 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Ice Layer Tracking and Thickness Estimation using Fully Convolutional Networks
Sep 01, 2020

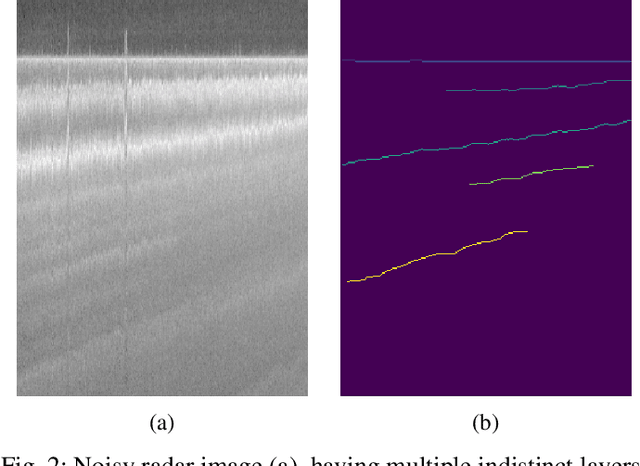
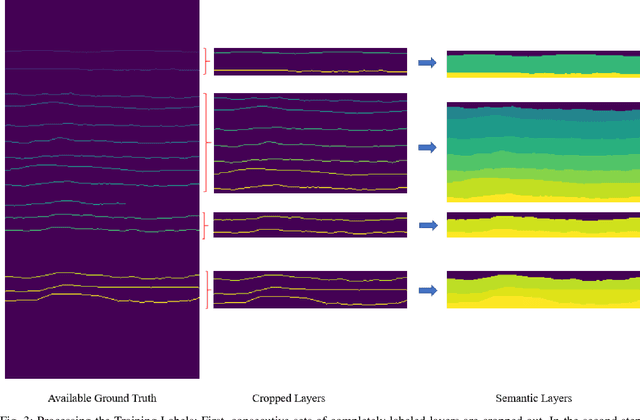

Global warming is rapidly reducing glaciers and ice sheets across the world. Real time assessment of this reduction is required so as to monitor its global climatic impact. In this paper, we introduce a novel way of estimating the thickness of each internal ice layer using Snow Radar images and Fully Convolutional Networks. The estimated thickness can be analysed to understand snow accumulation each year. To understand the depth and structure of each internal ice layer, we carry out a set of image processing techniques and perform semantic segmentation on the radar images. After detecting each ice layer uniquely, we calculate its thickness and compare it with the available ground truth. Through this procedure we were able to estimate the ice layer thicknesses within a Mean Absolute Error of approximately 3.6 pixels. Such a Deep Learning based method can be used with ever-increasing datasets to make accurate assessments for cryospheric studies.
Beyond Weak Perspective for Monocular 3D Human Pose Estimation
Sep 14, 2020
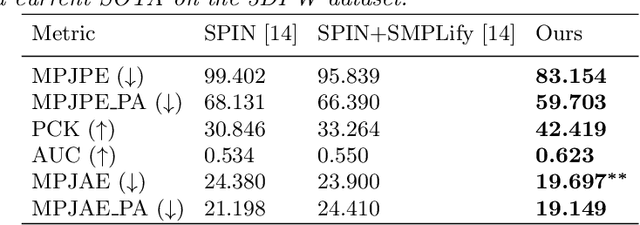
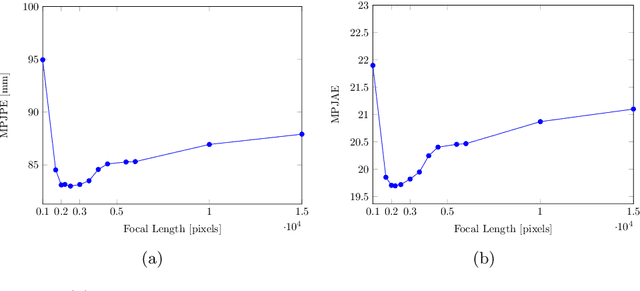
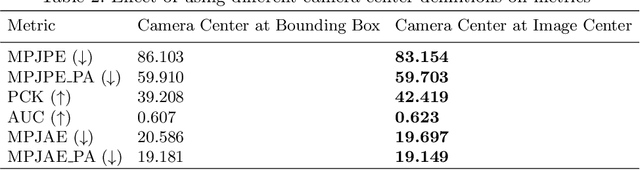
We consider the task of 3D joints location and orientation prediction from a monocular video with the skinned multi-person linear (SMPL) model. We first infer 2D joints locations with an off-the-shelf pose estimation algorithm. We use the SPIN algorithm and estimate initial predictions of body pose, shape and camera parameters from a deep regression neural network. We then adhere to the SMPLify algorithm which receives those initial parameters, and optimizes them so that inferred 3D joints from the SMPL model would fit the 2D joints locations. This algorithm involves a projection step of 3D joints to the 2D image plane. The conventional approach is to follow weak perspective assumptions which use ad-hoc focal length. Through experimentation on the 3D Poses in the Wild (3DPW) dataset, we show that using full perspective projection, with the correct camera center and an approximated focal length, provides favorable results. Our algorithm has resulted in a winning entry for the 3DPW Challenge, reaching first place in joints orientation accuracy.
Object-QA: Towards High Reliable Object Quality Assessment
May 27, 2020
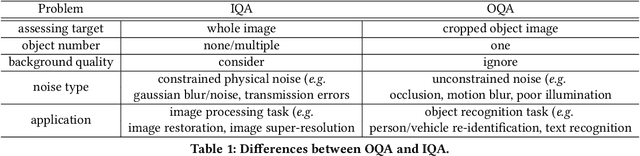
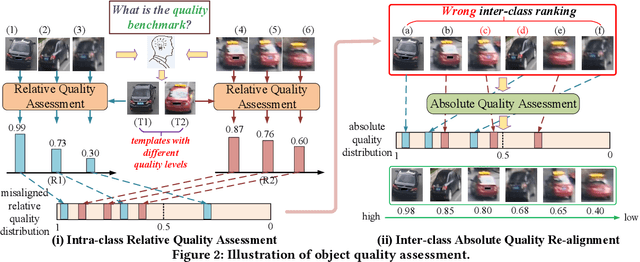
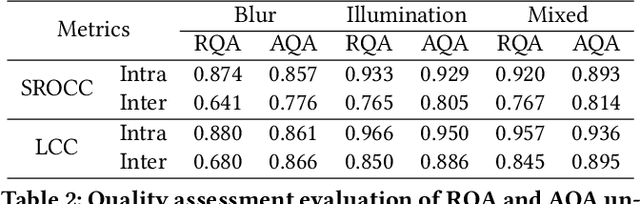
In object recognition applications, object images usually appear with different quality levels. Practically, it is very important to indicate object image qualities for better application performance, e.g. filtering out low-quality object image frames to maintain robust video object recognition results and speed up inference. However, no previous works are explicitly proposed for addressing the problem. In this paper, we define the problem of object quality assessment for the first time and propose an effective approach named Object-QA to assess high-reliable quality scores for object images. Concretely, Object-QA first employs a well-designed relative quality assessing module that learns the intra-class-level quality scores by referring to the difference between object images and their estimated templates. Then an absolute quality assessing module is designed to generate the final quality scores by aligning the quality score distributions in inter-class. Besides, Object-QA can be implemented with only object-level annotations, and is also easily deployed to a variety of object recognition tasks. To our best knowledge this is the first work to put forward the definition of this problem and conduct quantitative evaluations. Validations on 5 different datasets show that Object-QA can not only assess high-reliable quality scores according with human cognition, but also improve application performance.
Few-Shot Image Recognition by Predicting Parameters from Activations
Nov 25, 2017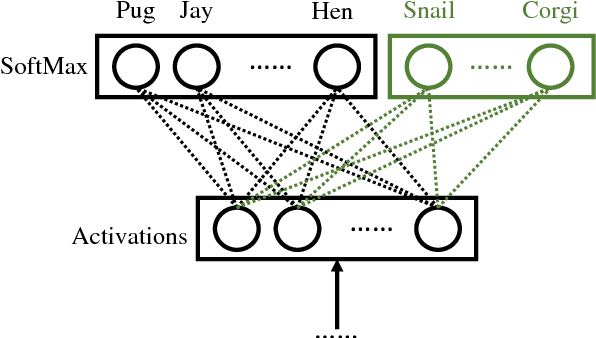
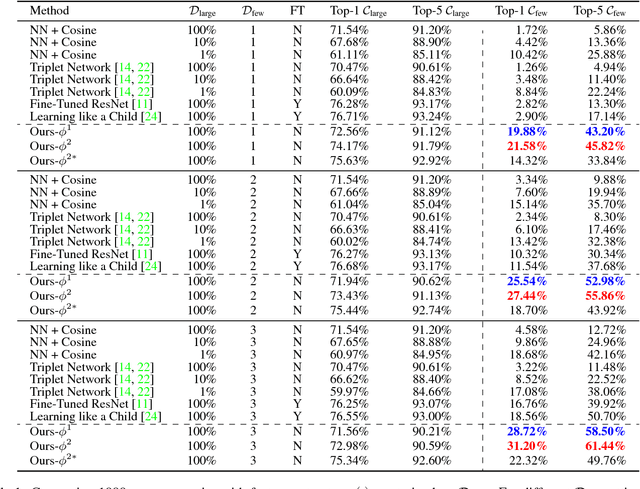
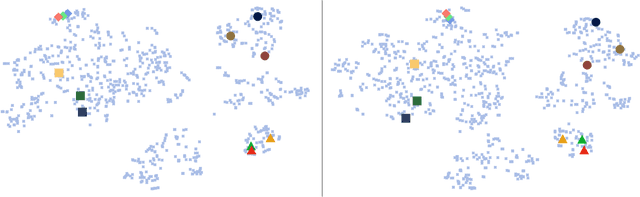
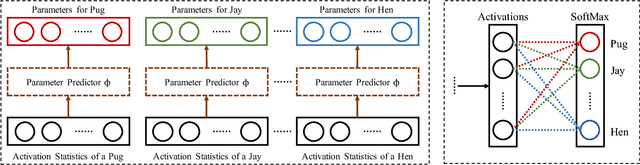
In this paper, we are interested in the few-shot learning problem. In particular, we focus on a challenging scenario where the number of categories is large and the number of examples per novel category is very limited, e.g. 1, 2, or 3. Motivated by the close relationship between the parameters and the activations in a neural network associated with the same category, we propose a novel method that can adapt a pre-trained neural network to novel categories by directly predicting the parameters from the activations. Zero training is required in adaptation to novel categories, and fast inference is realized by a single forward pass. We evaluate our method by doing few-shot image recognition on the ImageNet dataset, which achieves the state-of-the-art classification accuracy on novel categories by a significant margin while keeping comparable performance on the large-scale categories. We also test our method on the MiniImageNet dataset and it strongly outperforms the previous state-of-the-art methods.
Optimization of Structural Similarity in Mathematical Imaging
Feb 07, 2020
It is now generally accepted that Euclidean-based metrics may not always adequately represent the subjective judgement of a human observer. As a result, many image processing methodologies have been recently extended to take advantage of alternative visual quality measures, the most prominent of which is the Structural Similarity Index Measure (SSIM). The superiority of the latter over Euclidean-based metrics have been demonstrated in several studies. However, being focused on specific applications, the findings of such studies often lack generality which, if otherwise acknowledged, could have provided a useful guidance for further development of SSIM-based image processing algorithms. Accordingly, instead of focusing on a particular image processing task, in this paper, we introduce a general framework that encompasses a wide range of imaging applications in which the SSIM can be employed as a fidelity measure. Subsequently, we show how the framework can be used to cast some standard as well as original imaging tasks into optimization problems, followed by a discussion of a number of novel numerical strategies for their solution.
BlockGAN: Learning 3D Object-aware Scene Representations from Unlabelled Images
Feb 20, 2020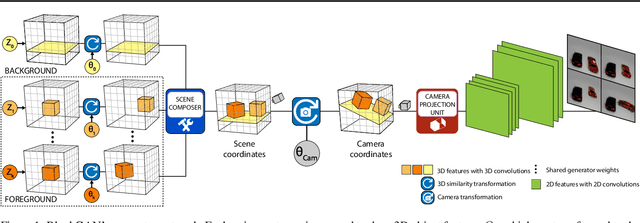

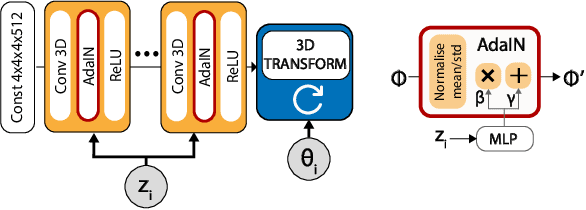

We present BlockGAN, an image generative model that learns object-aware 3D scene representations directly from unlabelled 2D images. Current work on scene representation learning either ignores scene background or treats the whole scene as one object. Meanwhile, work that considers scene compositionality treats scene objects only as image patches or 2D layers with alpha maps. Inspired by the computer graphics pipeline, we design BlockGAN to learn to first generate 3D features of background and foreground objects, then combine them into 3D features for the wholes cene, and finally render them into realistic images. This allows BlockGAN to reason over occlusion and interaction between objects' appearance, such as shadow and lighting, and provides control over each object's 3D pose and identity, while maintaining image realism. BlockGAN is trained end-to-end, using only unlabelled single images, without the need for 3D geometry, pose labels, object masks, or multiple views of the same scene. Our experiments show that using explicit 3D features to represent objects allows BlockGAN to learn disentangled representations both in terms of objects (foreground and background) and their properties (pose and identity).
RADIATE: A Radar Dataset for Automotive Perception
Oct 18, 2020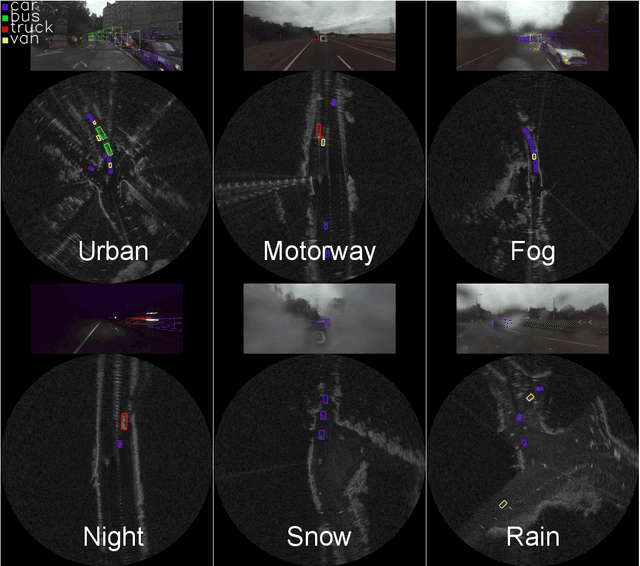

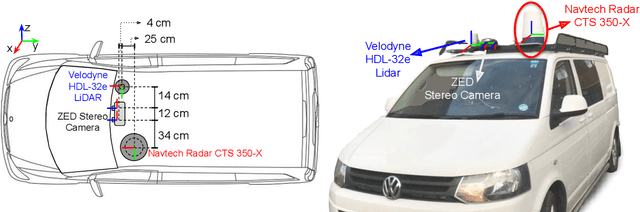
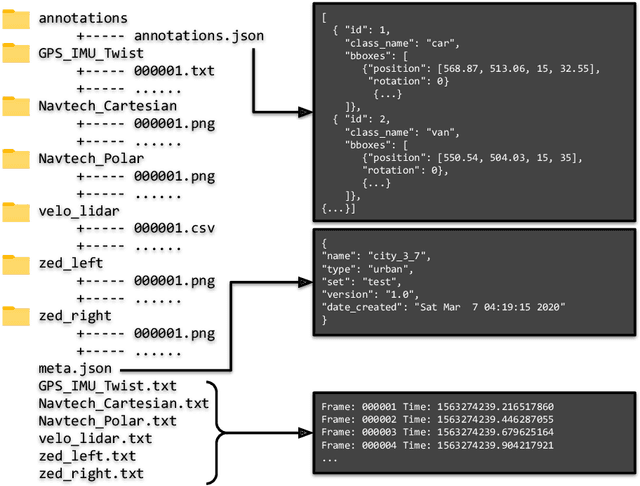
Datasets for autonomous cars are essential for the development and benchmarking of perception systems. However, most existing datasets are captured with camera and LiDAR sensors in good weather conditions. In this paper, we present the RAdar Dataset In Adverse weaThEr (RADIATE), aiming to facilitate research on object detection, tracking and scene understanding using radar sensing for safe autonomous driving. RADIATE includes 3 hours of annotated radar images with more than 200K labelled road actors in total, on average about 4.6 instances per radar image. It covers 8 different categories of actors in a variety of weather conditions (e.g., sun, night, rain, fog and snow) and driving scenarios (e.g., parked, urban, motorway and suburban), representing different levels of challenge. To the best of our knowledge, this is the first public radar dataset which provides high-resolution radar images on public roads with a large amount of road actors labelled. The data collected in adverse weather, e.g., fog and snowfall, is unique. Some baseline results of radar based object detection and recognition are given to show that the use of radar data is promising for automotive applications in bad weather, where vision and LiDAR can fail. RADIATE also has stereo images, 32-channel LiDAR and GPS data, directed at other applications such as sensor fusion, localisation and mapping. The public dataset can be accessed at http://pro.hw.ac.uk/radiate/.
Reinforced Axial Refinement Network for Monocular 3D Object Detection
Aug 31, 2020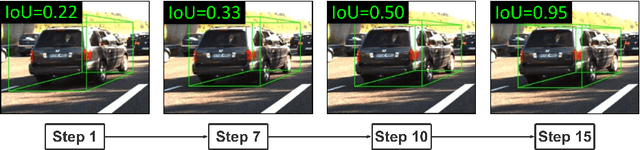
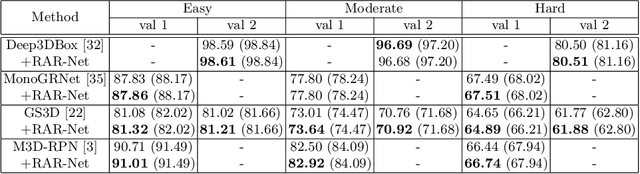
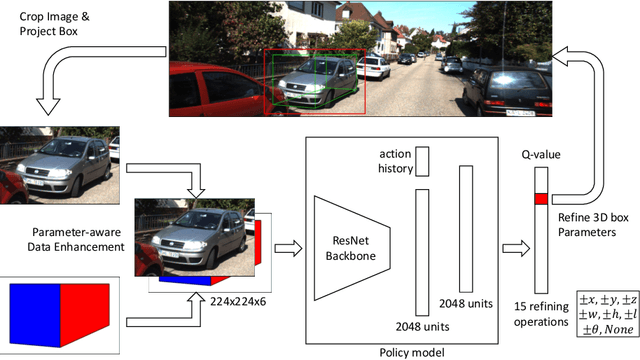
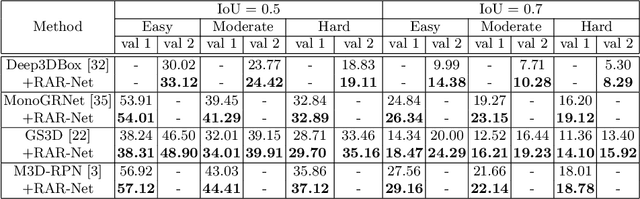
Monocular 3D object detection aims to extract the 3D position and properties of objects from a 2D input image. This is an ill-posed problem with a major difficulty lying in the information loss by depth-agnostic cameras. Conventional approaches sample 3D bounding boxes from the space and infer the relationship between the target object and each of them, however, the probability of effective samples is relatively small in the 3D space. To improve the efficiency of sampling, we propose to start with an initial prediction and refine it gradually towards the ground truth, with only one 3d parameter changed in each step. This requires designing a policy which gets a reward after several steps, and thus we adopt reinforcement learning to optimize it. The proposed framework, Reinforced Axial Refinement Network (RAR-Net), serves as a post-processing stage which can be freely integrated into existing monocular 3D detection methods, and improve the performance on the KITTI dataset with small extra computational costs.
Transfer Learning for Protein Structure Classification at Low Resolution
Aug 31, 2020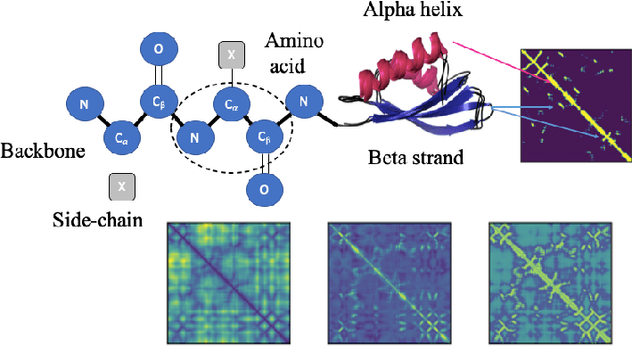
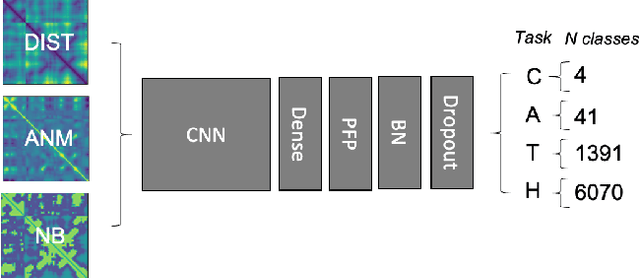
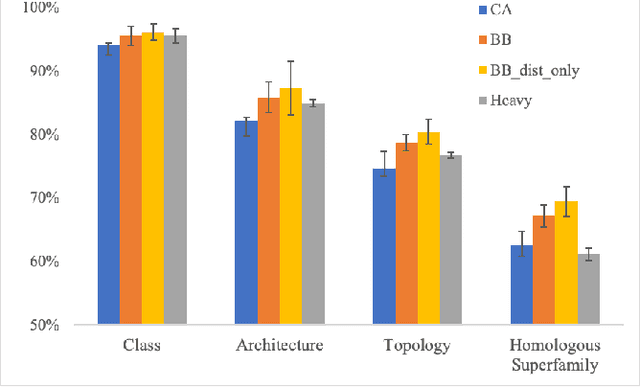

Structure determination is key to understanding protein function at a molecular level. Whilst significant advances have been made in predicting structure and function from amino acid sequence, researchers must still rely on expensive, time-consuming analytical methods to visualise detailed protein conformation. In this study, we demonstrate that it is possible to make accurate ($\geq$80%) predictions of protein class and architecture from structures determined at low ($>$3A) resolution, using a deep convolutional neural network trained on high-resolution ($\leq$3A) structures represented as 2D matrices. Thus, we provide proof of concept for high-speed, low-cost protein structure classification at low resolution, and a basis for extension to prediction of function. We investigate the impact of the input representation on classification performance, showing that side-chain information may not be necessary for fine-grained structure predictions. Finally, we confirm that high-resolution, low-resolution and NMR-determined structures inhabit a common feature space, and thus provide a theoretical foundation for boosting with single-image super-resolution.
VD-BERT: A Unified Vision and Dialog Transformer with BERT
Apr 29, 2020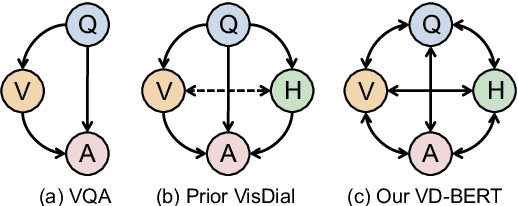
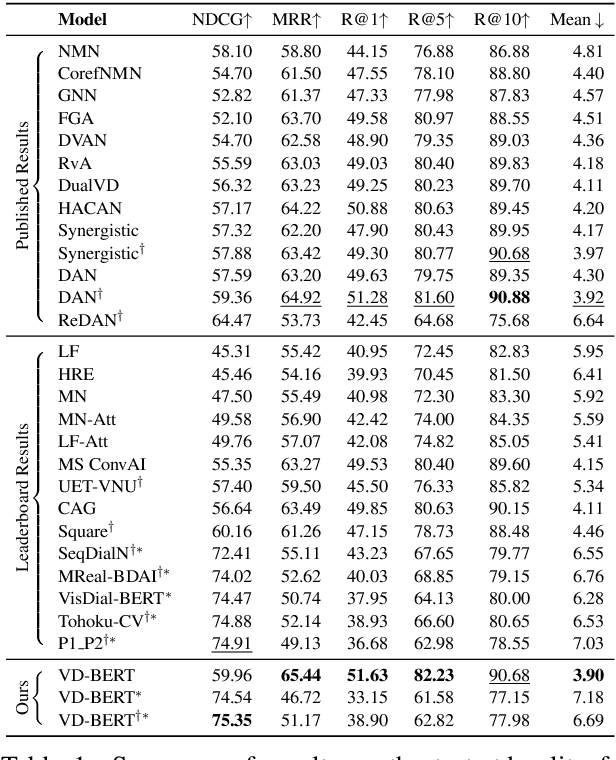
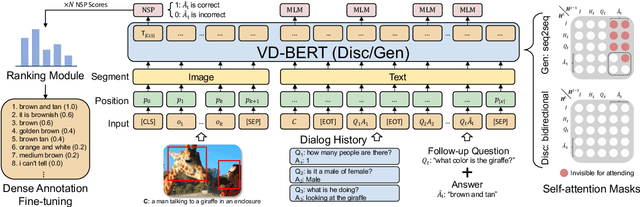
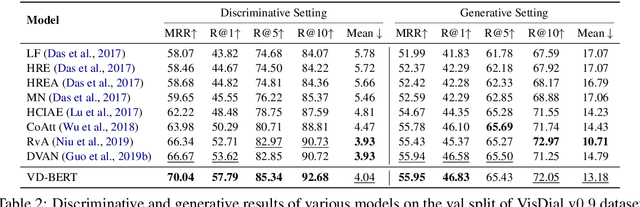
Visual dialog is a challenging vision-language task, where a dialog agent needs to answer a series of questions through reasoning on the image content and dialog history. Prior work has mostly focused on various attention mechanisms to model such intricate interactions. By contrast, in this work, we propose VD-BERT, a simple yet effective framework of unified vision-dialog Transformer that leverages the pretrained BERT language models for Visual Dialog tasks. The model is unified in that (1) it captures all the interactions between the image and the multi-turn dialog using a single-stream Transformer encoder, and (2) it supports both answer ranking and answer generation seamlessly through the same architecture. More crucially, we adapt BERT for the effective fusion of vision and dialog contents via visually grounded training. Without the need of pretraining on external vision-language data, our model yields new state of the art, achieving the top position in both single-model and ensemble settings (74.54 and 75.35 NDCG scores) on the visual dialog leaderboard.