 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Concept Dynamics in Diffusion Models via Prompt-Conditioned Interventions
Dec 09, 2025Diffusion models are usually evaluated by their final outputs, gradually denoising random noise into meaningful images. Yet, generation unfolds along a trajectory, and analyzing this dynamic process is crucial for understanding how controllable, reliable, and predictable these models are in terms of their success/failure modes. In this work, we ask the question: when does noise turn into a specific concept (e.g., age) and lock in the denoising trajectory? We propose PCI (Prompt-Conditioned Intervention) to study this question. PCI is a training-free and model-agnostic framework for analyzing concept dynamics through diffusion time. The central idea is the analysis of Concept Insertion Success (CIS), defined as the probability that a concept inserted at a given timestep is preserved and reflected in the final image, offering a way to characterize the temporal dynamics of concept formation. Applied to several state-of-the-art text-to-image diffusion models and a broad taxonomy of concepts, PCI reveals diverse temporal behaviors across diffusion models, in which certain phases of the trajectory are more favorable to specific concepts even within the same concept type. These findings also provide actionable insights for text-driven image editing, highlighting when interventions are most effective without requiring access to model internals or training, and yielding quantitatively stronger edits that achieve a balance of semantic accuracy and content preservation than strong baselines. Code is available at: https://github.com/adagorgun/PCI-Prompt-Controlled-Interventions
VITAL: More Understandable Feature Visualization through Distribution Alignment and Relevant Information Flow
Mar 28, 2025



Neural networks are widely adopted to solve complex and challenging tasks. Especially in high-stakes decision-making, understanding their reasoning process is crucial, yet proves challenging for modern deep networks. Feature visualization (FV) is a powerful tool to decode what information neurons are responding to and hence to better understand the reasoning behind such networks. In particular, in FV we generate human-understandable images that reflect the information detected by neurons of interest. However, current methods often yield unrecognizable visualizations, exhibiting repetitive patterns and visual artifacts that are hard to understand for a human. To address these problems, we propose to guide FV through statistics of real image features combined with measures of relevant network flow to generate prototypical images. Our approach yields human-understandable visualizations that both qualitatively and quantitatively improve over state-of-the-art FVs across various architectures. As such, it can be used to decode which information the network uses, complementing mechanistic circuits that identify where it is encoded. Code is available at: https://github.com/adagorgun/VITAL
Knowledge Distillation Layer that Lets the Student Decide
Sep 06, 2023Typical technique in knowledge distillation (KD) is regularizing the learning of a limited capacity model (student) by pushing its responses to match a powerful model's (teacher). Albeit useful especially in the penultimate layer and beyond, its action on student's feature transform is rather implicit, limiting its practice in the intermediate layers. To explicitly embed the teacher's knowledge in feature transform, we propose a learnable KD layer for the student which improves KD with two distinct abilities: i) learning how to leverage the teacher's knowledge, enabling to discard nuisance information, and ii) feeding forward the transferred knowledge deeper. Thus, the student enjoys the teacher's knowledge during the inference besides training. Formally, we repurpose 1x1-BN-ReLU-1x1 convolution block to assign a semantic vector to each local region according to the template (supervised by the teacher) that the corresponding region of the student matches. To facilitate template learning in the intermediate layers, we propose a novel form of supervision based on the teacher's decisions. Through rigorous experimentation, we demonstrate the effectiveness of our approach on 3 popular classification benchmarks. Code is available at: https://github.com/adagorgun/letKD-framework
Feature Embedding by Template Matching as a ResNet Block
Oct 03, 2022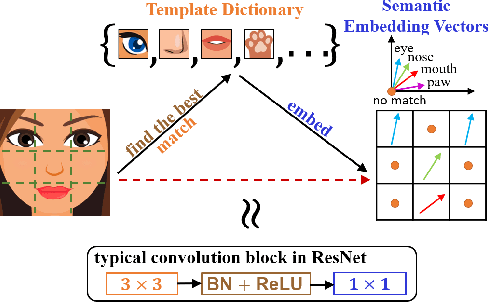
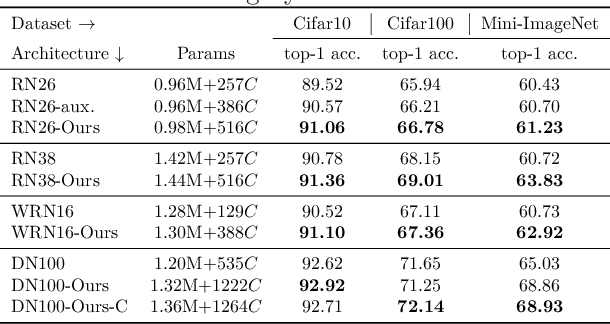
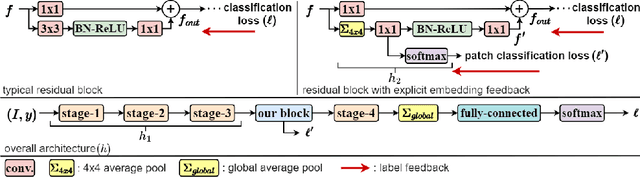
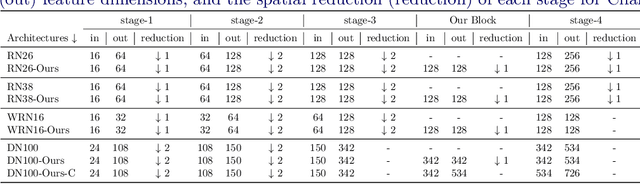
Convolution blocks serve as local feature extractors and are the key to success of the neural networks. To make local semantic feature embedding rather explicit, we reformulate convolution blocks as feature selection according to the best matching kernel. In this manner, we show that typical ResNet blocks indeed perform local feature embedding via template matching once batch normalization (BN) followed by a rectified linear unit (ReLU) is interpreted as arg-max optimizer. Following this perspective, we tailor a residual block that explicitly forces semantically meaningful local feature embedding through using label information. Specifically, we assign a feature vector to each local region according to the classes that the corresponding region matches. We evaluate our method on three popular benchmark datasets with several architectures for image classification and consistently show that our approach substantially improves the performance of the baseline architectures.