 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Contrastive Learning for a Similarity-Guided Tampered Document Data Generation Pipeline
Feb 19, 2026Detecting tampered text in document images is a challenging task due to data scarcity. To address this, previous work has attempted to generate tampered documents using rule-based methods. However, the resulting documents often suffer from limited variety and poor visual quality, typically leaving highly visible artifacts that are rarely observed in real-world manipulations. This undermines the model's ability to learn robust, generalizable features and results in poor performance on real-world data. Motivated by this discrepancy, we propose a novel method for generating high-quality tampered document images. We first train an auxiliary network to compare text crops, leveraging contrastive learning with a novel strategy for defining positive pairs and their corresponding negatives. We also train a second auxiliary network to evaluate whether a crop tightly encloses the intended characters, without cutting off parts of characters or including parts of adjacent ones. Using a carefully designed generation pipeline that leverages both networks, we introduce a framework capable of producing diverse, high-quality tampered document images. We assess the effectiveness of our data generation pipeline by training multiple models on datasets derived from the same source images, generated using our method and existing approaches, under identical training protocols. Evaluating these models on various open-source datasets shows that our pipeline yields consistent performance improvements across architectures and datasets.
PACT: Pruning and Clustering-Based Token Reduction for Faster Visual Language Models
Apr 11, 2025Visual Language Models require substantial computational resources for inference due to the additional input tokens needed to represent visual information. However, these visual tokens often contain redundant and unimportant information, resulting in an unnecessarily high number of tokens. To address this, we introduce PACT, a method that reduces inference time and memory usage by pruning irrelevant tokens and merging visually redundant ones at an early layer of the language model. Our approach uses a novel importance metric to identify unimportant tokens without relying on attention scores, making it compatible with FlashAttention. We also propose a novel clustering algorithm, called Distance Bounded Density Peak Clustering, which efficiently clusters visual tokens while constraining the distances between elements within a cluster by a predefined threshold. We demonstrate the effectiveness of PACT through extensive experiments.
Evaluating Adversarial Robustness on Document Image Classification
May 01, 2023



Adversarial attacks and defenses have gained increasing interest on computer vision systems in recent years, but as of today, most investigations are limited to images. However, many artificial intelligence models actually handle documentary data, which is very different from real world images. Hence, in this work, we try to apply the adversarial attack philosophy on documentary and natural data and to protect models against such attacks. We focus our work on untargeted gradient-based, transfer-based and score-based attacks and evaluate the impact of adversarial training, JPEG input compression and grey-scale input transformation on the robustness of ResNet50 and EfficientNetB0 model architectures. To the best of our knowledge, no such work has been conducted by the community in order to study the impact of these attacks on the document image classification task.
DocParser: End-to-end OCR-free Information Extraction from Visually Rich Documents
May 01, 2023



Information Extraction from visually rich documents is a challenging task that has gained a lot of attention in recent years due to its importance in several document-control based applications and its widespread commercial value. The majority of the research work conducted on this topic to date follow a two-step pipeline. First, they read the text using an off-the-shelf Optical Character Recognition (OCR) engine, then, they extract the fields of interest from the obtained text. The main drawback of these approaches is their dependence on an external OCR system, which can negatively impact both performance and computational speed. Recent OCR-free methods were proposed to address the previous issues. Inspired by their promising results, we propose in this paper an OCR-free end-to-end information extraction model named DocParser. It differs from prior end-to-end approaches by its ability to better extract discriminative character features. DocParser achieves state-of-the-art results on various datasets, while still being faster than previous works.
EfficientQA : a RoBERTa Based Phrase-Indexed Question-Answering System
Jan 30, 2021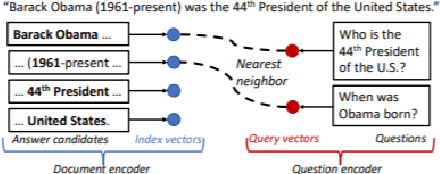
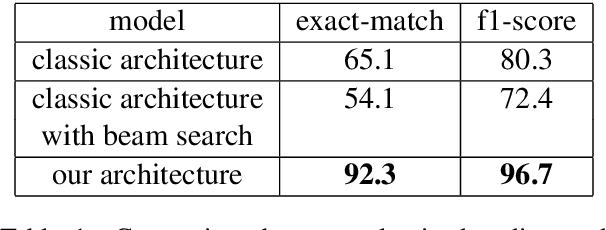
State-of-the-art extractive question answering models achieve superhuman performances on the SQuAD benchmark. Yet, they are unreasonably heavy and need expensive GPU computing to answer questions in a reasonable time. Thus, they cannot be used for real-world queries on hundreds of thousands of documents in the open-domain question answering paradigm. In this paper, we explore the possibility to transfer the natural language understanding of language models into dense vectors representing questions and answer candidates, in order to make the task of question-answering compatible with a simple nearest neighbor search task. This new model, that we call EfficientQA, takes advantage from the pair of sequences kind of input of BERT-based models to build meaningful dense representations of candidate answers. These latter are extracted from the context in a question-agnostic fashion. Our model achieves state-of-the-art results in Phrase-Indexed Question Answering (PIQA) beating the previous state-of-art by 1.3 points in exact-match and 1.4 points in f1-score. These results show that dense vectors are able to embed very rich semantic representations of sequences, although these ones were built from language models not originally trained for the use-case. Thus, in order to build more resource efficient NLP systems in the future, training language models that are better adapted to build dense representations of phrases is one of the possibilities.
MIX : a Multi-task Learning Approach to Solve Open-Domain Question Answering
Dec 17, 2020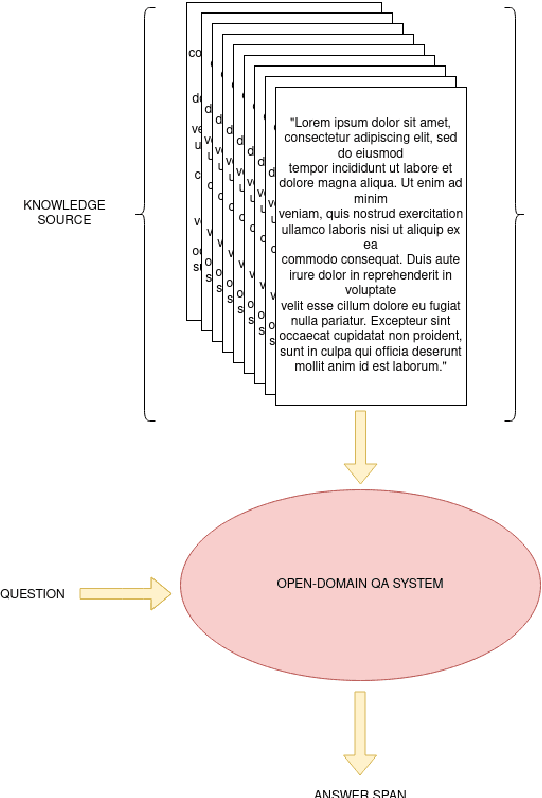
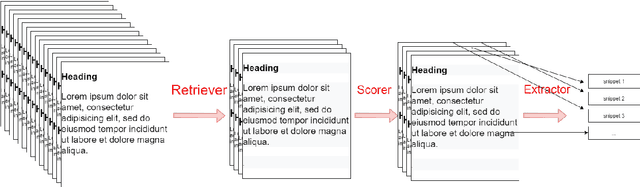
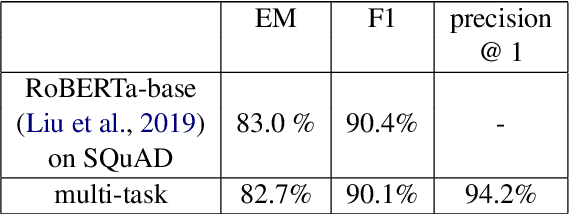
In this paper, we introduce MIX : a multi-task deep learning approach to solve Open-Domain Question Answering. First, we design our system as a multi-stage pipeline made of 3 building blocks : a BM25-based Retriever, to reduce the search space; RoBERTa based Scorer and Extractor, to rank retrieved documents and extract relevant spans of text respectively. Eventually, we further improve computational efficiency of our system to deal with the scalability challenge : thanks to multi-task learning, we parallelize the close tasks solved by the Scorer and the Extractor. Our system outperforms previous state-of-the-art by 12 points in both f1-score and exact-match on the squad-open benchmark.
VisualWordGrid: Information Extraction From Scanned Documents Using A Multimodal Approach
Oct 13, 2020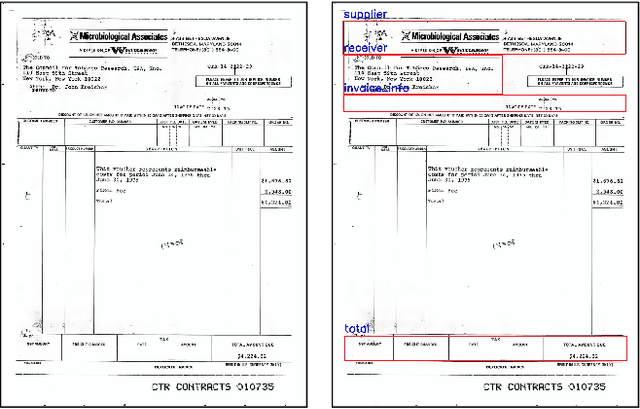

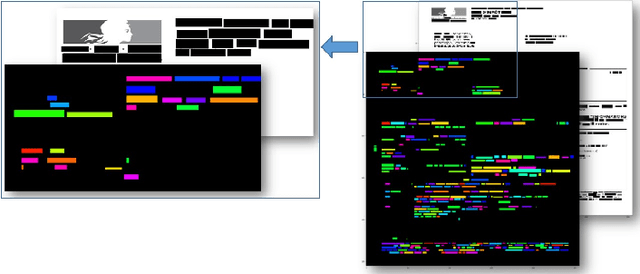
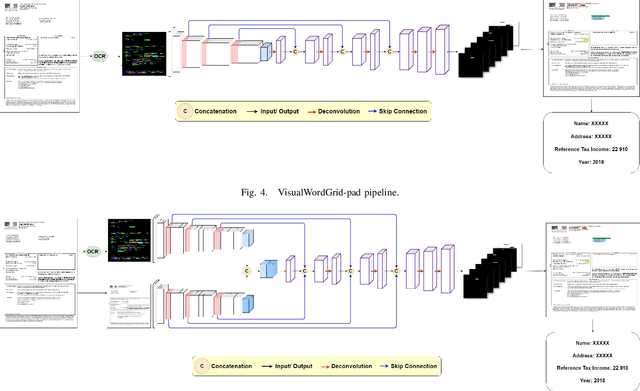
We introduce a novel approach for scanned document representation to perform field extraction. It allows the simultaneous encoding of the textual, visual and layout information in a 3D matrix used as an input to a segmentation model. We improve the recent Chargrid and Wordgrid models in several ways, first by taking into account the visual modality, then by boosting its robustness in regards to small datasets while keeping the inference time low. Our approach is tested on public and private document-image datasets, showing higher performances compared to the recent state-of-the-art methods.