 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stochastic Frequency Masking to Improve Super-Resolution and Denoising Networks
Mar 16, 2020
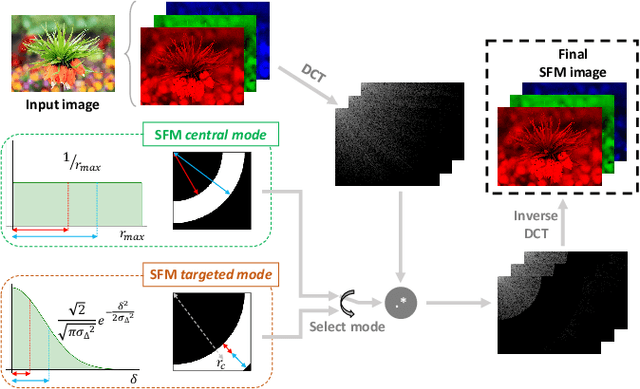

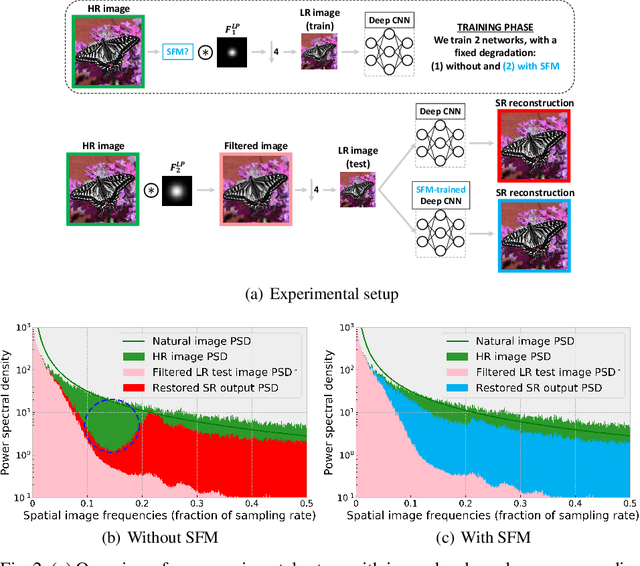
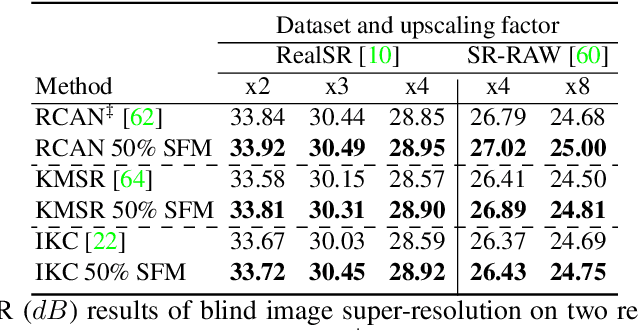
Super-resolution and denoising are ill-posed yet fundamental image restoration tasks. In blind settings, the degradation kernel or the noise level are unknown. This makes restoration even more challenging, notably for learning-based methods, as they tend to overfit to the degradation seen during training. We present an analysis, in the frequency domain, of degradation-kernel overfitting in super-resolution and introduce a conditional learning perspective that extends to both super-resolution and denoising. Building on our formulation, we propose a stochastic frequency masking of images used in training to regularize the networks and address the overfitting problem. Our technique improves state-of-the-art methods on blind super-resolution with different synthetic kernels, real super-resolution, blind Gaussian denoising, and real-image denoising.
Self-supervised Feature Learning by Cross-modality and Cross-view Correspondences
Apr 13, 2020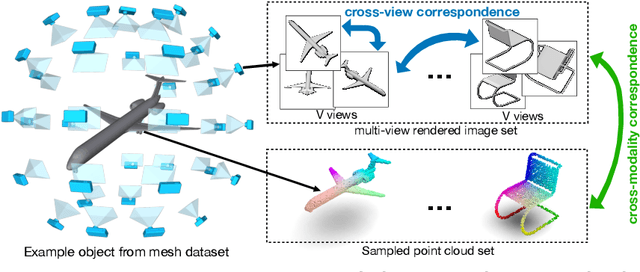

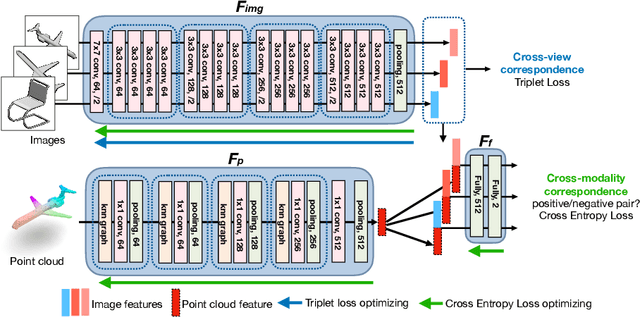

The success of supervised learning requires large-scale ground truth labels which are very expensive, time-consuming, or may need special skills to annotate. To address this issue, many self- or un-supervised methods are developed. Unlike most existing self-supervised methods to learn only 2D image features or only 3D point cloud features, this paper presents a novel and effective self-supervised learning approach to jointly learn both 2D image features and 3D point cloud features by exploiting cross-modality and cross-view correspondences without using any human annotated labels. Specifically, 2D image features of rendered images from different views are extracted by a 2D convolutional neural network, and 3D point cloud features are extracted by a graph convolution neural network. Two types of features are fed into a two-layer fully connected neural network to estimate the cross-modality correspondence. The three networks are jointly trained (i.e. cross-modality) by verifying whether two sampled data of different modalities belong to the same object, meanwhile, the 2D convolutional neural network is additionally optimized through minimizing intra-object distance while maximizing inter-object distance of rendered images in different views (i.e. cross-view). The effectiveness of the learned 2D and 3D features is evaluated by transferring them on five different tasks including multi-view 2D shape recognition, 3D shape recognition, multi-view 2D shape retrieval, 3D shape retrieval, and 3D part-segmentation. Extensive evaluations on all the five different tasks across different datasets demonstrate strong generalization and effectiveness of the learned 2D and 3D features by the proposed self-supervised method.
Incorrect by Construction: Fine Tuning Neural Networks for Guaranteed Performance on Finite Sets of Examples
Aug 03, 2020
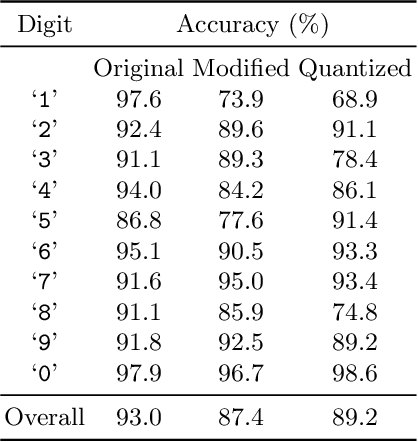
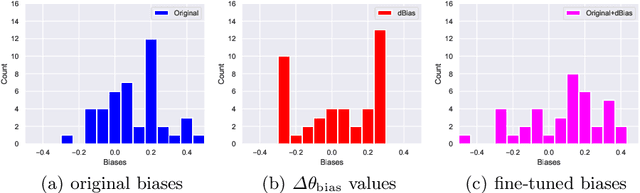
There is great interest in using formal methods to guarantee the reliability of deep neural networks. However, these techniques may also be used to implant carefully selected input-output pairs. We present initial results on a novel technique for using SMT solvers to fine tune the weights of a ReLU neural network to guarantee outcomes on a finite set of particular examples. This procedure can be used to ensure performance on key examples, but it could also be used to insert difficult-to-find incorrect examples that trigger unexpected performance. We demonstrate this approach by fine tuning an MNIST network to incorrectly classify a particular image and discuss the potential for the approach to compromise reliability of freely-shared machine learning models.
Robots of the Lost Arc: Learning to Dynamically Manipulate Fixed-Endpoint Ropes and Cables
Nov 10, 2020



High-speed arm motions can dynamically manipulate ropes and cables to vault over obstacles, knock objects from pedestals, and weave between obstacles. In this paper, we propose a self-supervised learning pipeline that enables a UR5 robot to perform these three tasks. The pipeline trains a deep convolutional neural network that takes as input an image of the scene with object and target. It computes a 3D apex point for the robot arm, which, together with a task-specific trajectory function, defines an arcing motion for a manipulator arm to dynamically manipulate the cable to perform a task with varying obstacle and target locations. The trajectory function computes high-speed minimum-jerk arcing motions that are constrained to remain within joint limits and to travel through the 3D apex point by repeatedly solving quadratic programs for shorter time horizons to find the shortest and fastest feasible motion. We experiment with the proposed pipeline on 5 physical cables with different thickness and mass and compare performance with two baselines in which a human chooses the apex point. Results suggest that the robot using the learned apex point can achieve success rates of 81.7% in vaulting, 65.0% in knocking, and 60.0% in weaving, while a baseline with a fixed apex across the three tasks achieves respective success rates of 51.7%, 36.7%, and 15.0%, and a baseline with human-specified task-specific apex points achieves 66.7%, 56.7%, and 15.0% success rate respectively. Code, data, and supplementary materials are available at https: //sites.google.com/berkeley.edu/dynrope/home
Decoupling Representation Learning from Reinforcement Learning
Sep 30, 2020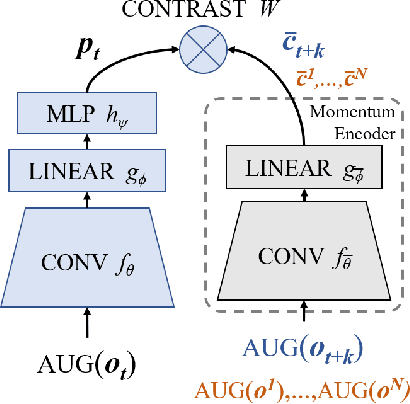

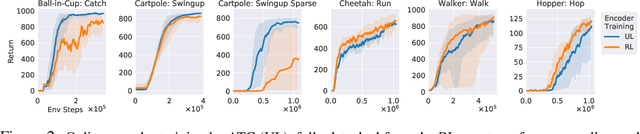
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at https://github.com/astooke/rlpyt/tree/master/rlpyt/ul.
Articulation-aware Canonical Surface Mapping
Apr 02, 2020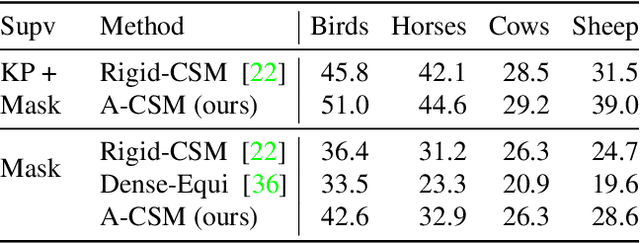
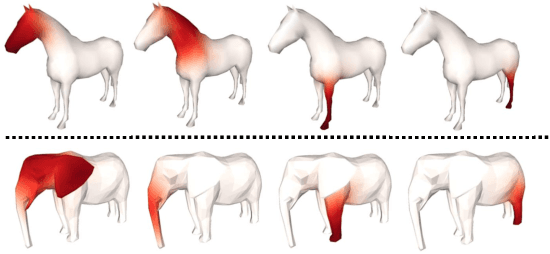
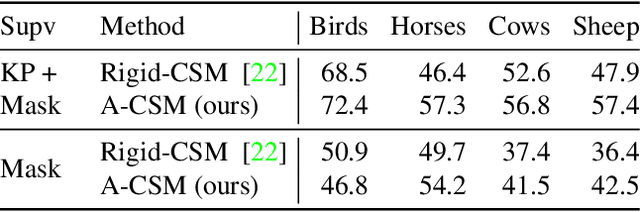
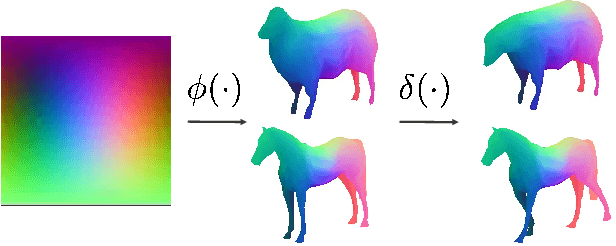
We tackle the tasks of: 1) predicting a Canonical Surface Mapping (CSM) that indicates the mapping from 2D pixels to corresponding points on a canonical template shape, and 2) inferring the articulation and pose of the template corresponding to the input image. While previous approaches rely on keypoint supervision for learning, we present an approach that can learn without such annotations. Our key insight is that these tasks are geometrically related, and we can obtain supervisory signal via enforcing consistency among the predictions. We present results across a diverse set of animal object categories, showing that our method can learn articulation and CSM prediction from image collections using only foreground mask labels for training. We empirically show that allowing articulation helps learn more accurate CSM prediction, and that enforcing the consistency with predicted CSM is similarly critical for learning meaningful articulation.
Bimanual Regrasping for Suture Needles using Reinforcement Learning for Rapid Motion Planning
Nov 09, 2020
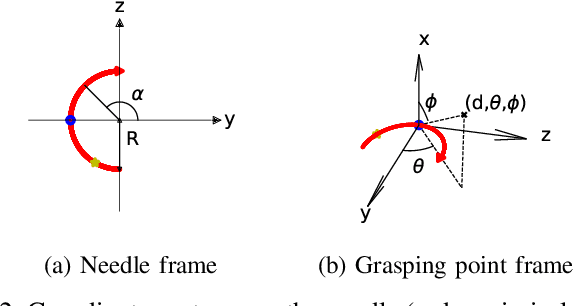
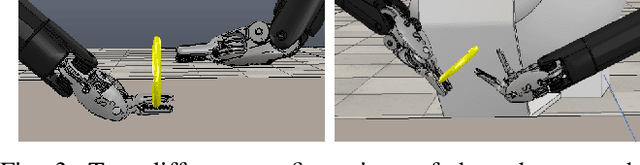
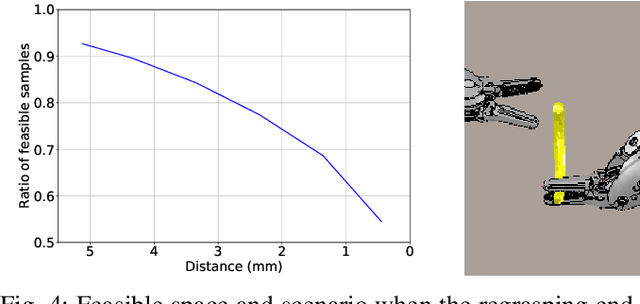
Regrasping a suture needle is an important process in suturing, and previous study has shown that it takes on average 7.4s before the needle is thrown again. To bring efficiency into suturing, prior work either designs a task-specific mechanism or guides the gripper toward some specific pick-up point for proper grasping of a needle. Yet, these methods are usually not deployable when the working space is changed. These prior efforts highlight the need for more efficient regrasping and more generalizability of a proposed method. Therefore, in this work, we present rapid trajectory generation for bimanual needle regrasping via reinforcement learning (RL). Demonstrations from a sampling-based motion planning algorithm is incorporated to speed up the learning. In addition, we propose the ego-centric state and action spaces for this bimanual planning problem, where the reference frames are on the end-effectors instead of some fixed frame. Thus, the learned policy can be directly applied to any robot configuration and even to different robot arms. Our experiments in simulation show that the success rate of a single pass is 97%, and the planning time is 0.0212s on average, which outperforms other widely used motion planning algorithms. For the real-world experiments, the success rate is 73.3% if the needle pose is reconstructed from an RGB image, with a planning time of 0.0846s and a run time of 5.1454s. If the needle pose is known beforehand, the success rate becomes 90.5%, with a planning time of 0.0807s and a run time of 2.8801s.
Guiding Long-Short Term Memory for Image Caption Generation
Sep 16, 2015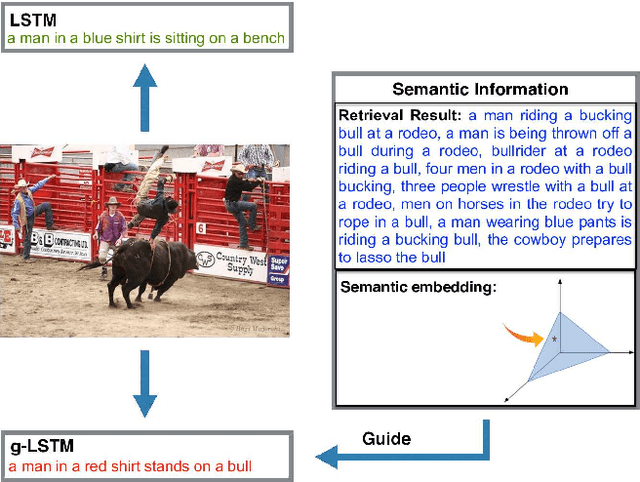
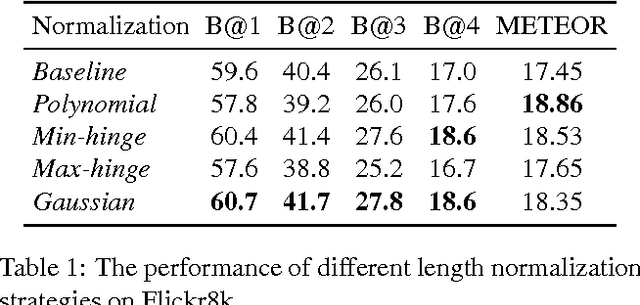
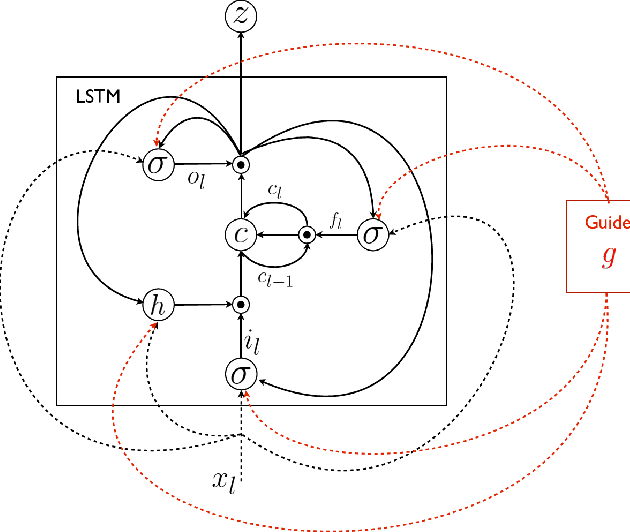

In this work we focus on the problem of image caption generation. We propose an extension of the long short term memory (LSTM) model, which we coin gLSTM for short. In particular, we add semantic information extracted from the image as extra input to each unit of the LSTM block, with the aim of guiding the model towards solutions that are more tightly coupled to the image content. Additionally, we explore different length normalization strategies for beam search in order to prevent from favoring short sentences. On various benchmark datasets such as Flickr8K, Flickr30K and MS COCO, we obtain results that are on par with or even outperform the current state-of-the-art.
Improving Self-Organizing Maps with Unsupervised Feature Extraction
Sep 04, 2020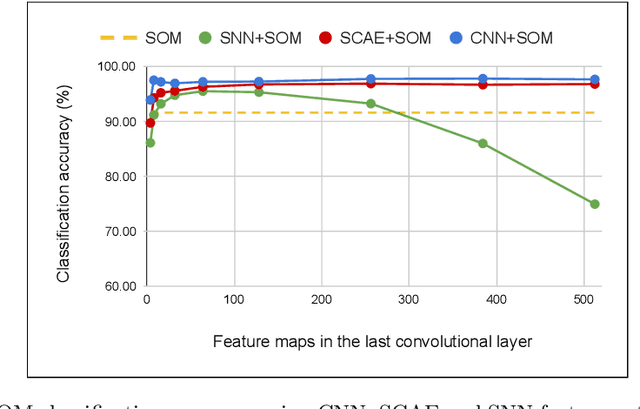

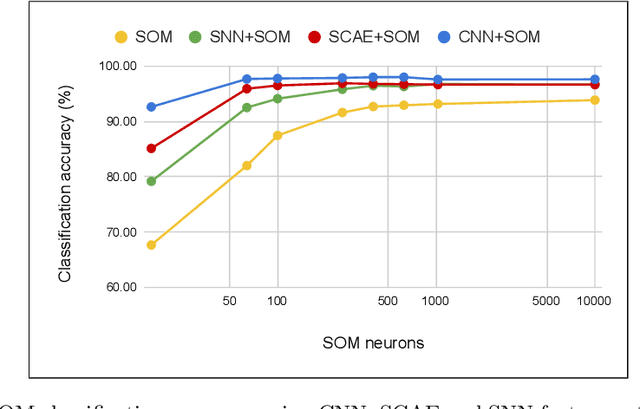

The Self-Organizing Map (SOM) is a brain-inspired neural model that is very promising for unsupervised learning, especially in embedded applications. However, it is unable to learn efficient prototypes when dealing with complex datasets. We propose in this work to improve the SOM performance by using extracted features instead of raw data. We conduct a comparative study on the SOM classification accuracy with unsupervised feature extraction using two different approaches: a machine learning approach with Sparse Convolutional Auto-Encoders using gradient-based learning, and a neuroscience approach with Spiking Neural Networks using Spike Timing Dependant Plasticity learning. The SOM is trained on the extracted features, then very few labeled samples are used to label the neurons with their corresponding class. We investigate the impact of the feature maps, the SOM size and the labeled subset size on the classification accuracy using the different feature extraction methods. We improve the SOM classification by +6.09\% and reach state-of-the-art performance on unsupervised image classification.
S3K: Self-Supervised Semantic Keypoints for Robotic Manipulation via Multi-View Consistency
Sep 30, 2020

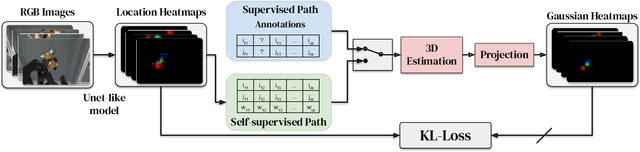
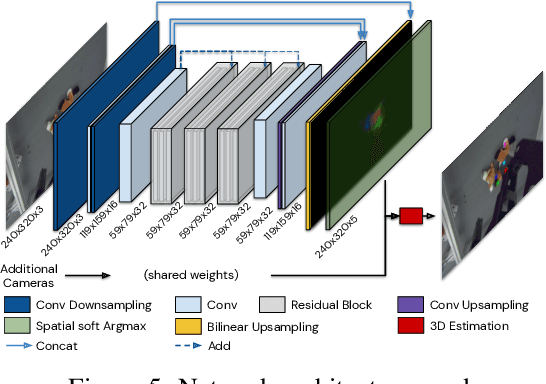
A robot's ability to act is fundamentally constrained by what it can perceive. Many existing approaches to visual representation learning utilize general-purpose training criteria, e.g. image reconstruction, smoothness in latent space, or usefulness for control, or else make use of large datasets annotated with specific features (bounding boxes, segmentations, etc.). However, both approaches often struggle to capture the fine-detail required for precision tasks on specific objects, e.g. grasping and mating a plug and socket. We argue that these difficulties arise from a lack of geometric structure in these models. In this work we advocate semantic 3D keypoints as a visual representation, and present a semi-supervised training objective that can allow instance or category-level keypoints to be trained to 1-5 millimeter-accuracy with minimal supervision. Furthermore, unlike local texture-based approaches, our model integrates contextual information from a large area and is therefore robust to occlusion, noise, and lack of discernible texture. We demonstrate that this ability to locate semantic keypoints enables high level scripting of human understandable behaviours. Finally we show that these keypoints provide a good way to define reward functions for reinforcement learning and are a good representation for training agents.