 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVD-BERT: A Unified Vision and Dialog Transformer with BERT
Paper and Code
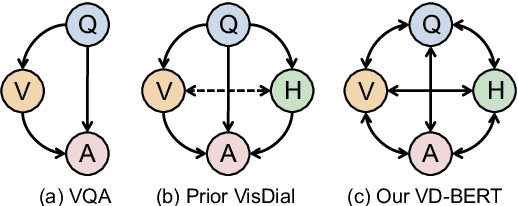
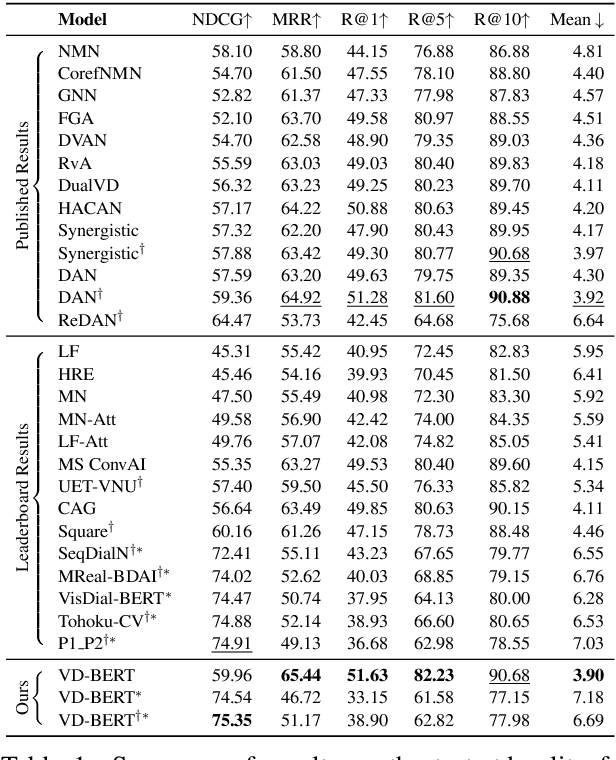
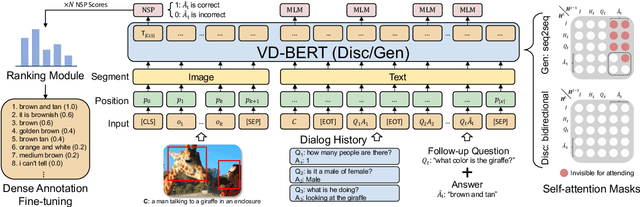
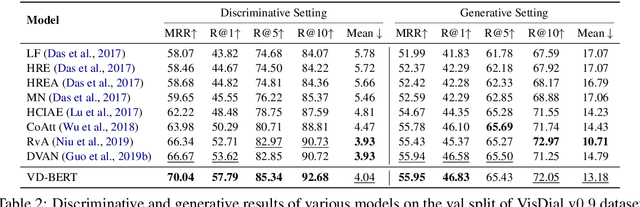
Visual dialog is a challenging vision-language task, where a dialog agent needs to answer a series of questions through reasoning on the image content and dialog history. Prior work has mostly focused on various attention mechanisms to model such intricate interactions. By contrast, in this work, we propose VD-BERT, a simple yet effective framework of unified vision-dialog Transformer that leverages the pretrained BERT language models for Visual Dialog tasks. The model is unified in that (1) it captures all the interactions between the image and the multi-turn dialog using a single-stream Transformer encoder, and (2) it supports both answer ranking and answer generation seamlessly through the same architecture. More crucially, we adapt BERT for the effective fusion of vision and dialog contents via visually grounded training. Without the need of pretraining on external vision-language data, our model yields new state of the art, achieving the top position in both single-model and ensemble settings (74.54 and 75.35 NDCG scores) on the visual dialog leaderboard.