 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyRS-R1: Compact Multimodal Language Model for Remote Sensing
May 17, 2025



Remote-sensing applications often run on edge hardware that cannot host today's 7B-parameter multimodal language models. This paper introduces TinyRS, the first 2B-parameter multimodal small language model (MSLM) optimized for remote sensing tasks, and TinyRS-R1, its reasoning-augmented variant. Built upon Qwen2-VL-2B, TinyRS is trained through a four-stage pipeline: pre-training on million satellite images, instruction tuning on visual instruction examples, fine-tuning with Chain-of-Thought (CoT) annotations from the proposed reasoning dataset, and alignment via Group Relative Policy Optimization (GRPO). TinyRS-R1 achieves or surpasses the performance of recent 7B-parameter remote sensing models across classification, VQA, visual grounding, and open-ended question answering-while requiring just one-third of the memory and latency. Our analysis shows that CoT reasoning substantially benefits spatial grounding and scene understanding, while the non-reasoning TinyRS excels in concise, latency-sensitive VQA tasks. TinyRS-R1 represents the first domain-specialized MSLM with GRPO-aligned CoT reasoning for general-purpose remote sensing.
MilChat: Introducing Chain of Thought Reasoning and GRPO to a Multimodal Small Language Model for Remote Sensing
May 12, 2025Remarkable capabilities in understanding and generating text-image content have been demonstrated by recent advancements in multimodal large language models (MLLMs). However, their effectiveness in specialized domains-particularly those requiring resource-efficient and domain-specific adaptations-has remained limited. In this work, a lightweight multimodal language model termed MilChat is introduced, specifically adapted to analyze remote sensing imagery in secluded areas, including challenging missile launch sites. A new dataset, MilData, was compiled by verifying hundreds of aerial images through expert review, and subtle military installations were highlighted via detailed captions. Supervised fine-tuning on a 2B-parameter open-source MLLM with chain-of-thought (CoT) reasoning annotations was performed, enabling more accurate and interpretable explanations. Additionally, Group Relative Policy Optimization (GRPO) was leveraged to enhance the model's ability to detect critical domain-specific cues-such as defensive layouts and key military structures-while minimizing false positives on civilian scenes. Through empirical evaluations, it has been shown that MilChat significantly outperforms both larger, general-purpose multimodal models and existing remote sensing-adapted approaches on open-ended captioning and classification metrics. Over 80% recall and 98% precision were achieved on the newly proposed MilData benchmark, underscoring the potency of targeted fine-tuning and reinforcement learning in specialized real-world applications.
IG-SLAM: Instant Gaussian SLAM
Aug 07, 20243D Gaussian Splatting has recently shown promising results as an alternative scene representation in SLAM systems to neural implicit representations. However, current methods either lack dense depth maps to supervise the mapping process or detailed training designs that consider the scale of the environment. To address these drawbacks, we present IG-SLAM, a dense RGB-only SLAM system that employs robust Dense-SLAM methods for tracking and combines them with Gaussian Splatting. A 3D map of the environment is constructed using accurate pose and dense depth provided by tracking. Additionally, we utilize depth uncertainty in map optimization to improve 3D reconstruction. Our decay strategy in map optimization enhances convergence and allows the system to run at 10 fps in a single process. We demonstrate competitive performance with state-of-the-art RGB-only SLAM systems while achieving faster operation speeds. We present our experiments on the Replica, TUM-RGBD, ScanNet, and EuRoC datasets. The system achieves photo-realistic 3D reconstruction in large-scale sequences, particularly in the EuRoC dataset.
Knowledge Distillation Layer that Lets the Student Decide
Sep 06, 2023Typical technique in knowledge distillation (KD) is regularizing the learning of a limited capacity model (student) by pushing its responses to match a powerful model's (teacher). Albeit useful especially in the penultimate layer and beyond, its action on student's feature transform is rather implicit, limiting its practice in the intermediate layers. To explicitly embed the teacher's knowledge in feature transform, we propose a learnable KD layer for the student which improves KD with two distinct abilities: i) learning how to leverage the teacher's knowledge, enabling to discard nuisance information, and ii) feeding forward the transferred knowledge deeper. Thus, the student enjoys the teacher's knowledge during the inference besides training. Formally, we repurpose 1x1-BN-ReLU-1x1 convolution block to assign a semantic vector to each local region according to the template (supervised by the teacher) that the corresponding region of the student matches. To facilitate template learning in the intermediate layers, we propose a novel form of supervision based on the teacher's decisions. Through rigorous experimentation, we demonstrate the effectiveness of our approach on 3 popular classification benchmarks. Code is available at: https://github.com/adagorgun/letKD-framework
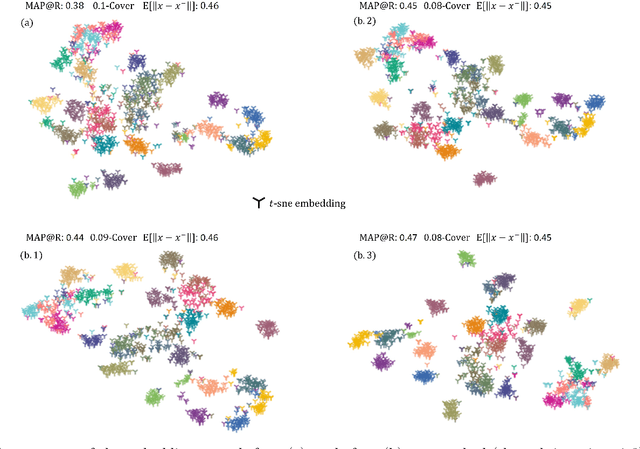
Generalizable Embeddings with Cross-batch Metric Learning
Jul 24, 2023Global average pooling (GAP) is a popular component in deep metric learning (DML) for aggregating features. Its effectiveness is often attributed to treating each feature vector as a distinct semantic entity and GAP as a combination of them. Albeit substantiated, such an explanation's algorithmic implications to learn generalizable entities to represent unseen classes, a crucial DML goal, remain unclear. To address this, we formulate GAP as a convex combination of learnable prototypes. We then show that the prototype learning can be expressed as a recursive process fitting a linear predictor to a batch of samples. Building on that perspective, we consider two batches of disjoint classes at each iteration and regularize the learning by expressing the samples of a batch with the prototypes that are fitted to the other batch. We validate our approach on 4 popular DML benchmarks.
Feature Embedding by Template Matching as a ResNet Block
Oct 03, 2022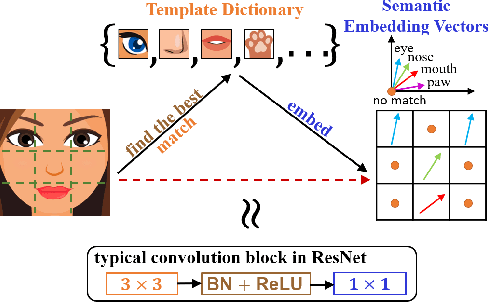
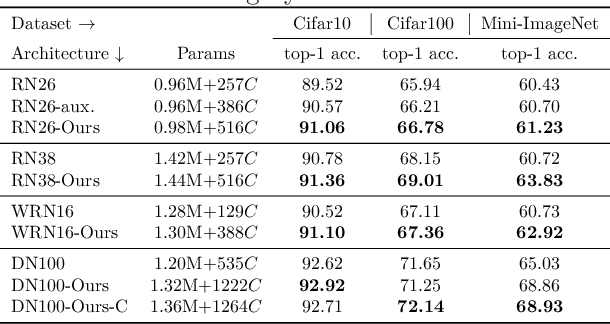
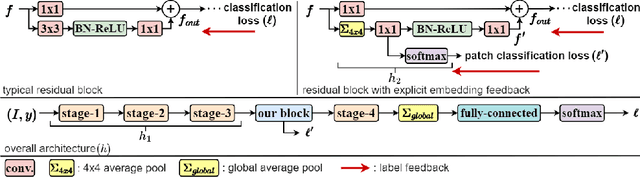
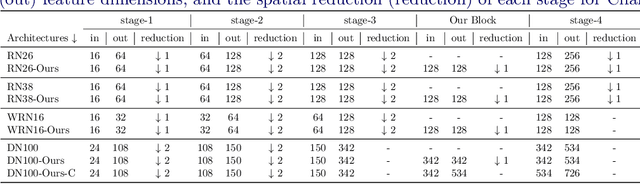
Convolution blocks serve as local feature extractors and are the key to success of the neural networks. To make local semantic feature embedding rather explicit, we reformulate convolution blocks as feature selection according to the best matching kernel. In this manner, we show that typical ResNet blocks indeed perform local feature embedding via template matching once batch normalization (BN) followed by a rectified linear unit (ReLU) is interpreted as arg-max optimizer. Following this perspective, we tailor a residual block that explicitly forces semantically meaningful local feature embedding through using label information. Specifically, we assign a feature vector to each local region according to the classes that the corresponding region matches. We evaluate our method on three popular benchmark datasets with several architectures for image classification and consistently show that our approach substantially improves the performance of the baseline architectures.
Deep Metric Learning with Chance Constraints
Sep 19, 2022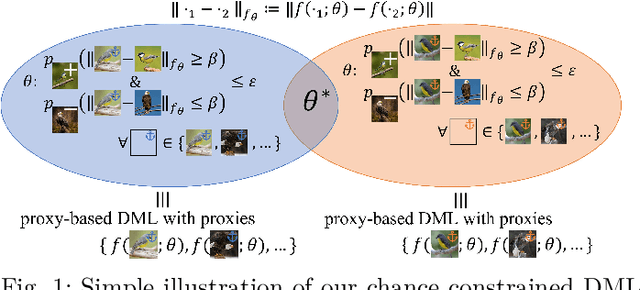
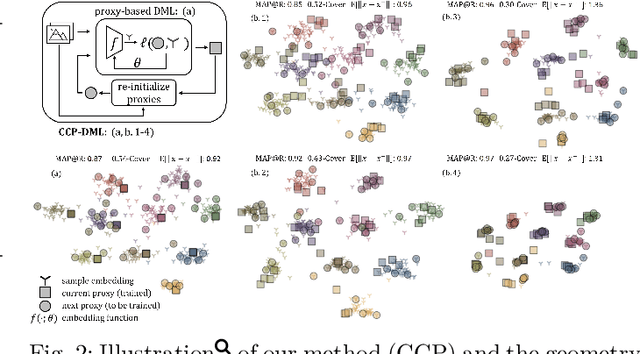

Deep metric learning (DML) aims to minimize empirical expected loss of the pairwise intra-/inter- class proximity violations in the embedding image. We relate DML to feasibility problem of finite chance constraints. We show that minimizer of proxy-based DML satisfies certain chance constraints, and that the worst case generalization performance of the proxy-based methods can be characterized by the radius of the smallest ball around a class proxy to cover the entire domain of the corresponding class samples, suggesting multiple proxies per class helps performance. To provide a scalable algorithm as well as exploiting more proxies, we consider the chance constraints implied by the minimizers of proxy-based DML instances and reformulate DML as finding a feasible point in intersection of such constraints, resulting in a problem to be approximately solved by iterative projections. Simply put, we repeatedly train a regularized proxy-based loss and re-initialize the proxies with the embeddings of the deliberately selected new samples. We apply our method with the well-accepted losses and evaluate on four popular benchmark datasets for image retrieval. Outperforming state-of-the-art, our method consistently improves the performance of the applied losses. Code is available at: https://github.com/yetigurbuz/ccp-dml
Improved Hard Example Mining Approach for Single Shot Object Detectors
Feb 26, 2022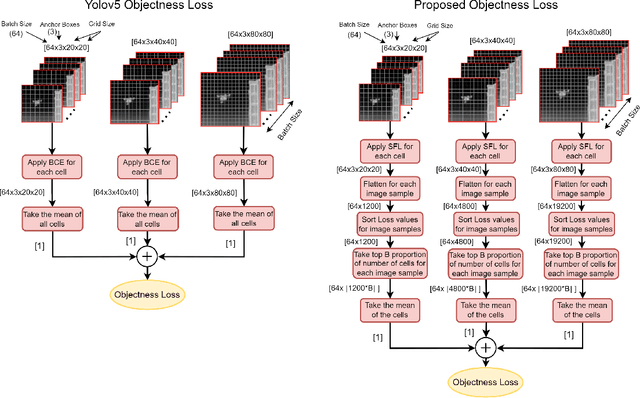
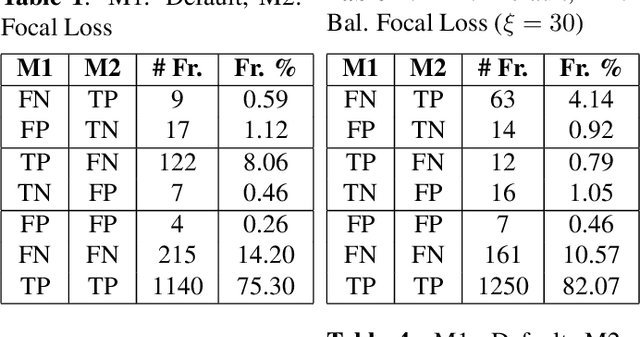
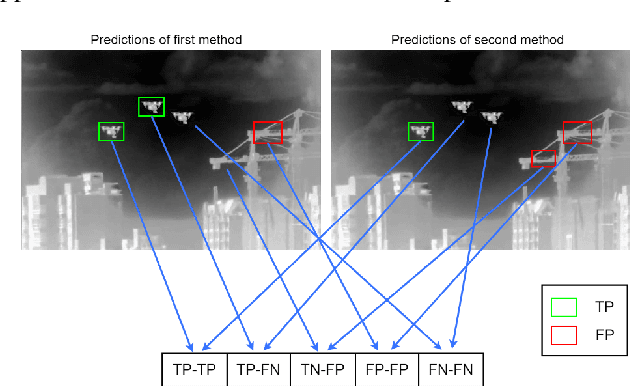
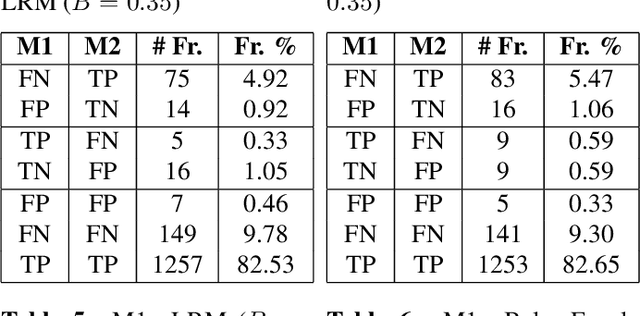
Hard example mining methods generally improve the performance of the object detectors, which suffer from imbalanced training sets. In this work, two existing hard example mining approaches (LRM and focal loss, FL) are adapted and combined in a state-of-the-art real-time object detector, YOLOv5. The effectiveness of the proposed approach for improving the performance on hard examples is extensively evaluated. The proposed method increases mAP by 3% compared to using the original loss function and around 1-2% compared to using the hard-mining methods (LRM or FL) individually on 2021 Anti-UAV Challenge Dataset.
Effect of Parameter Optimization on Classical and Learning-based Image Matching Methods
Aug 28, 2021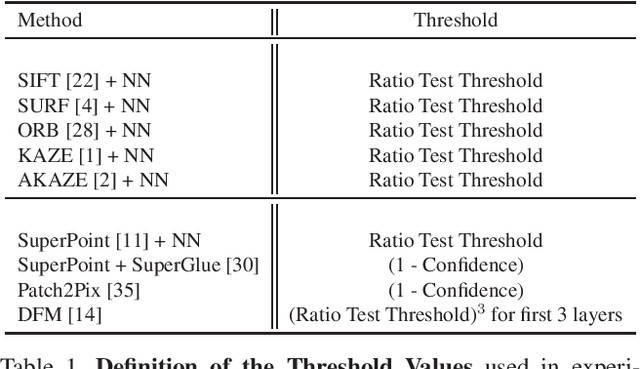
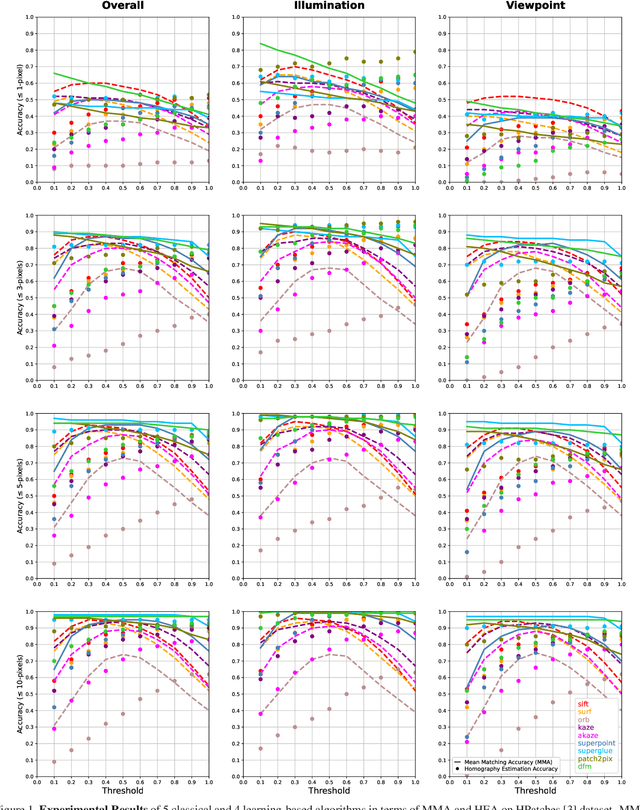
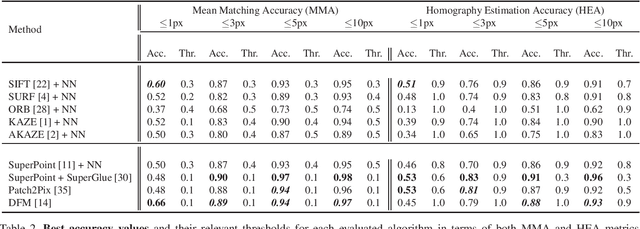
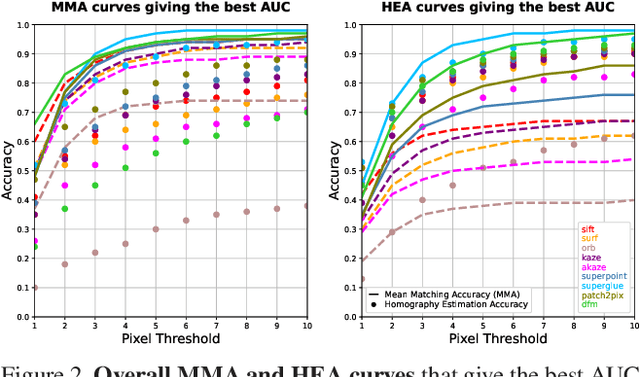
Deep learning-based image matching methods are improved significantly during the recent years. Although these methods are reported to outperform the classical techniques, the performance of the classical methods is not examined in detail. In this study, we compare classical and learning-based methods by employing mutual nearest neighbor search with ratio test and optimizing the ratio test threshold to achieve the best performance on two different performance metrics. After a fair comparison, the experimental results on HPatches dataset reveal that the performance gap between classical and learning-based methods is not that significant. Throughout the experiments, we demonstrated that SuperGlue is the state-of-the-art technique for the image matching problem on HPatches dataset. However, if a single parameter, namely ratio test threshold, is carefully optimized, a well-known traditional method SIFT performs quite close to SuperGlue and even outperforms in terms of mean matching accuracy (MMA) under 1 and 2 pixel thresholds. Moreover, a recent approach, DFM, which only uses pre-trained VGG features as descriptors and ratio test, is shown to outperform most of the well-trained learning-based methods. Therefore, we conclude that the parameters of any classical method should be analyzed carefully before comparing against a learning-based technique.
DFM: A Performance Baseline for Deep Feature Matching
Jun 14, 2021
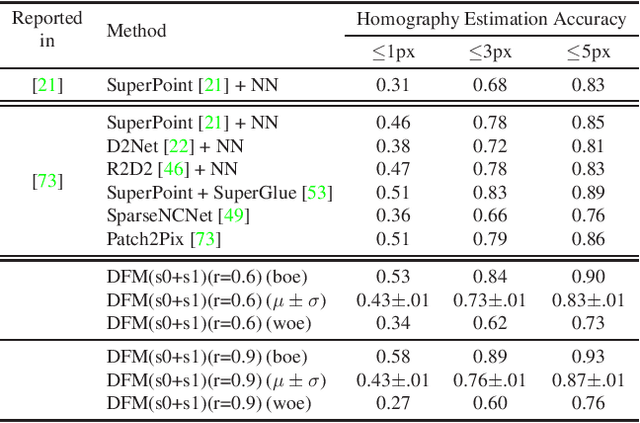
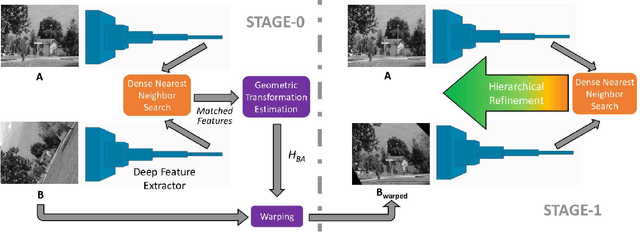

A novel image matching method is proposed that utilizes learned features extracted by an off-the-shelf deep neural network to obtain a promising performance. The proposed method uses pre-trained VGG architecture as a feature extractor and does not require any additional training specific to improve matching. Inspired by well-established concepts in the psychology area, such as the Mental Rotation paradigm, an initial warping is performed as a result of a preliminary geometric transformation estimate. These estimates are simply based on dense matching of nearest neighbors at the terminal layer of VGG network outputs of the images to be matched. After this initial alignment, the same approach is repeated again between reference and aligned images in a hierarchical manner to reach a good localization and matching performance. Our algorithm achieves 0.57 and 0.80 overall scores in terms of Mean Matching Accuracy (MMA) for 1 pixel and 2 pixels thresholds respectively on Hpatches dataset, which indicates a better performance than the state-of-the-art.