, heterogeneous, and articulated objects utilizing a robotic system equipped with vision and tactile sensors. We propose a novel predictive perception framework for identifying object properties of the diverse objects by leveraging versatile exploratory actions: non-prehensile pushing and prehensile pulling. As part of the framework, we propose a novel active shape perception to seamlessly initiate exploration. Our innovative dual differentiable filtering with Graph Neural Networks learns the object-robot interaction and performs consistent inference of indirectly observable time-invariant object properties. In addition, we formulate a $N$-step information gain approach to actively select the most informative actions for efficient learning and inference. Extensive real-robot experiments with planar objects show that our predictive perception framework results in better performance than the state-of-the-art baseline and demonstrate our framework in three major applications for i) object tracking, ii) goal-driven task, and iii) change in environment detection.
Advancements in Tactile Hand Gesture Recognition for Enhanced Human-Machine Interaction
May 27, 2024



Motivated by the growing interest in enhancing intuitive physical Human-Machine Interaction (HRI/HVI), this study aims to propose a robust tactile hand gesture recognition system. We performed a comprehensive evaluation of different hand gesture recognition approaches for a large area tactile sensing interface (touch interface) constructed from conductive textiles. Our evaluation encompassed traditional feature engineering methods, as well as contemporary deep learning techniques capable of real-time interpretation of a range of hand gestures, accommodating variations in hand sizes, movement velocities, applied pressure levels, and interaction points. Our extensive analysis of the various methods makes a significant contribution to tactile-based gesture recognition in the field of human-machine interaction.
Visuo-Tactile based Predictive Cross Modal Perception for Object Exploration in Robotics
May 23, 2024Autonomously exploring the unknown physical properties of novel objects such as stiffness, mass, center of mass, friction coefficient, and shape is crucial for autonomous robotic systems operating continuously in unstructured environments. We introduce a novel visuo-tactile based predictive cross-modal perception framework where initial visual observations (shape) aid in obtaining an initial prior over the object properties (mass). The initial prior improves the efficiency of the object property estimation, which is autonomously inferred via interactive non-prehensile pushing and using a dual filtering approach. The inferred properties are then used to enhance the predictive capability of the cross-modal function efficiently by using a human-inspired `surprise' formulation. We evaluated our proposed framework in the real-robotic scenario, demonstrating superior performance.
Push to know! -- Visuo-Tactile based Active Object Parameter Inference with Dual Differentiable Filtering
Aug 02, 2023



For robotic systems to interact with objects in dynamic environments, it is essential to perceive the physical properties of the objects such as shape, friction coefficient, mass, center of mass, and inertia. This not only eases selecting manipulation action but also ensures the task is performed as desired. However, estimating the physical properties of especially novel objects is a challenging problem, using either vision or tactile sensing. In this work, we propose a novel framework to estimate key object parameters using non-prehensile manipulation using vision and tactile sensing. Our proposed active dual differentiable filtering (ADDF) approach as part of our framework learns the object-robot interaction during non-prehensile object push to infer the object's parameters. Our proposed method enables the robotic system to employ vision and tactile information to interactively explore a novel object via non-prehensile object push. The novel proposed N-step active formulation within the differentiable filtering facilitates efficient learning of the object-robot interaction model and during inference by selecting the next best exploratory push actions (where to push? and how to push?). We extensively evaluated our framework in simulation and real-robotic scenarios, yielding superior performance to the state-of-the-art baseline.
Touch if it's transparent! ACTOR: Active Tactile-based Category-Level Transparent Object Reconstruction
Jul 30, 2023



Accurate shape reconstruction of transparent objects is a challenging task due to their non-Lambertian surfaces and yet necessary for robots for accurate pose perception and safe manipulation. As vision-based sensing can produce erroneous measurements for transparent objects, the tactile modality is not sensitive to object transparency and can be used for reconstructing the object's shape. We propose ACTOR, a novel framework for ACtive tactile-based category-level Transparent Object Reconstruction. ACTOR leverages large datasets of synthetic object with our proposed self-supervised learning approach for object shape reconstruction as the collection of real-world tactile data is prohibitively expensive. ACTOR can be used during inference with tactile data from category-level unknown transparent objects for reconstruction. Furthermore, we propose an active-tactile object exploration strategy as probing every part of the object surface can be sample inefficient. We also demonstrate tactile-based category-level object pose estimation task using ACTOR. We perform an extensive evaluation of our proposed methodology with real-world robotic experiments with comprehensive comparison studies with state-of-the-art approaches. Our proposed method outperforms these approaches in terms of tactile-based object reconstruction and object pose estimation.
GMCR: Graph-based Maximum Consensus Estimation for Point Cloud Registration
Mar 07, 2023



Point cloud registration is a fundamental and challenging problem for autonomous robots interacting in unstructured environments for applications such as object pose estimation, simultaneous localization and mapping, robot-sensor calibration, and so on. In global correspondence-based point cloud registration, data association is a highly brittle task and commonly produces high amounts of outliers. Failure to reject outliers can lead to errors propagating to downstream perception tasks. Maximum Consensus (MC) is a widely used technique for robust estimation, which is however known to be NP-hard. Exact methods struggle to scale to realistic problem instances, whereas high outlier rates are challenging for approximate methods. To this end, we propose Graph-based Maximum Consensus Registration (GMCR), which is highly robust to outliers and scales to realistic problem instances. We propose novel consensus functions to map the decoupled MC-objective to the graph domain, wherein we find a tight approximation to the maximum consensus set as the maximum clique. The final pose estimate is given in closed-form. We extensively evaluated our proposed GMCR on a synthetic registration benchmark, robotic object localization task, and additionally on a scan matching benchmark. Our proposed method shows high accuracy and time efficiency compared to other state-of-the-art MC methods and compares favorably to other robust registration methods.
An Empirical Evaluation of Various Information Gain Criteria for Active Tactile Action Selection for Pose Estimation
May 10, 2022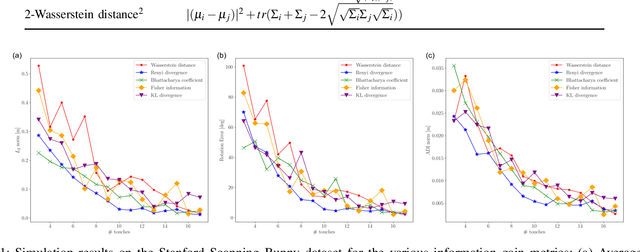
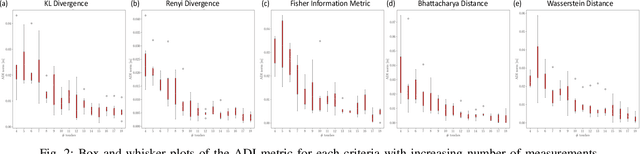
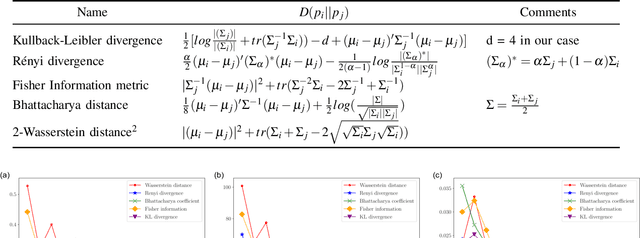
Accurate object pose estimation using multi-modal perception such as visual and tactile sensing have been used for autonomous robotic manipulators in literature. Due to variation in density of visual and tactile data, we previously proposed a novel probabilistic Bayesian filter-based approach termed translation-invariant Quaternion filter (TIQF) for pose estimation. As tactile data collection is time consuming, active tactile data collection is preferred by reasoning over multiple potential actions for maximal expected information gain. In this paper, we empirically evaluate various information gain criteria for action selection in the context of object pose estimation. We demonstrate the adaptability and effectiveness of our proposed TIQF pose estimation approach with various information gain criteria. We find similar performance in terms of pose accuracy with sparse measurements across all the selected criteria.