 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOblivion: Self-Adaptive Agentic Memory Control through Decay-Driven Activation
Mar 31, 2026Human memory adapts through selective forgetting: experiences become less accessible over time but can be reactivated by reinforcement or contextual cues. In contrast, memory-augmented LLM agents rely on "always-on" retrieval and "flat" memory storage, causing high interference and latency as histories grow. We introduce Oblivion, a memory control framework that casts forgetting as decay-driven reductions in accessibility, not explicit deletion. Oblivion decouples memory control into read and write paths. The read path decides when to consult memory, based on agent uncertainty and memory buffer sufficiency, avoiding redundant always-on access. The write path decides what to strengthen, by reinforcing memories contributing to forming the response. Together, this enables hierarchical memory organization that maintains persistent high-level strategies while dynamically loading details as needed. We evaluate on both static and dynamic long-horizon interaction benchmarks. Results show that Oblivion dynamically adapts memory access and reinforcement, balancing learning and forgetting under shifting contexts, highlighting that memory control is essential for effective LLM-agentic reasoning. The source code is available at https://github.com/nec-research/oblivion.
MEDDxAgent: A Unified Modular Agent Framework for Explainable Automatic Differential Diagnosis
Feb 26, 2025Differential Diagnosis (DDx) is a fundamental yet complex aspect of clinical decision-making, in which physicians iteratively refine a ranked list of possible diseases based on symptoms, antecedents, and medical knowledge. While recent advances in large language models have shown promise in supporting DDx, existing approaches face key limitations, including single-dataset evaluations, isolated optimization of components, unrealistic assumptions about complete patient profiles, and single-attempt diagnosis. We introduce a Modular Explainable DDx Agent (MEDDxAgent) framework designed for interactive DDx, where diagnostic reasoning evolves through iterative learning, rather than assuming a complete patient profile is accessible. MEDDxAgent integrates three modular components: (1) an orchestrator (DDxDriver), (2) a history taking simulator, and (3) two specialized agents for knowledge retrieval and diagnosis strategy. To ensure robust evaluation, we introduce a comprehensive DDx benchmark covering respiratory, skin, and rare diseases. We analyze single-turn diagnostic approaches and demonstrate the importance of iterative refinement when patient profiles are not available at the outset. Our broad evaluation demonstrates that MEDDxAgent achieves over 10% accuracy improvements in interactive DDx across both large and small LLMs, while offering critical explainability into its diagnostic reasoning process.
ANHALTEN: Cross-Lingual Transfer for German Token-Level Reference-Free Hallucination Detection
Jul 18, 2024



Research on token-level reference-free hallucination detection has predominantly focused on English, primarily due to the scarcity of robust datasets in other languages. This has hindered systematic investigations into the effectiveness of cross-lingual transfer for this important NLP application. To address this gap, we introduce ANHALTEN, a new evaluation dataset that extends the English hallucination detection dataset to German. To the best of our knowledge, this is the first work that explores cross-lingual transfer for token-level reference-free hallucination detection. ANHALTEN contains gold annotations in German that are parallel (i.e., directly comparable to the original English instances). We benchmark several prominent cross-lingual transfer approaches, demonstrating that larger context length leads to better hallucination detection in German, even without succeeding context. Importantly, we show that the sample-efficient few-shot transfer is the most effective approach in most setups. This highlights the practical benefits of minimal annotation effort in the target language for reference-free hallucination detection. Aiming to catalyze future research on cross-lingual token-level reference-free hallucination detection, we make ANHALTEN publicly available: https://github.com/janekh24/anhalten
Walking a Tightrope -- Evaluating Large Language Models in High-Risk Domains
Nov 25, 2023



High-risk domains pose unique challenges that require language models to provide accurate and safe responses. Despite the great success of large language models (LLMs), such as ChatGPT and its variants, their performance in high-risk domains remains unclear. Our study delves into an in-depth analysis of the performance of instruction-tuned LLMs, focusing on factual accuracy and safety adherence. To comprehensively assess the capabilities of LLMs, we conduct experiments on six NLP datasets including question answering and summarization tasks within two high-risk domains: legal and medical. Further qualitative analysis highlights the existing limitations inherent in current LLMs when evaluating in high-risk domains. This underscores the essential nature of not only improving LLM capabilities but also prioritizing the refinement of domain-specific metrics, and embracing a more human-centric approach to enhance safety and factual reliability. Our findings advance the field toward the concerns of properly evaluating LLMs in high-risk domains, aiming to steer the adaptability of LLMs in fulfilling societal obligations and aligning with forthcoming regulations, such as the EU AI Act.
Linking Surface Facts to Large-Scale Knowledge Graphs
Oct 23, 2023



Open Information Extraction (OIE) methods extract facts from natural language text in the form of ("subject"; "relation"; "object") triples. These facts are, however, merely surface forms, the ambiguity of which impedes their downstream usage; e.g., the surface phrase "Michael Jordan" may refer to either the former basketball player or the university professor. Knowledge Graphs (KGs), on the other hand, contain facts in a canonical (i.e., unambiguous) form, but their coverage is limited by a static schema (i.e., a fixed set of entities and predicates). To bridge this gap, we need the best of both worlds: (i) high coverage of free-text OIEs, and (ii) semantic precision (i.e., monosemy) of KGs. In order to achieve this goal, we propose a new benchmark with novel evaluation protocols that can, for example, measure fact linking performance on a granular triple slot level, while also measuring if a system has the ability to recognize that a surface form has no match in the existing KG. Our extensive evaluation of several baselines show that detection of out-of-KG entities and predicates is more difficult than accurate linking to existing ones, thus calling for more research efforts on this difficult task. We publicly release all resources (data, benchmark and code) on https://github.com/nec-research/fact-linking.
TADA: Efficient Task-Agnostic Domain Adaptation for Transformers
May 22, 2023



Intermediate training of pre-trained transformer-based language models on domain-specific data leads to substantial gains for downstream tasks. To increase efficiency and prevent catastrophic forgetting alleviated from full domain-adaptive pre-training, approaches such as adapters have been developed. However, these require additional parameters for each layer, and are criticized for their limited expressiveness. In this work, we introduce TADA, a novel task-agnostic domain adaptation method which is modular, parameter-efficient, and thus, data-efficient. Within TADA, we retrain the embeddings to learn domain-aware input representations and tokenizers for the transformer encoder, while freezing all other parameters of the model. Then, task-specific fine-tuning is performed. We further conduct experiments with meta-embeddings and newly introduced meta-tokenizers, resulting in one model per task in multi-domain use cases. Our broad evaluation in 4 downstream tasks for 14 domains across single- and multi-domain setups and high- and low-resource scenarios reveals that TADA is an effective and efficient alternative to full domain-adaptive pre-training and adapters for domain adaptation, while not introducing additional parameters or complex training steps.
Can Demographic Factors Improve Text Classification? Revisiting Demographic Adaptation in the Age of Transformers
Oct 13, 2022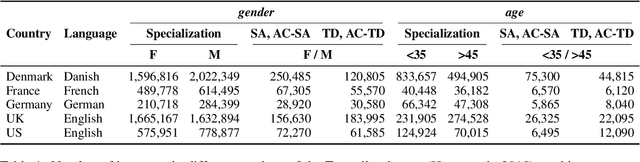

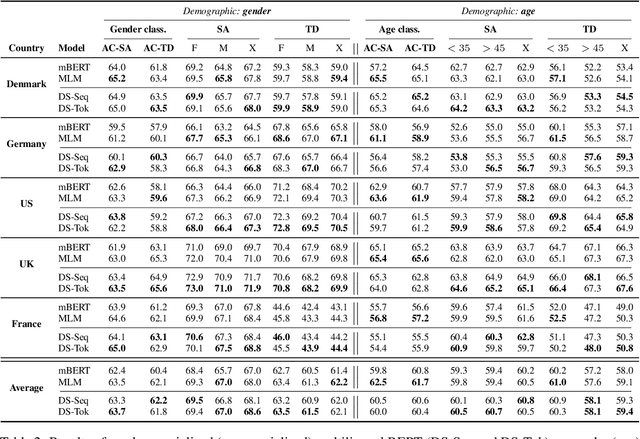
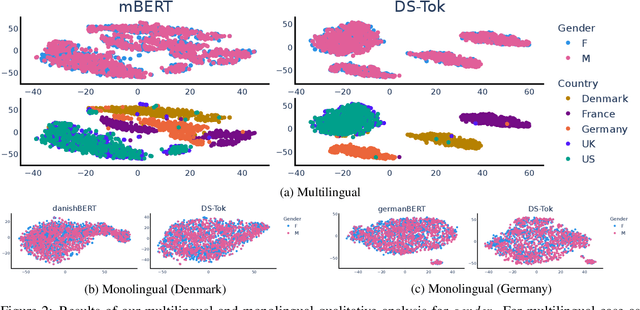
Demographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating demographic factors can consistently improve performance for various NLP tasks with traditional NLP models. In this work, we investigate whether these previous findings still hold with state-of-the-art pretrained Transformer-based language models (PLMs). We use three common specialization methods proven effective for incorporating external knowledge into pretrained Transformers (e.g., domain-specific or geographic knowledge). We adapt the language representations for the demographic dimensions of gender and age, using continuous language modeling and dynamic multi-task learning for adaptation, where we couple language modeling objectives with the prediction of demographic classes. Our results when employing a multilingual PLM show substantial performance gains across four languages (English, German, French, and Danish), which is consistent with the results of previous work. However, controlling for confounding factors -- primarily domain and language proficiency of Transformer-based PLMs -- shows that downstream performance gains from our demographic adaptation do not actually stem from demographic knowledge. Our results indicate that demographic specialization of PLMs, while holding promise for positive societal impact, still represents an unsolved problem for (modern) NLP.
On the Limitations of Sociodemographic Adaptation with Transformers
Aug 01, 2022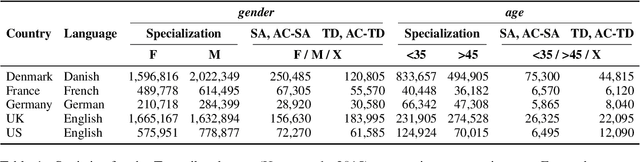
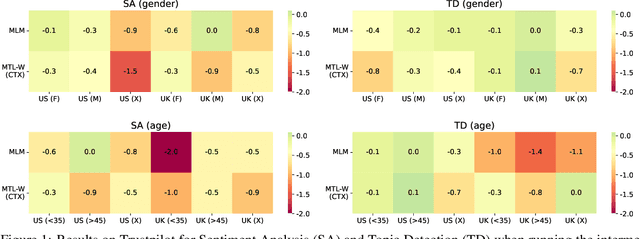
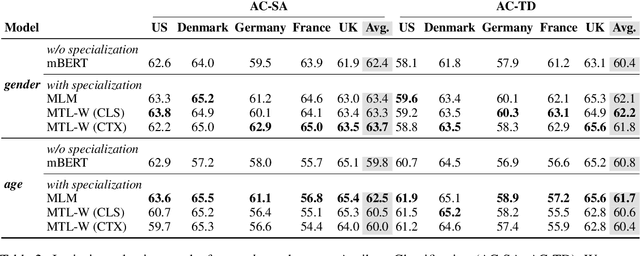
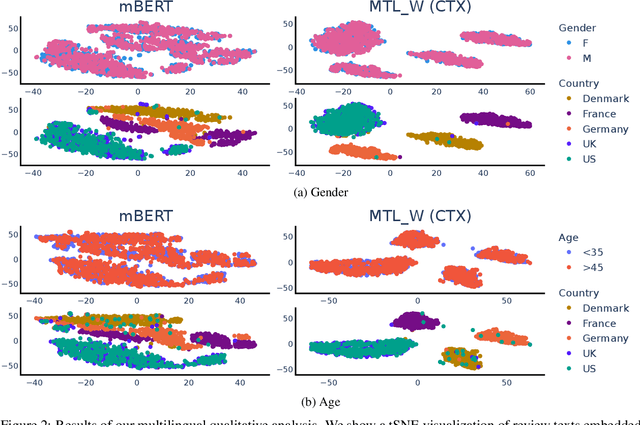
Sociodemographic factors (e.g., gender or age) shape our language. Previous work showed that incorporating specific sociodemographic factors can consistently improve performance for various NLP tasks in traditional NLP models. We investigate whether these previous findings still hold with state-of-the-art pretrained Transformers. We use three common specialization methods proven effective for incorporating external knowledge into pretrained Transformers (e.g., domain-specific or geographic knowledge). We adapt the language representations for the sociodemographic dimensions of gender and age, using continuous language modeling and dynamic multi-task learning for adaptation, where we couple language modeling with the prediction of a sociodemographic class. Our results when employing a multilingual model show substantial performance gains across four languages (English, German, French, and Danish). These findings are in line with the results of previous work and hold promise for successful sociodemographic specialization. However, controlling for confounding factors like domain and language shows that, while sociodemographic adaptation does improve downstream performance, the gains do not always solely stem from sociodemographic knowledge. Our results indicate that sociodemographic specialization, while very important, is still an unresolved problem in NLP.
ZusammenQA: Data Augmentation with Specialized Models for Cross-lingual Open-retrieval Question Answering System
May 30, 2022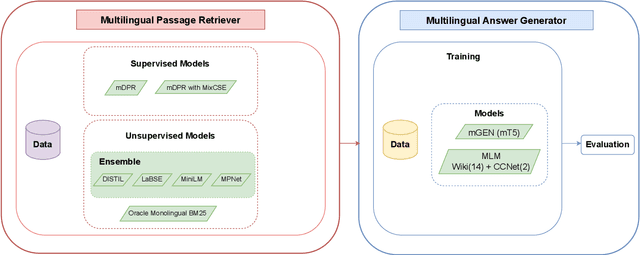



This paper introduces our proposed system for the MIA Shared Task on Cross-lingual Open-retrieval Question Answering (COQA). In this challenging scenario, given an input question the system has to gather evidence documents from a multilingual pool and generate from them an answer in the language of the question. We devised several approaches combining different model variants for three main components: Data Augmentation, Passage Retrieval, and Answer Generation. For passage retrieval, we evaluated the monolingual BM25 ranker against the ensemble of re-rankers based on multilingual pretrained language models (PLMs) and also variants of the shared task baseline, re-training it from scratch using a recently introduced contrastive loss that maintains a strong gradient signal throughout training by means of mixed negative samples. For answer generation, we focused on language- and domain-specialization by means of continued language model (LM) pretraining of existing multilingual encoders. Additionally, for both passage retrieval and answer generation, we augmented the training data provided by the task organizers with automatically generated question-answer pairs created from Wikipedia passages to mitigate the issue of data scarcity, particularly for the low-resource languages for which no training data were provided. Our results show that language- and domain-specialization as well as data augmentation help, especially for low-resource languages.
Multi2WOZ: A Robust Multilingual Dataset and Conversational Pretraining for Task-Oriented Dialog
May 20, 2022
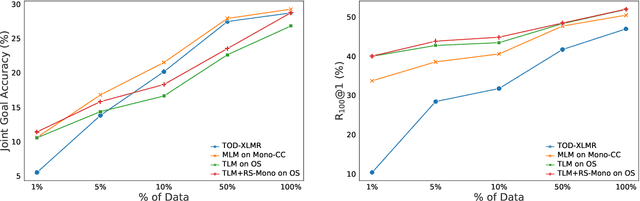

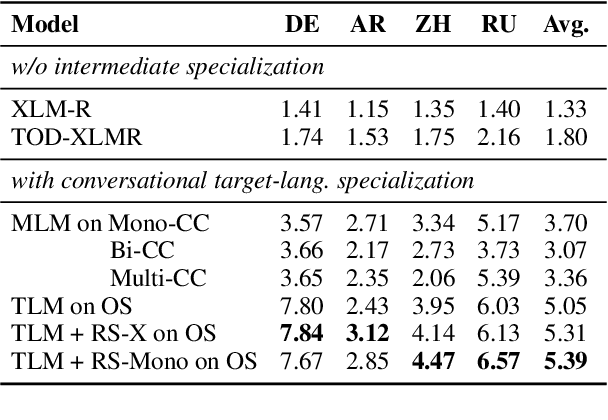
Research on (multi-domain) task-oriented dialog (TOD) has predominantly focused on the English language, primarily due to the shortage of robust TOD datasets in other languages, preventing the systematic investigation of cross-lingual transfer for this crucial NLP application area. In this work, we introduce Multi2WOZ, a new multilingual multi-domain TOD dataset, derived from the well-established English dataset MultiWOZ, that spans four typologically diverse languages: Chinese, German, Arabic, and Russian. In contrast to concurrent efforts, Multi2WOZ contains gold-standard dialogs in target languages that are directly comparable with development and test portions of the English dataset, enabling reliable and comparative estimates of cross-lingual transfer performance for TOD. We then introduce a new framework for multilingual conversational specialization of pretrained language models (PrLMs) that aims to facilitate cross-lingual transfer for arbitrary downstream TOD tasks. Using such conversational PrLMs specialized for concrete target languages, we systematically benchmark a number of zero-shot and few-shot cross-lingual transfer approaches on two standard TOD tasks: Dialog State Tracking and Response Retrieval. Our experiments show that, in most setups, the best performance entails the combination of (I) conversational specialization in the target language and (ii) few-shot transfer for the concrete TOD task. Most importantly, we show that our conversational specialization in the target language allows for an exceptionally sample-efficient few-shot transfer for downstream TOD tasks.