 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Leveraging Knowledge Graphs for Orphan Entity Allocation in Resume Processing
Oct 21, 2023
Significant challenges are posed in talent acquisition and recruitment by processing and analyzing unstructured data, particularly resumes. This research presents a novel approach for orphan entity allocation in resume processing using knowledge graphs. Techniques of association mining, concept extraction, external knowledge linking, named entity recognition, and knowledge graph construction are integrated into our pipeline. By leveraging these techniques, the aim is to automate and enhance the efficiency of the job screening process by successfully bucketing orphan entities within resumes. This allows for more effective matching between candidates and job positions, streamlining the resume screening process, and enhancing the accuracy of candidate-job matching. The approach's exceptional effectiveness and resilience are highlighted through extensive experimentation and evaluation, ensuring that alternative measures can be relied upon for seamless processing and orphan entity allocation in case of any component failure. The capabilities of knowledge graphs in generating valuable insights through intelligent information extraction and representation, specifically in the domain of categorizing orphan entities, are highlighted by the results of our research.
DocParser: End-to-end OCR-free Information Extraction from Visually Rich Documents
May 01, 2023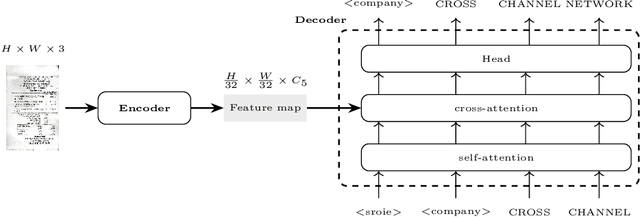
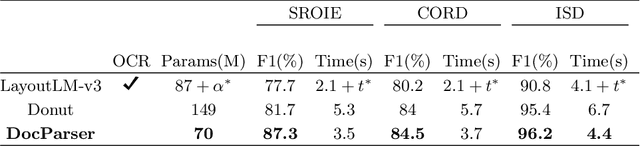
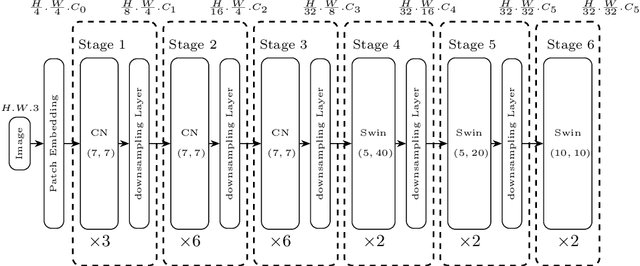

Information Extraction from visually rich documents is a challenging task that has gained a lot of attention in recent years due to its importance in several document-control based applications and its widespread commercial value. The majority of the research work conducted on this topic to date follow a two-step pipeline. First, they read the text using an off-the-shelf Optical Character Recognition (OCR) engine, then, they extract the fields of interest from the obtained text. The main drawback of these approaches is their dependence on an external OCR system, which can negatively impact both performance and computational speed. Recent OCR-free methods were proposed to address the previous issues. Inspired by their promising results, we propose in this paper an OCR-free end-to-end information extraction model named DocParser. It differs from prior end-to-end approaches by its ability to better extract discriminative character features. DocParser achieves state-of-the-art results on various datasets, while still being faster than previous works.
Context-Enhanced Detector For Building Detection From Remote Sensing Images
Oct 11, 2023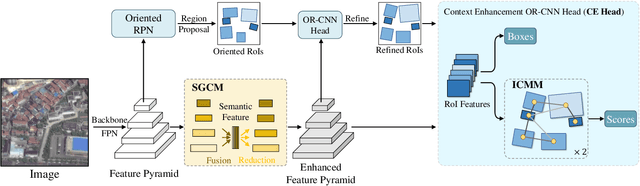
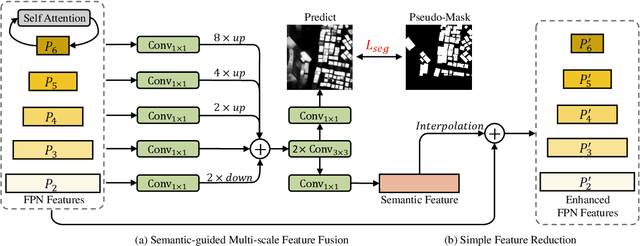
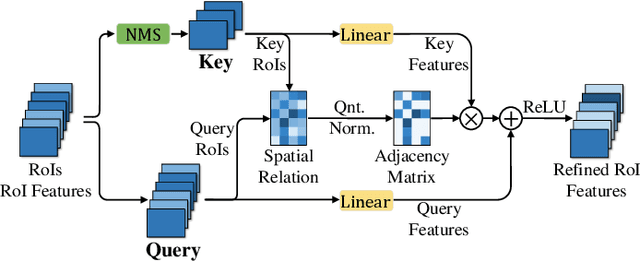

The field of building detection from remote sensing images has made significant progress, but faces challenges in achieving high-accuracy detection due to the diversity in building appearances and the complexity of vast scenes. To address these challenges, we propose a novel approach called Context-Enhanced Detector (CEDet). Our approach utilizes a three-stage cascade structure to enhance the extraction of contextual information and improve building detection accuracy. Specifically, we introduce two modules: the Semantic Guided Contextual Mining (SGCM) module, which aggregates multi-scale contexts and incorporates an attention mechanism to capture long-range interactions, and the Instance Context Mining Module (ICMM), which captures instance-level relationship context by constructing a spatial relationship graph and aggregating instance features. Additionally, we introduce a semantic segmentation loss based on pseudo-masks to guide contextual information extraction. Our method achieves state-of-the-art performance on three building detection benchmarks, including CNBuilding-9P, CNBuilding-23P, and SpaceNet.
ALT: Towards Fine-grained Alignment between Language and CTR Models for Click-Through Rate Prediction
Oct 30, 2023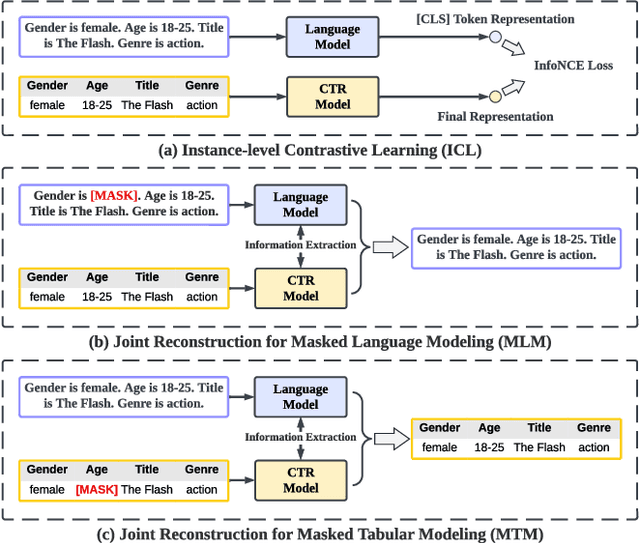
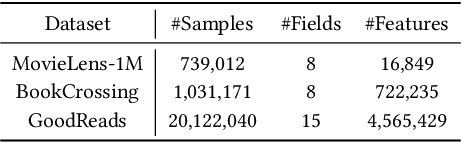

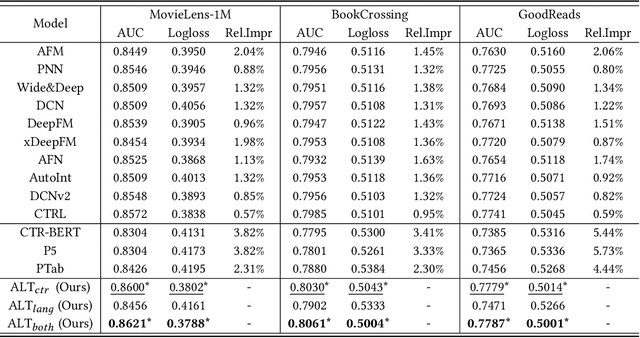
Click-through rate (CTR) prediction plays as a core function module in various personalized online services. According to the data modality and input format, the models for CTR prediction can be mainly classified into two categories. The first one is the traditional CTR models that take as inputs the one-hot encoded ID features of tabular modality, which aims to capture the collaborative signals via feature interaction modeling. The second category takes as inputs the sentences of textual modality obtained by hard prompt templates, where pretrained language models (PLMs) are adopted to extract the semantic knowledge. These two lines of research generally focus on different characteristics of the same input data (i.e., textual and tabular modalities), forming a distinct complementary relationship with each other. Therefore, in this paper, we propose to conduct fine-grained feature-level Alignment between Language and CTR models (ALT) for CTR prediction. Apart from the common CLIP-like instance-level contrastive learning, we further design a novel joint reconstruction pretraining task for both masked language and tabular modeling. Specifically, the masked data of one modality (i.e., tokens or features) has to be recovered with the help of the other modality, which establishes the feature-level interaction and alignment via sufficient mutual information extraction between dual modalities. Moreover, we propose three different finetuning strategies with the option to train the aligned language and CTR models separately or jointly for downstream CTR prediction tasks, thus accommodating the varying efficacy and efficiency requirements for industrial applications. Extensive experiments on three real-world datasets demonstrate that ALT outperforms SOTA baselines, and is highly compatible for various language and CTR models.
Linking Surface Facts to Large-Scale Knowledge Graphs
Oct 23, 2023Open Information Extraction (OIE) methods extract facts from natural language text in the form of ("subject"; "relation"; "object") triples. These facts are, however, merely surface forms, the ambiguity of which impedes their downstream usage; e.g., the surface phrase "Michael Jordan" may refer to either the former basketball player or the university professor. Knowledge Graphs (KGs), on the other hand, contain facts in a canonical (i.e., unambiguous) form, but their coverage is limited by a static schema (i.e., a fixed set of entities and predicates). To bridge this gap, we need the best of both worlds: (i) high coverage of free-text OIEs, and (ii) semantic precision (i.e., monosemy) of KGs. In order to achieve this goal, we propose a new benchmark with novel evaluation protocols that can, for example, measure fact linking performance on a granular triple slot level, while also measuring if a system has the ability to recognize that a surface form has no match in the existing KG. Our extensive evaluation of several baselines show that detection of out-of-KG entities and predicates is more difficult than accurate linking to existing ones, thus calling for more research efforts on this difficult task. We publicly release all resources (data, benchmark and code) on https://github.com/nec-research/fact-linking.
End-to-End Document Classification and Key Information Extraction using Assignment Optimization
Jun 01, 2023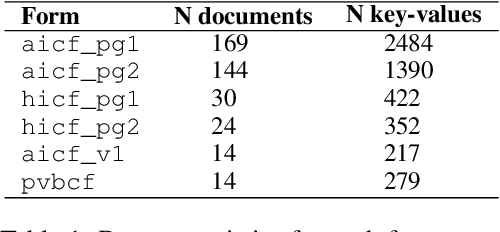

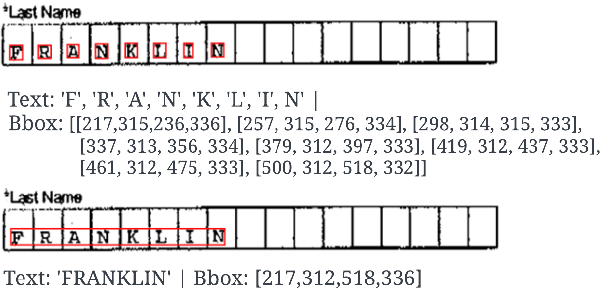
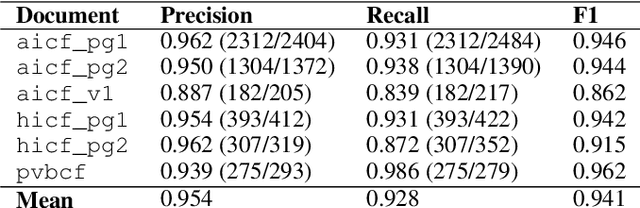
We propose end-to-end document classification and key information extraction (KIE) for automating document processing in forms. Through accurate document classification we harness known information from templates to enhance KIE from forms. We use text and layout encoding with a cosine similarity measure to classify visually-similar documents. We then demonstrate a novel application of mixed integer programming by using assignment optimization to extract key information from documents. Our approach is validated on an in-house dataset of noisy scanned forms. The best performing document classification approach achieved 0.97 f1 score. A mean f1 score of 0.94 for the KIE task suggests there is significant potential in applying optimization techniques. Abation results show that the method relies on document preprocessing techniques to mitigate Type II errors and achieve optimal performance.
Sub-network Discovery and Soft-masking for Continual Learning of Mixed Tasks
Oct 13, 2023Continual learning (CL) has two main objectives: preventing catastrophic forgetting (CF) and encouraging knowledge transfer (KT). The existing literature mainly focused on overcoming CF. Some work has also been done on KT when the tasks are similar. To our knowledge, only one method has been proposed to learn a sequence of mixed tasks. However, these techniques still suffer from CF and/or limited KT. This paper proposes a new CL method to achieve both. It overcomes CF by isolating the knowledge of each task via discovering a subnetwork for it. A soft-masking mechanism is also proposed to preserve the previous knowledge and to enable the new task to leverage the past knowledge to achieve KT. Experiments using classification, generation, information extraction, and their mixture (i.e., heterogeneous tasks) show that the proposed method consistently outperforms strong baselines.
* https://github.com/ZixuanKe/PyContinual
A Knowledge Graph-Based Search Engine for Robustly Finding Doctors and Locations in the Healthcare Domain
Oct 08, 2023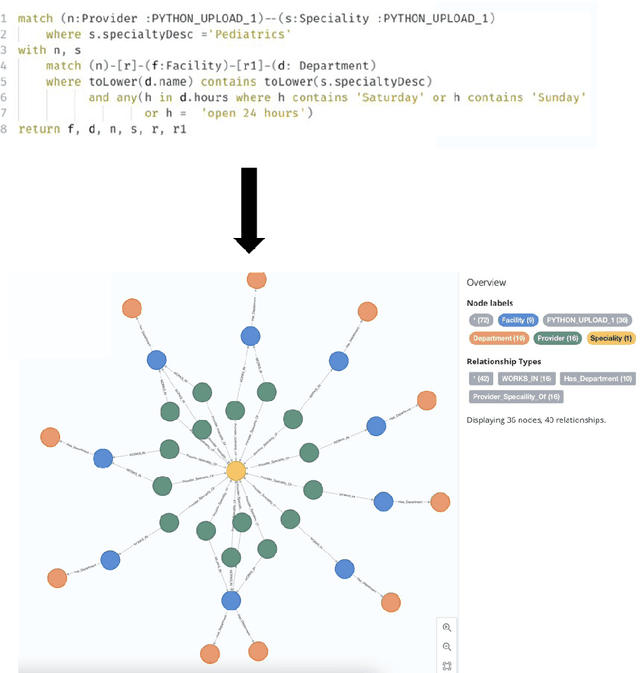
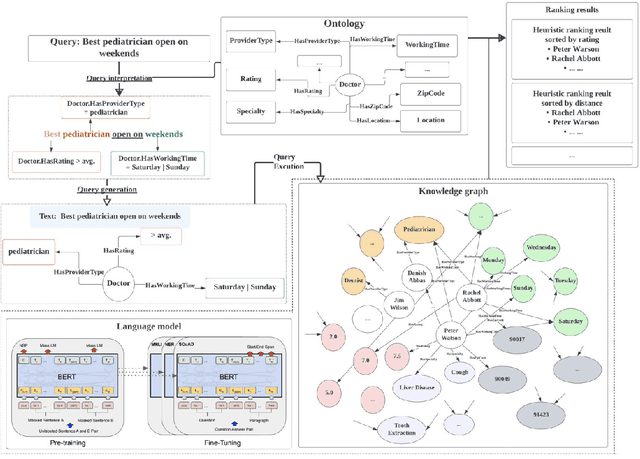
Efficiently finding doctors and locations is an important search problem for patients in the healthcare domain, for which traditional information retrieval methods tend not to work optimally. In the last ten years, knowledge graphs (KGs) have emerged as a powerful way to combine the benefits of gleaning insights from semi-structured data using semantic modeling, natural language processing techniques like information extraction, and robust querying using structured query languages like SPARQL and Cypher. In this short paper, we present a KG-based search engine architecture for robustly finding doctors and locations in the healthcare domain. Early results demonstrate that our approach can lead to significantly higher coverage for complex queries without degrading quality.
WebIE: Faithful and Robust Information Extraction on the Web
May 23, 2023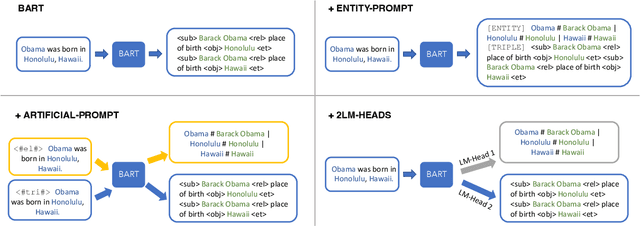
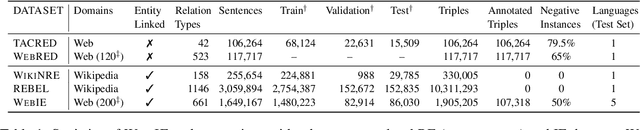
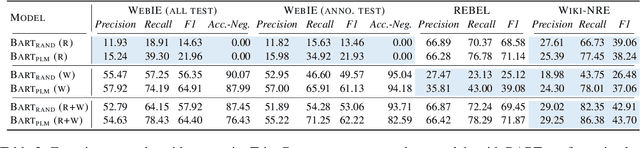
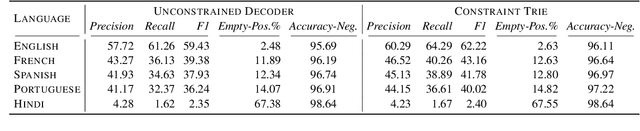
Extracting structured and grounded fact triples from raw text is a fundamental task in Information Extraction (IE). Existing IE datasets are typically collected from Wikipedia articles, using hyperlinks to link entities to the Wikidata knowledge base. However, models trained only on Wikipedia have limitations when applied to web domains, which often contain noisy text or text that does not have any factual information. We present WebIE, the first large-scale, entity-linked closed IE dataset consisting of 1.6M sentences automatically collected from the English Common Crawl corpus. WebIE also includes negative examples, i.e. sentences without fact triples, to better reflect the data on the web. We annotate ~25K triples from WebIE through crowdsourcing and introduce mWebIE, a translation of the annotated set in four other languages: French, Spanish, Portuguese, and Hindi. We evaluate the in-domain, out-of-domain, and zero-shot cross-lingual performance of generative IE models and find models trained on WebIE show better generalisability. We also propose three training strategies that use entity linking as an auxiliary task. Our experiments show that adding Entity-Linking objectives improves the faithfulness of our generative IE models.