 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAR Despeckling via Regional Denoising Diffusion Probabilistic Model
Jan 06, 2024
Speckle noise poses a significant challenge in maintaining the quality of synthetic aperture radar (SAR) images, so SAR despeckling techniques have drawn increasing attention. Despite the tremendous advancements of deep learning in fixed-scale SAR image despeckling, these methods still struggle to deal with large-scale SAR images. To address this problem, this paper introduces a novel despeckling approach termed Region Denoising Diffusion Probabilistic Model (R-DDPM) based on generative models. R-DDPM enables versatile despeckling of SAR images across various scales, accomplished within a single training session. Moreover, The artifacts in the fused SAR images can be avoided effectively with the utilization of region-guided inverse sampling. Experiments of our proposed R-DDPM on Sentinel-1 data demonstrates superior performance to existing methods.
Enhanced Distribution Alignment for Post-Training Quantization of Diffusion Models
Jan 09, 2024Diffusion models have achieved great success in image generation tasks through iterative noise estimation. However, the heavy denoising process and complex neural networks hinder their low-latency applications in real-world scenarios. Quantization can effectively reduce model complexity, and post-training quantization (PTQ), which does not require fine-tuning, is highly promising in accelerating the denoising process. Unfortunately, we find that due to the highly dynamic distribution of activations in different denoising steps, existing PTQ methods for diffusion models suffer from distribution mismatch issues at both calibration sample level and reconstruction output level, which makes the performance far from satisfactory, especially in low-bit cases. In this paper, we propose Enhanced Distribution Alignment for Post-Training Quantization of Diffusion Models (EDA-DM) to address the above issues. Specifically, at the calibration sample level, we select calibration samples based on the density and diversity in the latent space, thus facilitating the alignment of their distribution with the overall samples; and at the reconstruction output level, we propose Fine-grained Block Reconstruction, which can align the outputs of the quantized model and the full-precision model at different network granularity. Extensive experiments demonstrate that EDA-DM outperforms the existing post-training quantization frameworks in both unconditional and conditional generation scenarios. At low-bit precision, the quantized models with our method even outperform the full-precision models on most datasets.
ElasticDiffusion: Training-free Arbitrary Size Image Generation
Nov 30, 2023Diffusion models have revolutionized image generation in recent years, yet they are still limited to a few sizes and aspect ratios. We propose ElasticDiffusion, a novel training-free decoding method that enables pretrained text-to-image diffusion models to generate images with various sizes. ElasticDiffusion attempts to decouple the generation trajectory of a pretrained model into local and global signals. The local signal controls low-level pixel information and can be estimated on local patches, while the global signal is used to maintain overall structural consistency and is estimated with a reference image. We test our method on CelebA-HQ (faces) and LAION-COCO (objects/indoor/outdoor scenes). Our experiments and qualitative results show superior image coherence quality across aspect ratios compared to MultiDiffusion and the standard decoding strategy of Stable Diffusion. Code: https://github.com/MoayedHajiAli/ElasticDiffusion-official.git
Decoupling Degradation and Content Processing for Adverse Weather Image Restoration
Dec 08, 2023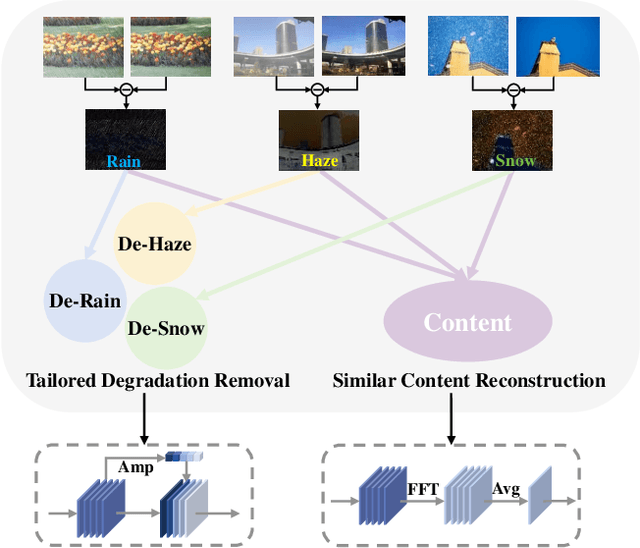
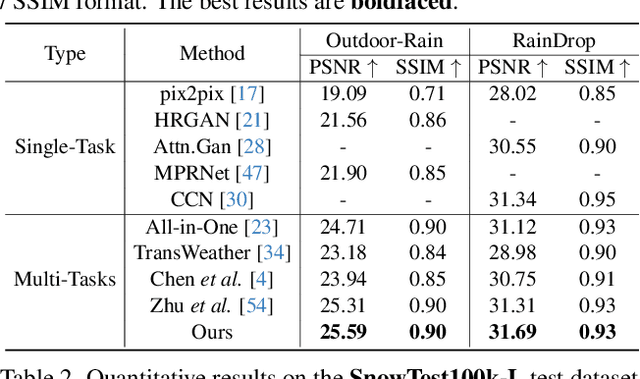
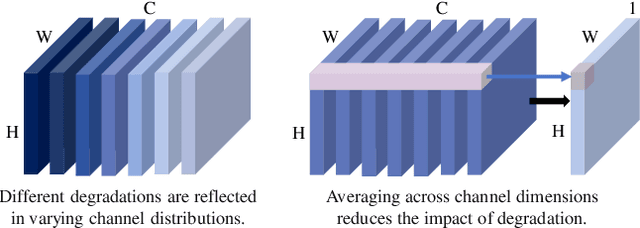
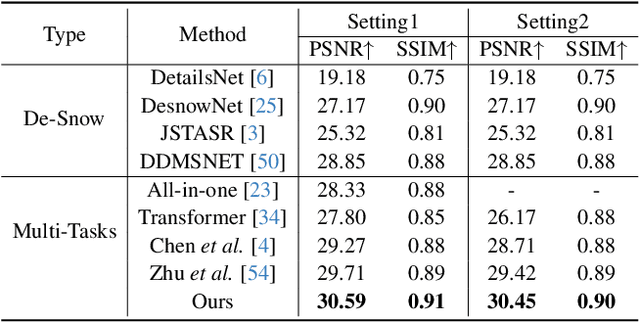
Adverse weather image restoration strives to recover clear images from those affected by various weather types, such as rain, haze, and snow. Each weather type calls for a tailored degradation removal approach due to its unique impact on images. Conversely, content reconstruction can employ a uniform approach, as the underlying image content remains consistent. Although previous techniques can handle multiple weather types within a single network, they neglect the crucial distinction between these two processes, limiting the quality of restored images. This work introduces a novel adverse weather image restoration method, called DDCNet, which decouples the degradation removal and content reconstruction process at the feature level based on their channel statistics. Specifically, we exploit the unique advantages of the Fourier transform in both these two processes: (1) the degradation information is mainly located in the amplitude component of the Fourier domain, and (2) the Fourier domain contains global information. The former facilitates channel-dependent degradation removal operation, allowing the network to tailor responses to various adverse weather types; the latter, by integrating Fourier's global properties into channel-independent content features, enhances network capacity for consistent global content reconstruction. We further augment the degradation removal process with a degradation mapping loss function. Extensive experiments demonstrate our method achieves state-of-the-art performance in multiple adverse weather removal benchmarks.
Double-Flow-based Steganography without Embedding for Image-to-Image Hiding
Nov 25, 2023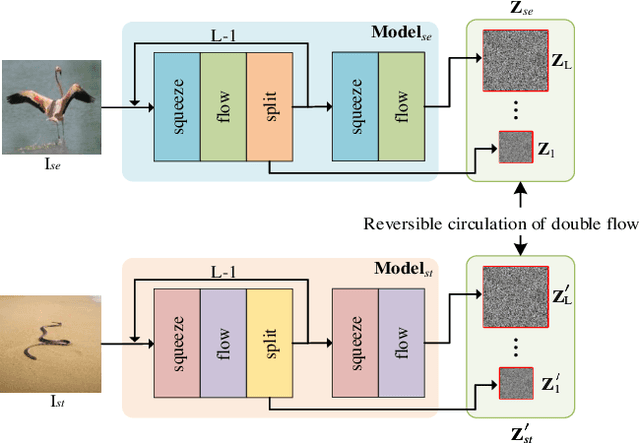

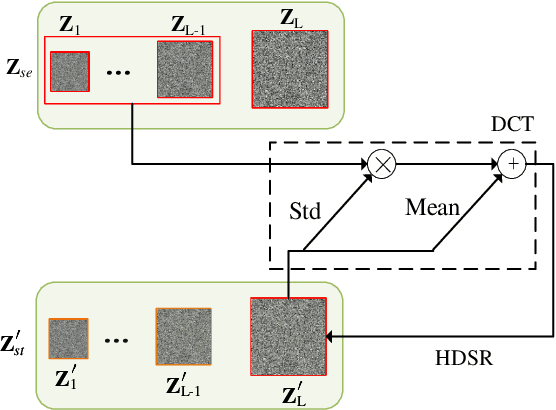
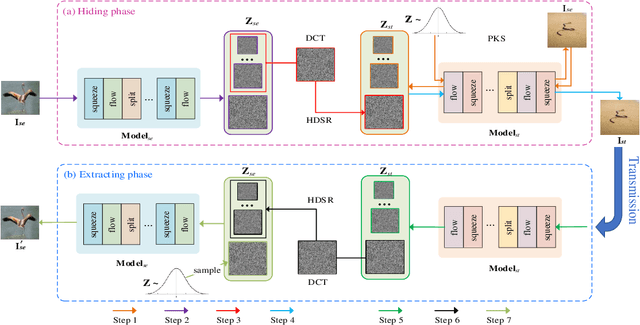
As an emerging concept, steganography without embedding (SWE) hides a secret message without directly embedding it into a cover. Thus, SWE has the unique advantage of being immune to typical steganalysis methods and can better protect the secret message from being exposed. However, existing SWE methods are generally criticized for their poor payload capacity and low fidelity of recovered secret messages. In this paper, we propose a novel steganography-without-embedding technique, named DF-SWE, which addresses the aforementioned drawbacks and produces diverse and natural stego images. Specifically, DF-SWE employs a reversible circulation of double flow to build a reversible bijective transformation between the secret image and the generated stego image. Hence, it provides a way to directly generate stego images from secret images without a cover image. Besides leveraging the invertible property, DF-SWE can invert a secret image from a generated stego image in a nearly lossless manner and increases the fidelity of extracted secret images. To the best of our knowledge, DF-SWE is the first SWE method that can hide large images and multiple images into one image with the same size, significantly enhancing the payload capacity. According to the experimental results, the payload capacity of DF-SWE achieves 24-72 BPP is 8000-16000 times compared to its competitors while producing diverse images to minimize the exposure risk. Importantly, DF-SWE can be applied in the steganography of secret images in various domains without requiring training data from the corresponding domains. This domain-agnostic property suggests that DF-SWE can 1) be applied to hiding private data and 2) be deployed in resource-limited systems.
Adaptive Feature Selection for No-Reference Image Quality Assessment using Contrastive Mitigating Semantic Noise Sensitivity
Dec 11, 2023The current state-of-the-art No-Reference Image Quality Assessment (NR-IQA) methods typically use feature extraction in upstream backbone networks, which assumes that all extracted features are relevant. However, we argue that not all features are beneficial, and some may even be harmful, necessitating careful selection. Empirically, we find that many image pairs with small feature spatial distances can have vastly different quality scores. To address this issue, we propose a Quality-Aware Feature Matching IQA metric(QFM-IQM) that employs contrastive learning to remove harmful features from the upstream task. Specifically, our approach enhances the semantic noise distinguish capabilities of neural networks by comparing image pairs with similar semantic features but varying quality scores and adaptively adjusting the upstream task's features by introducing disturbance. Furthermore, we utilize a distillation framework to expand the dataset and improve the model's generalization ability. Our approach achieves superior performance to the state-of-the-art NR-IQA methods on 8 standard NR-IQA datasets, achieving PLCC values of 0.932 (vs. 0.908 in TID2013) and 0.913 (vs. 0.894 in LIVEC).
SENet: Visual Detection of Online Social Engineering Attack Campaigns
Jan 10, 2024Social engineering (SE) aims at deceiving users into performing actions that may compromise their security and privacy. These threats exploit weaknesses in human's decision making processes by using tactics such as pretext, baiting, impersonation, etc. On the web, SE attacks include attack classes such as scareware, tech support scams, survey scams, sweepstakes, etc., which can result in sensitive data leaks, malware infections, and monetary loss. For instance, US consumers lose billions of dollars annually due to various SE attacks. Unfortunately, generic social engineering attacks remain understudied, compared to other important threats, such as software vulnerabilities and exploitation, network intrusions, malicious software, and phishing. The few existing technical studies that focus on social engineering are limited in scope and mostly focus on measurements rather than developing a generic defense. To fill this gap, we present SEShield, a framework for in-browser detection of social engineering attacks. SEShield consists of three main components: (i) a custom security crawler, called SECrawler, that is dedicated to scouting the web to collect examples of in-the-wild SE attacks; (ii) SENet, a deep learning-based image classifier trained on data collected by SECrawler that aims to detect the often glaring visual traits of SE attack pages; and (iii) SEGuard, a proof-of-concept extension that embeds SENet into the web browser and enables real-time SE attack detection. We perform an extensive evaluation of our system and show that SENet is able to detect new instances of SE attacks with a detection rate of up to 99.6% at 1% false positive, thus providing an effective first defense against SE attacks on the web.
Accurate Leukocyte Detection Based on Deformable-DETR and Multi-Level Feature Fusion for Aiding Diagnosis of Blood Diseases
Jan 10, 2024In standard hospital blood tests, the traditional process requires doctors to manually isolate leukocytes from microscopic images of patients' blood using microscopes. These isolated leukocytes are then categorized via automatic leukocyte classifiers to determine the proportion and volume of different types of leukocytes present in the blood samples, aiding disease diagnosis. This methodology is not only time-consuming and labor-intensive, but it also has a high propensity for errors due to factors such as image quality and environmental conditions, which could potentially lead to incorrect subsequent classifications and misdiagnosis. To address these issues, this paper proposes an innovative method of leukocyte detection: the Multi-level Feature Fusion and Deformable Self-attention DETR (MFDS-DETR). To tackle the issue of leukocyte scale disparity, we designed the High-level Screening-feature Fusion Pyramid (HS-FPN), enabling multi-level fusion. This model uses high-level features as weights to filter low-level feature information via a channel attention module and then merges the screened information with the high-level features, thus enhancing the model's feature expression capability. Further, we address the issue of leukocyte feature scarcity by incorporating a multi-scale deformable self-attention module in the encoder and using the self-attention and cross-deformable attention mechanisms in the decoder, which aids in the extraction of the global features of the leukocyte feature maps. The effectiveness, superiority, and generalizability of the proposed MFDS-DETR method are confirmed through comparisons with other cutting-edge leukocyte detection models using the private WBCDD, public LISC and BCCD datasets. Our source code and private WBCCD dataset are available at https://github.com/JustlfC03/MFDS-DETR.
* 15 pages, 11 figures, accept Computers in Biology and Medicine 2024
AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
Dec 10, 2023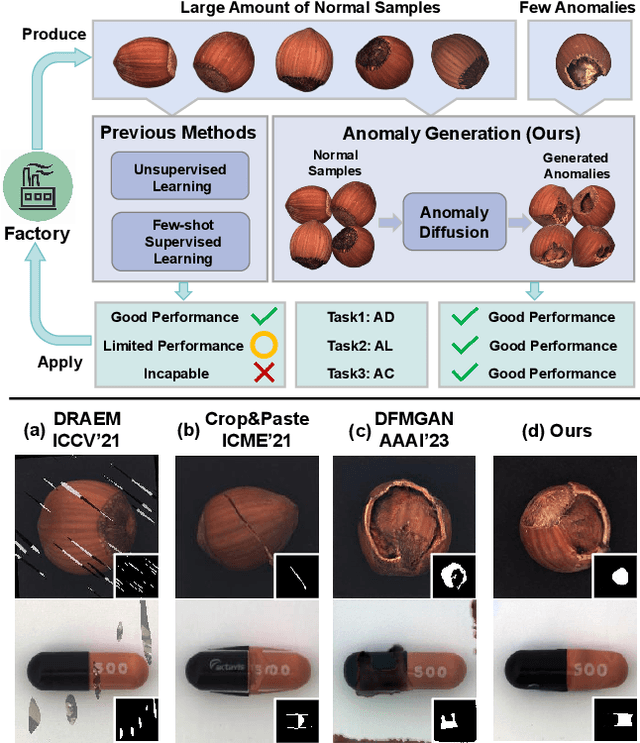
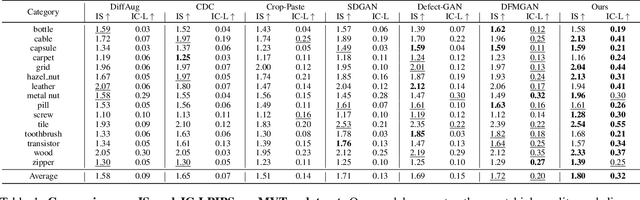
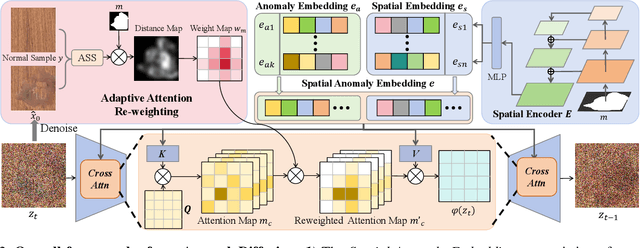
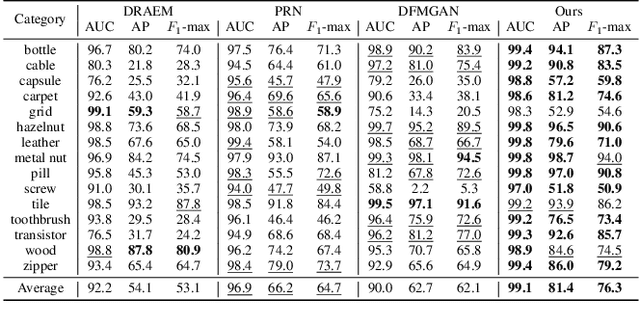
Anomaly inspection plays an important role in industrial manufacture. Existing anomaly inspection methods are limited in their performance due to insufficient anomaly data. Although anomaly generation methods have been proposed to augment the anomaly data, they either suffer from poor generation authenticity or inaccurate alignment between the generated anomalies and masks. To address the above problems, we propose AnomalyDiffusion, a novel diffusion-based few-shot anomaly generation model, which utilizes the strong prior information of latent diffusion model learned from large-scale dataset to enhance the generation authenticity under few-shot training data. Firstly, we propose Spatial Anomaly Embedding, which consists of a learnable anomaly embedding and a spatial embedding encoded from an anomaly mask, disentangling the anomaly information into anomaly appearance and location information. Moreover, to improve the alignment between the generated anomalies and the anomaly masks, we introduce a novel Adaptive Attention Re-weighting Mechanism. Based on the disparities between the generated anomaly image and normal sample, it dynamically guides the model to focus more on the areas with less noticeable generated anomalies, enabling generation of accurately-matched anomalous image-mask pairs. Extensive experiments demonstrate that our model significantly outperforms the state-of-the-art methods in generation authenticity and diversity, and effectively improves the performance of downstream anomaly inspection tasks. The code and data are available in https://github.com/sjtuplayer/anomalydiffusion.
NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single Image
Dec 12, 2023Transfer learning of large-scale Text-to-Image (T2I) models has recently shown impressive potential for Novel View Synthesis (NVS) of diverse objects from a single image. While previous methods typically train large models on multi-view datasets for NVS, fine-tuning the whole parameters of T2I models not only demands a high cost but also reduces the generalization capacity of T2I models in generating diverse images in a new domain. In this study, we propose an effective method, dubbed NVS-Adapter, which is a plug-and-play module for a T2I model, to synthesize novel multi-views of visual objects while fully exploiting the generalization capacity of T2I models. NVS-Adapter consists of two main components; view-consistency cross-attention learns the visual correspondences to align the local details of view features, and global semantic conditioning aligns the semantic structure of generated views with the reference view. Experimental results demonstrate that the NVS-Adapter can effectively synthesize geometrically consistent multi-views and also achieve high performance on benchmarks without full fine-tuning of T2I models. The code and data are publicly available in ~\href{https://postech-cvlab.github.io/nvsadapter/}{https://postech-cvlab.github.io/nvsadapter/}.