 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Zero-Resource Hallucination Prevention for Large Language Models
Sep 06, 2023

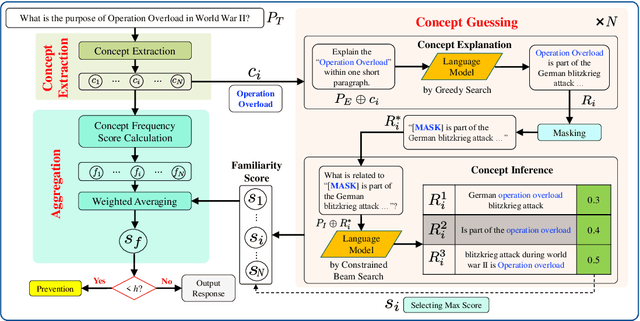

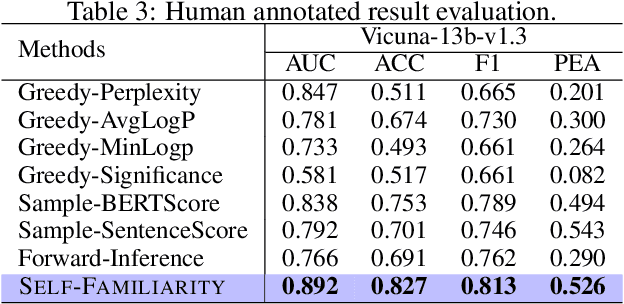
The prevalent use of large language models (LLMs) in various domains has drawn attention to the issue of "hallucination," which refers to instances where LLMs generate factually inaccurate or ungrounded information. Existing techniques for hallucination detection in language assistants rely on intricate fuzzy, specific free-language-based chain of thought (CoT) techniques or parameter-based methods that suffer from interpretability issues. Additionally, the methods that identify hallucinations post-generation could not prevent their occurrence and suffer from inconsistent performance due to the influence of the instruction format and model style. In this paper, we introduce a novel pre-detection self-evaluation technique, referred to as {\method}, which focuses on evaluating the model's familiarity with the concepts present in the input instruction and withholding the generation of response in case of unfamiliar concepts. This approach emulates the human ability to refrain from responding to unfamiliar topics, thus reducing hallucinations. We validate {\method} across four different large language models, demonstrating consistently superior performance compared to existing techniques. Our findings propose a significant shift towards preemptive strategies for hallucination mitigation in LLM assistants, promising improvements in reliability, applicability, and interpretability.
MEGANet: Multi-Scale Edge-Guided Attention Network for Weak Boundary Polyp Segmentation
Sep 06, 2023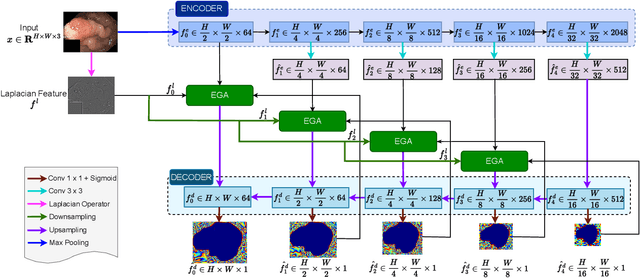
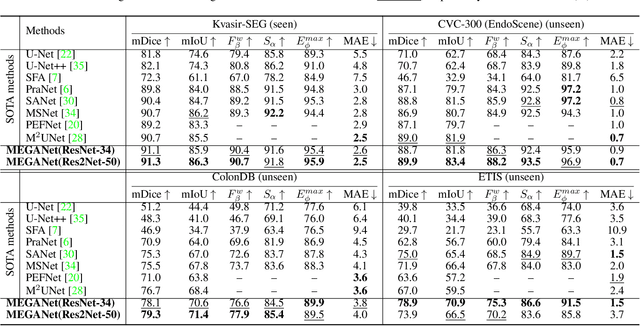
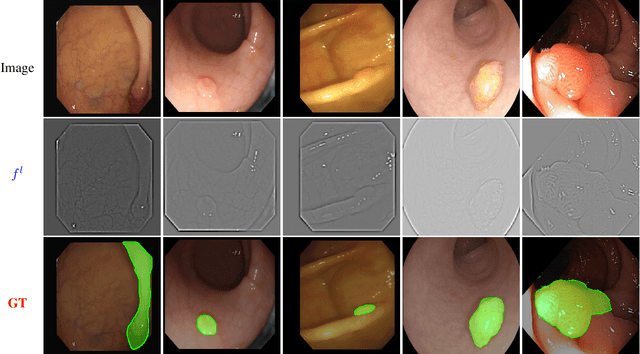
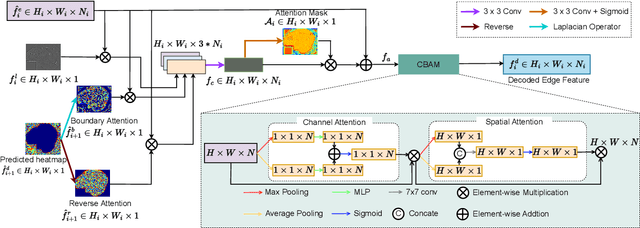
Efficient polyp segmentation in healthcare plays a critical role in enabling early diagnosis of colorectal cancer. However, the segmentation of polyps presents numerous challenges, including the intricate distribution of backgrounds, variations in polyp sizes and shapes, and indistinct boundaries. Defining the boundary between the foreground (i.e. polyp itself) and the background (surrounding tissue) is difficult. To mitigate these challenges, we propose Multi-Scale Edge-Guided Attention Network (MEGANet) tailored specifically for polyp segmentation within colonoscopy images. This network draws inspiration from the fusion of a classical edge detection technique with an attention mechanism. By combining these techniques, MEGANet effectively preserves high-frequency information, notably edges and boundaries, which tend to erode as neural networks deepen. MEGANet is designed as an end-to-end framework, encompassing three key modules: an encoder, which is responsible for capturing and abstracting the features from the input image, a decoder, which focuses on salient features, and the Edge-Guided Attention module (EGA) that employs the Laplacian Operator to accentuate polyp boundaries. Extensive experiments, both qualitative and quantitative, on five benchmark datasets, demonstrate that our EGANet outperforms other existing SOTA methods under six evaluation metrics. Our code is available at \url{https://github.com/DinhHieuHoang/MEGANet}
Resilient source seeking with robot swarms
Sep 06, 2023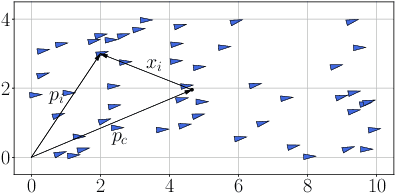
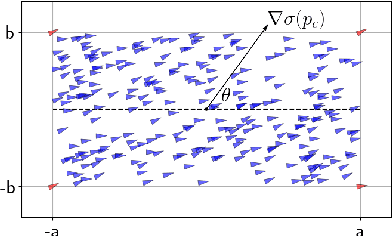
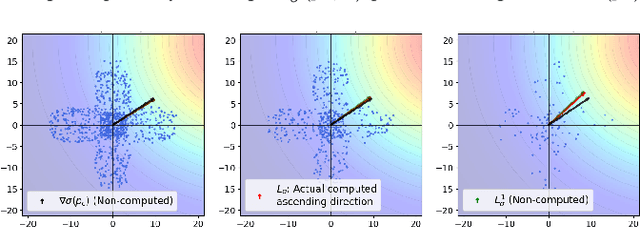
We present a solution for locating the source, or maximum, of an unknown scalar field using a swarm of mobile robots. Unlike relying on the traditional gradient information, the swarm determines an ascending direction to approach the source with arbitrary precision. The ascending direction is calculated from measurements of the field strength at the robot locations and their relative positions concerning the centroid. Rather than focusing on individual robots, we focus the analysis on the density of robots per unit area to guarantee a more resilient swarm, i.e., the functionality remains even if individuals go missing or are misplaced during the mission. We reinforce the robustness of the algorithm by providing sufficient conditions for the swarm shape so that the ascending direction is almost parallel to the gradient. The swarm can respond to an unexpected environment by morphing its shape and exploiting the existence of multiple ascending directions. Finally, we validate our approach numerically with hundreds of robots. The fact that a large number of robots always calculate an ascending direction compensates for the loss of individuals and mitigates issues arising from the actuator and sensor noises.
MAD: Modality Agnostic Distance Measure for Image Registration
Sep 06, 2023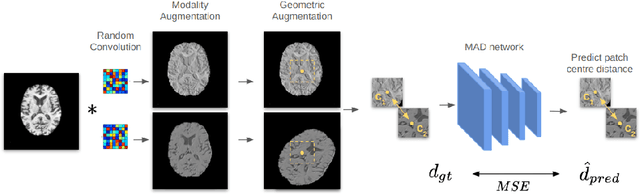
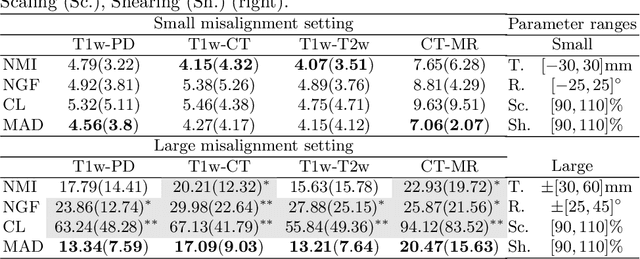
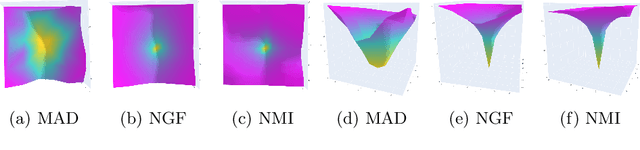

Multi-modal image registration is a crucial pre-processing step in many medical applications. However, it is a challenging task due to the complex intensity relationships between different imaging modalities, which can result in large discrepancy in image appearance. The success of multi-modal image registration, whether it is conventional or learning based, is predicated upon the choice of an appropriate distance (or similarity) measure. Particularly, deep learning registration algorithms lack in accuracy or even fail completely when attempting to register data from an "unseen" modality. In this work, we present Modality Agnostic Distance (MAD), a deep image distance}] measure that utilises random convolutions to learn the inherent geometry of the images while being robust to large appearance changes. Random convolutions are geometry-preserving modules which we use to simulate an infinite number of synthetic modalities alleviating the need for aligned paired data during training. We can therefore train MAD on a mono-modal dataset and successfully apply it to a multi-modal dataset. We demonstrate that not only can MAD affinely register multi-modal images successfully, but it has also a larger capture range than traditional measures such as Mutual Information and Normalised Gradient Fields.
Knowledge Distillation Layer that Lets the Student Decide
Sep 06, 2023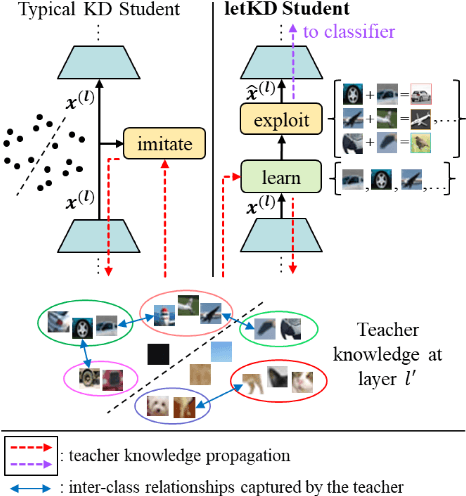
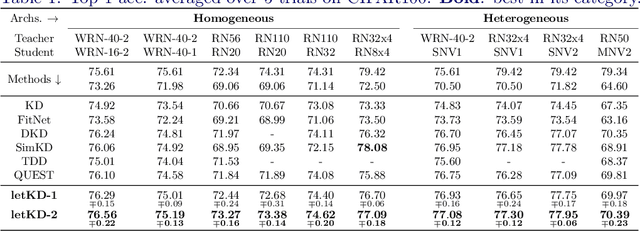
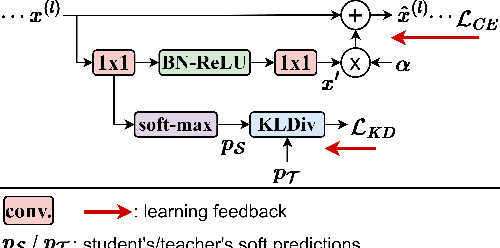
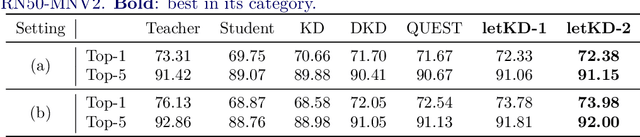
Typical technique in knowledge distillation (KD) is regularizing the learning of a limited capacity model (student) by pushing its responses to match a powerful model's (teacher). Albeit useful especially in the penultimate layer and beyond, its action on student's feature transform is rather implicit, limiting its practice in the intermediate layers. To explicitly embed the teacher's knowledge in feature transform, we propose a learnable KD layer for the student which improves KD with two distinct abilities: i) learning how to leverage the teacher's knowledge, enabling to discard nuisance information, and ii) feeding forward the transferred knowledge deeper. Thus, the student enjoys the teacher's knowledge during the inference besides training. Formally, we repurpose 1x1-BN-ReLU-1x1 convolution block to assign a semantic vector to each local region according to the template (supervised by the teacher) that the corresponding region of the student matches. To facilitate template learning in the intermediate layers, we propose a novel form of supervision based on the teacher's decisions. Through rigorous experimentation, we demonstrate the effectiveness of our approach on 3 popular classification benchmarks. Code is available at: https://github.com/adagorgun/letKD-framework
NF4 Isn't Information Theoretically Optimal (and that's Good)
Jun 14, 2023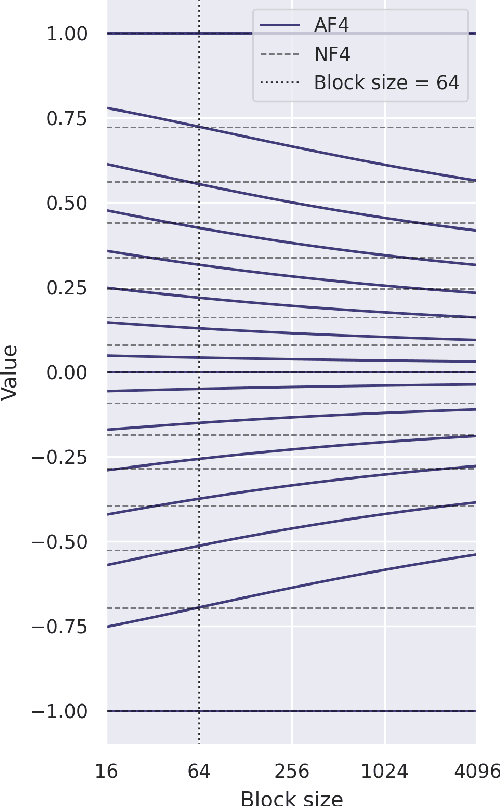
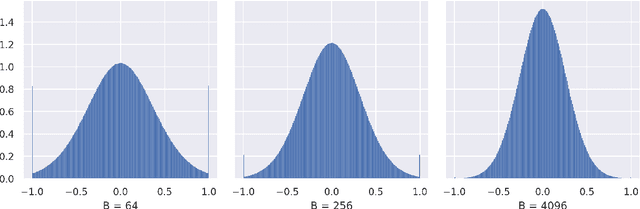
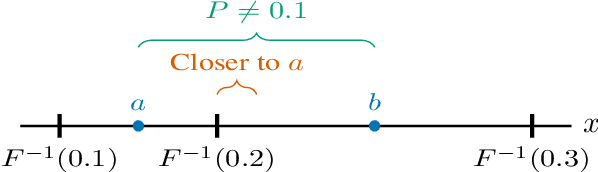
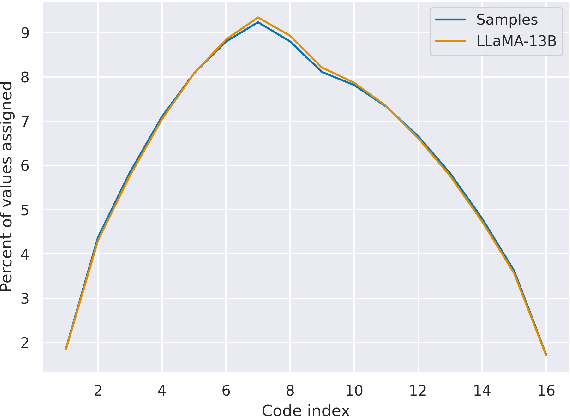
This note shares some simple calculations and experiments related to absmax-based blockwise quantization, as used in Dettmers et al., 2023. Their proposed NF4 data type is said to be information theoretically optimal for representing normally distributed weights. I show that this can't quite be the case, as the distribution of the values to be quantized depends on the block-size. I attempt to apply these insights to derive an improved code based on minimizing the expected L1 reconstruction error, rather than the quantile based method. This leads to improved performance for larger quantization block sizes, while both codes perform similarly at smaller block sizes.
Multi-pass Training and Cross-information Fusion for Low-resource End-to-end Accented Speech Recognition
Jun 20, 2023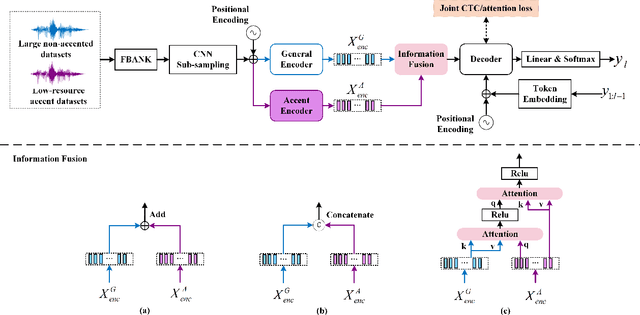
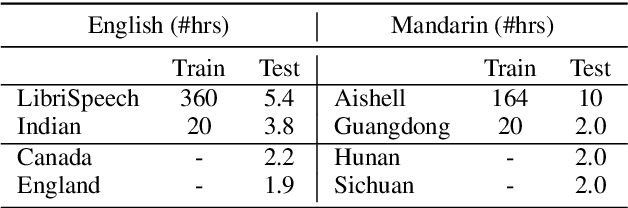

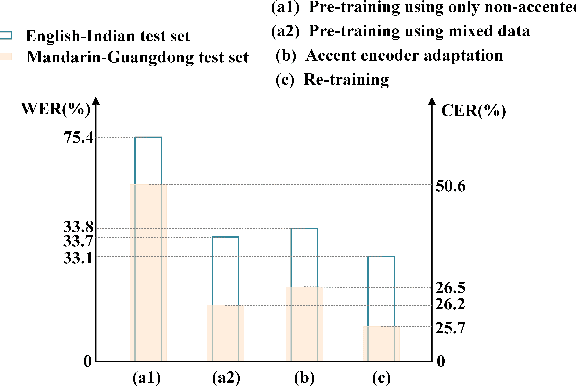
Low-resource accented speech recognition is one of the important challenges faced by current ASR technology in practical applications. In this study, we propose a Conformer-based architecture, called Aformer, to leverage both the acoustic information from large non-accented and limited accented training data. Specifically, a general encoder and an accent encoder are designed in the Aformer to extract complementary acoustic information. Moreover, we propose to train the Aformer in a multi-pass manner, and investigate three cross-information fusion methods to effectively combine the information from both general and accent encoders. All experiments are conducted on both the accented English and Mandarin ASR tasks. Results show that our proposed methods outperform the strong Conformer baseline by relative 10.2% to 24.5% word/character error rate reduction on six in-domain and out-of-domain accented test sets.
C-PMI: Conditional Pointwise Mutual Information for Turn-level Dialogue Evaluation
Jun 27, 2023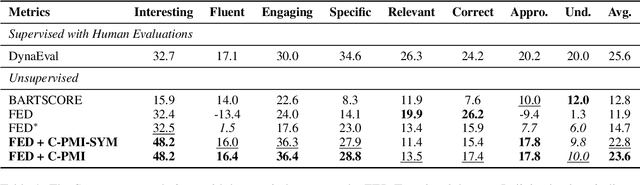
Existing reference-free turn-level evaluation metrics for chatbots inadequately capture the interaction between the user and the system. Consequently, they often correlate poorly with human evaluations. To address this issue, we propose a novel model-agnostic approach that leverages Conditional Pointwise Mutual Information (C-PMI) to measure the turn-level interaction between the system and the user based on a given evaluation dimension. Experimental results on the widely used FED dialogue evaluation dataset demonstrate that our approach significantly improves the correlation with human judgment compared with existing evaluation systems. By replacing the negative log-likelihood-based scorer with our proposed C-PMI scorer, we achieve a relative 60.5% higher Spearman correlation on average for the FED evaluation metric. Our code is publicly available at https://github.com/renll/C-PMI.
Object-Centric Multiple Object Tracking
Sep 05, 2023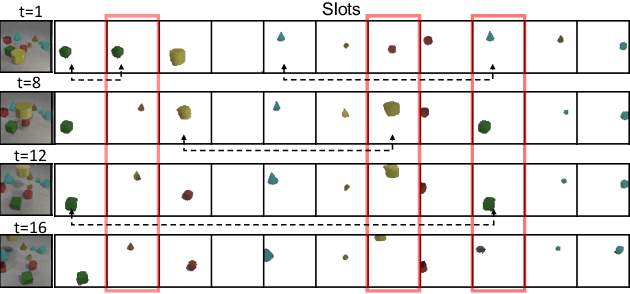
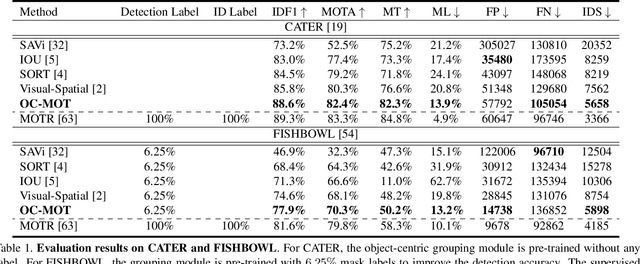
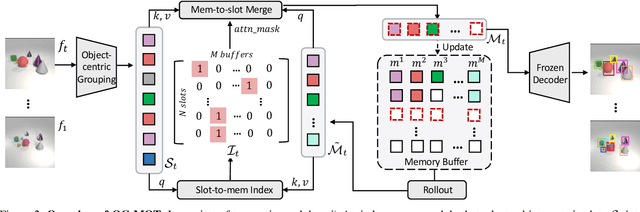
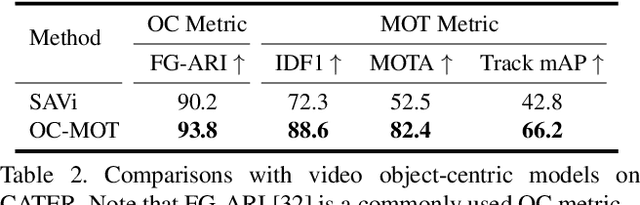
Unsupervised object-centric learning methods allow the partitioning of scenes into entities without additional localization information and are excellent candidates for reducing the annotation burden of multiple-object tracking (MOT) pipelines. Unfortunately, they lack two key properties: objects are often split into parts and are not consistently tracked over time. In fact, state-of-the-art models achieve pixel-level accuracy and temporal consistency by relying on supervised object detection with additional ID labels for the association through time. This paper proposes a video object-centric model for MOT. It consists of an index-merge module that adapts the object-centric slots into detection outputs and an object memory module that builds complete object prototypes to handle occlusions. Benefited from object-centric learning, we only require sparse detection labels (0%-6.25%) for object localization and feature binding. Relying on our self-supervised Expectation-Maximization-inspired loss for object association, our approach requires no ID labels. Our experiments significantly narrow the gap between the existing object-centric model and the fully supervised state-of-the-art and outperform several unsupervised trackers.
DAMM: Directionality-Aware Mixture Model Parallel Sampling for Efficient Dynamical System Learning
Sep 05, 2023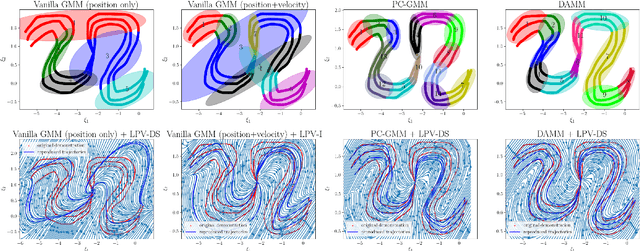
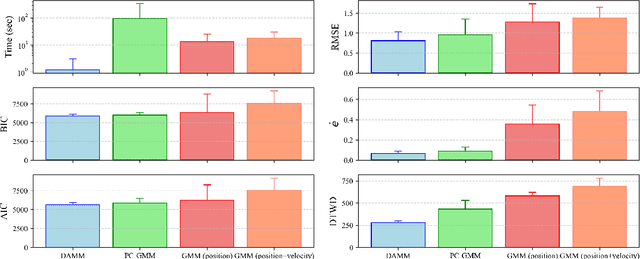
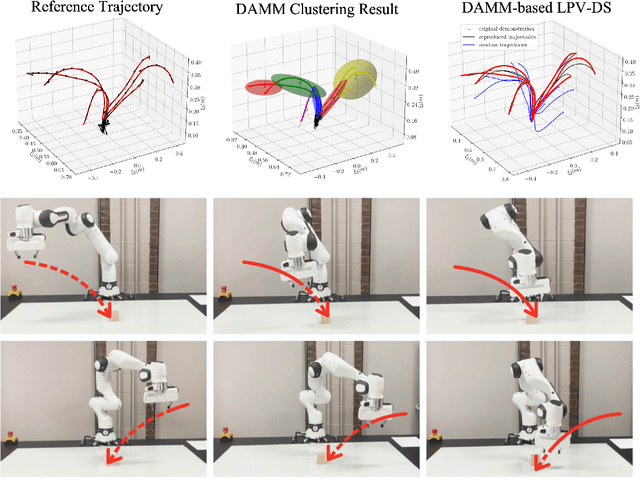
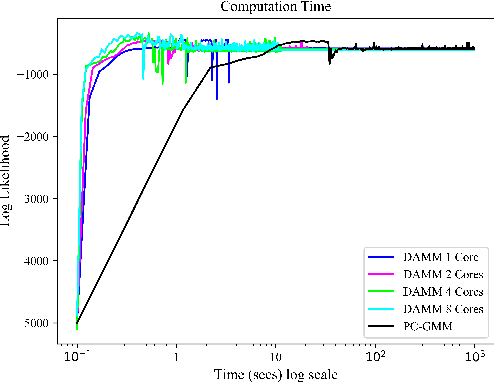
The Linear Parameter Varying Dynamical System (LPV-DS) is a promising framework for learning stable time-invariant motion policies in robot control. By employing statistical modeling and semi-definite optimization, LPV-DS encodes complex motions via non-linear DS, ensuring the robustness and stability of the system. However, the current LPV-DS scheme faces challenges in accurately interpreting trajectory data while maintaining model efficiency and computational efficiency. To address these limitations, we propose the Directionality-aware Mixture Model (DAMM), a new statistical model that leverages Riemannian metric on $d$-dimensional sphere $\mathbb{S}^d$, and efficiently incorporates non-Euclidean directional information with position. Additionally, we introduce a hybrid Markov chain Monte Carlo method that combines the Gibbs Sampling and the Split/Merge Proposal, facilitating parallel computation and enabling faster inference for near real-time learning performance. Through extensive empirical validation, we demonstrate that the improved LPV-DS framework with DAMM is capable of producing physically-meaningful representations of the trajectory data and improved performance of the generated DS while showcasing significantly enhanced learning speed compared to its previous iterations.