 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Super-resolution Reconstruction Network based on Enhanced Swin Transformer via Alternating Aggregation of Local-Global Features
Dec 30, 2023
The Swin Transformer image super-resolution reconstruction network only relies on the long-range relationship of window attention and shifted window attention to explore features. This mechanism has two limitations. On the one hand, it only focuses on global features while ignoring local features. On the other hand, it is only concerned with spatial feature interactions while ignoring channel features and channel interactions, thus limiting its non-linear mapping ability. To address the above limitations, this paper proposes enhanced Swin Transformer modules via alternating aggregation of local-global features. In the local feature aggregation stage, this paper introduces shift convolution to realize the interaction between local spatial information and channel information. This paper proposes a block sparse global perception module in the global feature aggregation stage. This module organizes the spatial information first, then sends the recombination information into a spatial gating unit to implement the further interaction of spatial and channel information. Then, a multi-scale self-attention module and a low-parameter residual channel attention module are introduced to realize information aggregation at different scales. Finally, the proposed network is validated on five publicly available datasets. The experimental results show that the proposed network outperforms the other state-of-the-art super-resolution networks.
EditGuard: Versatile Image Watermarking for Tamper Localization and Copyright Protection
Dec 12, 2023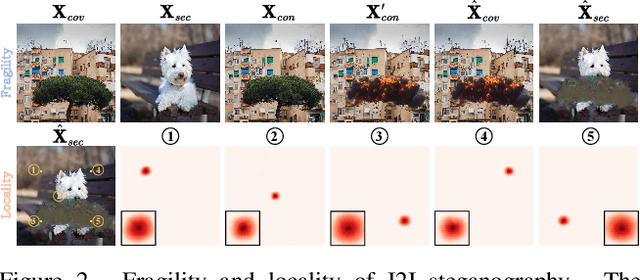
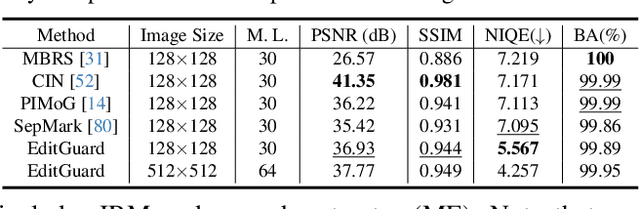
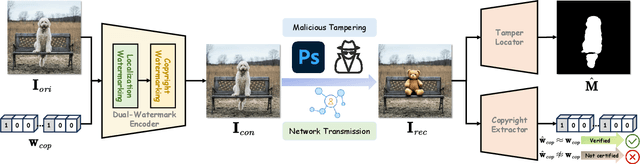
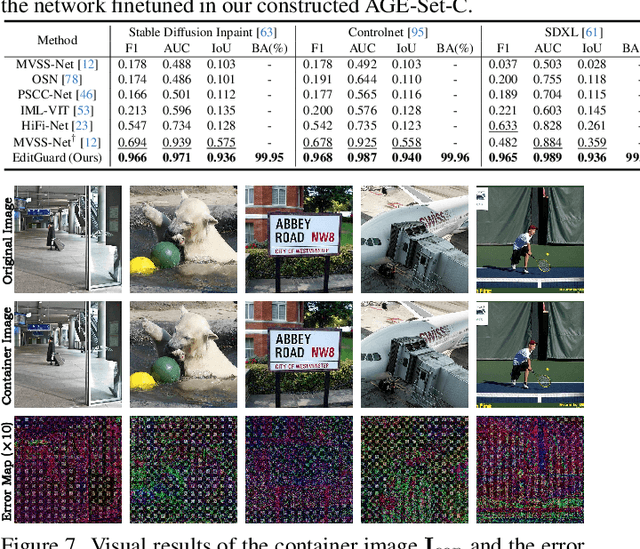
In the era where AI-generated content (AIGC) models can produce stunning and lifelike images, the lingering shadow of unauthorized reproductions and malicious tampering poses imminent threats to copyright integrity and information security. Current image watermarking methods, while widely accepted for safeguarding visual content, can only protect copyright and ensure traceability. They fall short in localizing increasingly realistic image tampering, potentially leading to trust crises, privacy violations, and legal disputes. To solve this challenge, we propose an innovative proactive forensics framework EditGuard, to unify copyright protection and tamper-agnostic localization, especially for AIGC-based editing methods. It can offer a meticulous embedding of imperceptible watermarks and precise decoding of tampered areas and copyright information. Leveraging our observed fragility and locality of image-into-image steganography, the realization of EditGuard can be converted into a united image-bit steganography issue, thus completely decoupling the training process from the tampering types. Extensive experiments demonstrate that our EditGuard balances the tamper localization accuracy, copyright recovery precision, and generalizability to various AIGC-based tampering methods, especially for image forgery that is difficult for the naked eye to detect. The project page is available at https://xuanyuzhang21.github.io/project/editguard/.
MAG-Edit: Localized Image Editing in Complex Scenarios via Mask-Based Attention-Adjusted Guidance
Dec 21, 2023Recent diffusion-based image editing approaches have exhibited impressive editing capabilities in images with simple compositions. However, localized editing in complex scenarios has not been well-studied in the literature, despite its growing real-world demands. Existing mask-based inpainting methods fall short of retaining the underlying structure within the edit region. Meanwhile, mask-free attention-based methods often exhibit editing leakage and misalignment in more complex compositions. In this work, we develop MAG-Edit, a training-free, inference-stage optimization method, which enables localized image editing in complex scenarios. In particular, MAG-Edit optimizes the noise latent feature in diffusion models by maximizing two mask-based cross-attention constraints of the edit token, which in turn gradually enhances the local alignment with the desired prompt. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method in achieving both text alignment and structure preservation for localized editing within complex scenarios.
Masked Contrastive Reconstruction for Cross-modal Medical Image-Report Retrieval
Dec 26, 2023Cross-modal medical image-report retrieval task plays a significant role in clinical diagnosis and various medical generative tasks. Eliminating heterogeneity between different modalities to enhance semantic consistency is the key challenge of this task. The current Vision-Language Pretraining (VLP) models, with cross-modal contrastive learning and masked reconstruction as joint training tasks, can effectively enhance the performance of cross-modal retrieval. This framework typically employs dual-stream inputs, using unmasked data for cross-modal contrastive learning and masked data for reconstruction. However, due to task competition and information interference caused by significant differences between the inputs of the two proxy tasks, the effectiveness of representation learning for intra-modal and cross-modal features is limited. In this paper, we propose an efficient VLP framework named Masked Contrastive and Reconstruction (MCR), which takes masked data as the sole input for both tasks. This enhances task connections, reducing information interference and competition between them, while also substantially decreasing the required GPU memory and training time. Moreover, we introduce a new modality alignment strategy named Mapping before Aggregation (MbA). Unlike previous methods, MbA maps different modalities to a common feature space before conducting local feature aggregation, thereby reducing the loss of fine-grained semantic information necessary for improved modality alignment. Additionally, due to using only masked input, our method significantly reduces the gpu memory and time required for training. Qualitative and quantitative experiments conducted on the MIMIC-CXR dataset validate the effectiveness of our approach, demonstrating state-of-the-art performance in medical cross-modal retrieval tasks.
iDesigner: A High-Resolution and Complex-Prompt Following Text-to-Image Diffusion Model for Interior Design
Dec 19, 2023With the open-sourcing of text-to-image models (T2I) such as stable diffusion (SD) and stable diffusion XL (SD-XL), there is an influx of models fine-tuned in specific domains based on the open-source SD model, such as in anime, character portraits, etc. However, there are few specialized models in certain domains, such as interior design, which is attributed to the complex textual descriptions and detailed visual elements inherent in design, alongside the necessity for adaptable resolution. Therefore, text-to-image models for interior design are required to have outstanding prompt-following capabilities, as well as iterative collaboration with design professionals to achieve the desired outcome. In this paper, we collect and optimize text-image data in the design field and continue training in both English and Chinese on the basis of the open-source CLIP model. We also proposed a fine-tuning strategy with curriculum learning and reinforcement learning from CLIP feedback to enhance the prompt-following capabilities of our approach so as to improve the quality of image generation. The experimental results on the collected dataset demonstrate the effectiveness of the proposed approach, which achieves impressive results and outperforms strong baselines.
Depicting Beyond Scores: Advancing Image Quality Assessment through Multi-modal Language Models
Dec 14, 2023We introduce a Depicted image Quality Assessment method (DepictQA), overcoming the constraints of traditional score-based approaches. DepictQA leverages Multi-modal Large Language Models (MLLMs), allowing for detailed, language-based, human-like evaluation of image quality. Unlike conventional Image Quality Assessment (IQA) methods relying on scores, DepictQA interprets image content and distortions descriptively and comparatively, aligning closely with humans' reasoning process. To build the DepictQA model, we establish a hierarchical task framework, and collect a multi-modal IQA training dataset, named M-BAPPS. To navigate the challenges in limited training data and processing multiple images, we propose to use multi-source training data and specialized image tags. Our DepictQA demonstrates a better performance than score-based methods on the BAPPS benchmark. Moreover, compared with general MLLMs, our DepictQA can generate more accurate reasoning descriptive languages. Our research indicates that language-based IQA methods have the potential to be customized for individual preferences. Datasets and codes will be released publicly.
Achieve Fairness without Demographics for Dermatological Disease Diagnosis
Jan 16, 2024In medical image diagnosis, fairness has become increasingly crucial. Without bias mitigation, deploying unfair AI would harm the interests of the underprivileged population and potentially tear society apart. Recent research addresses prediction biases in deep learning models concerning demographic groups (e.g., gender, age, and race) by utilizing demographic (sensitive attribute) information during training. However, many sensitive attributes naturally exist in dermatological disease images. If the trained model only targets fairness for a specific attribute, it remains unfair for other attributes. Moreover, training a model that can accommodate multiple sensitive attributes is impractical due to privacy concerns. To overcome this, we propose a method enabling fair predictions for sensitive attributes during the testing phase without using such information during training. Inspired by prior work highlighting the impact of feature entanglement on fairness, we enhance the model features by capturing the features related to the sensitive and target attributes and regularizing the feature entanglement between corresponding classes. This ensures that the model can only classify based on the features related to the target attribute without relying on features associated with sensitive attributes, thereby improving fairness and accuracy. Additionally, we use disease masks from the Segment Anything Model (SAM) to enhance the quality of the learned feature. Experimental results demonstrate that the proposed method can improve fairness in classification compared to state-of-the-art methods in two dermatological disease datasets.
Cross-Modal Semi-Dense 6-DoF Tracking of an Event Camera in Challenging Conditions
Jan 16, 2024Vision-based localization is a cost-effective and thus attractive solution for many intelligent mobile platforms. However, its accuracy and especially robustness still suffer from low illumination conditions, illumination changes, and aggressive motion. Event-based cameras are bio-inspired visual sensors that perform well in HDR conditions and have high temporal resolution, and thus provide an interesting alternative in such challenging scenarios. While purely event-based solutions currently do not yet produce satisfying mapping results, the present work demonstrates the feasibility of purely event-based tracking if an alternative sensor is permitted for mapping. The method relies on geometric 3D-2D registration of semi-dense maps and events, and achieves highly reliable and accurate cross-modal tracking results. Practically relevant scenarios are given by depth camera-supported tracking or map-based localization with a semi-dense map prior created by a regular image-based visual SLAM or structure-from-motion system. Conventional edge-based 3D-2D alignment is extended by a novel polarity-aware registration that makes use of signed time-surface maps (STSM) obtained from event streams. We furthermore introduce a novel culling strategy for occluded points. Both modifications increase the speed of the tracker and its robustness against occlusions or large view-point variations. The approach is validated on many real datasets covering the above-mentioned challenging conditions, and compared against similar solutions realised with regular cameras.
DG-TTA: Out-of-domain medical image segmentation through Domain Generalization and Test-Time Adaptation
Dec 22, 2023Applying pre-trained medical segmentation models on out-of-domain images often yields predictions of insufficient quality. Several strategies have been proposed to maintain model performance, such as finetuning or unsupervised- and source-free domain adaptation. These strategies set restrictive requirements for data availability. In this study, we propose to combine domain generalization and test-time adaptation to create a highly effective approach for reusing pre-trained models in unseen target domains. Domain-generalized pre-training on source data is used to obtain the best initial performance in the target domain. We introduce the MIND descriptor previously used in image registration tasks as a further technique to achieve generalization and present superior performance for small-scale datasets compared to existing approaches. At test-time, high-quality segmentation for every single unseen scan is ensured by optimizing the model weights for consistency given different image augmentations. That way, our method enables separate use of source and target data and thus removes current data availability barriers. Moreover, the presented method is highly modular as it does not require specific model architectures or prior knowledge of involved domains and labels. We demonstrate this by integrating it into the nnUNet, which is currently the most popular and accurate framework for medical image segmentation. We employ multiple datasets covering abdominal, cardiac, and lumbar spine scans and compose several out-of-domain scenarios in this study. We demonstrate that our method, combined with pre-trained whole-body CT models, can effectively segment MR images with high accuracy in all of the aforementioned scenarios. Open-source code can be found here: https://github.com/multimodallearning/DG-TTA
Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior
Jan 17, 2024Score distillation sampling (SDS) and its variants have greatly boosted the development of text-to-3D generation, but are vulnerable to geometry collapse and poor textures yet. To solve this issue, we first deeply analyze the SDS and find that its distillation sampling process indeed corresponds to the trajectory sampling of a stochastic differential equation (SDE): SDS samples along an SDE trajectory to yield a less noisy sample which then serves as a guidance to optimize a 3D model. However, the randomness in SDE sampling often leads to a diverse and unpredictable sample which is not always less noisy, and thus is not a consistently correct guidance, explaining the vulnerability of SDS. Since for any SDE, there always exists an ordinary differential equation (ODE) whose trajectory sampling can deterministically and consistently converge to the desired target point as the SDE, we propose a novel and effective "Consistent3D" method that explores the ODE deterministic sampling prior for text-to-3D generation. Specifically, at each training iteration, given a rendered image by a 3D model, we first estimate its desired 3D score function by a pre-trained 2D diffusion model, and build an ODE for trajectory sampling. Next, we design a consistency distillation sampling loss which samples along the ODE trajectory to generate two adjacent samples and uses the less noisy sample to guide another more noisy one for distilling the deterministic prior into the 3D model. Experimental results show the efficacy of our Consistent3D in generating high-fidelity and diverse 3D objects and large-scale scenes, as shown in Fig. 1. The codes are available at https://github.com/sail-sg/Consistent3D.