 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Dreamer: Deviation-Aware Latent Gaussian Memory for Action-Controlled AR Video Generation
Jun 01, 2026Frame-wise action-controlled image-to-video generation is a promising paradigm for interactive world simulation, where each control signal should elicit an immediate visual response. However, maintaining visual fidelity and 3D consistency over long autoregressive rollouts remains challenging. Existing 3D-aware methods often suffer from catastrophic drift due to two impediments: information loss from \textit{Latent--RGB Cycling}, where generated latents are repeatedly decoded to RGB and re-encoded for future conditioning, and the training--inference gap induced by the \textit{error-free hypothesis}, where clean training memory fails to match prediction-corrupted inference memory. To address these challenges, we present \textbf{Robust Dreamer}, a memory-augmented framework built around how to design 3D memory and how to use it robustly. First, we introduce \textbf{Latent Gaussian Memory}, which anchors diffusion latents inherited from the generation process to Gaussian primitives and recalls them via latent-space Gaussian splatting. This provides dense, geometry-aware, view-aligned conditioning while avoiding accumulated degradation from repeated VAE conversion. Second, we propose \textbf{Deviation Learning with Dynamic Deviation Archive}, which synthesizes rollout-induced latent deviations through a one-step approximation, stores them by autoregressive stage and denoising timestamp, and injects them into historical memory during training. This exposes the generator to realistic corrupted memory states and teaches internal correction before inference. Experiments on ScanNet, DL3DV, and OmniWorldGame demonstrate state-of-the-art long-horizon performance.
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Apr 08, 2026Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
StoryBlender: Inter-Shot Consistent and Editable 3D Storyboard with Spatial-temporal Dynamics
Apr 01, 2026Storyboarding is a core skill in visual storytelling for film, animation, and games. However, automating this process requires a system to achieve two properties that current approaches rarely satisfy simultaneously: inter-shot consistency and explicit editability. While 2D diffusion-based generators produce vivid imagery, they often suffer from identity drift along with limited geometric control; conversely, traditional 3D animation workflows are consistent and editable but require expert-heavy, labor-intensive authoring. We present StoryBlender, a grounded 3D storyboard generation framework governed by a Story-centric Reflection Scheme. At its core, we propose the StoryBlender system, which is built on a three-stage pipeline: (1) Semantic-Spatial Grounding, to construct a continuity memory graph to decouple global assets from shot-specific variables for long-horizon consistency; (2) Canonical Asset Materialization, to instantiate entities in a unified coordinate space to maintain visual identity; and (3) Spatial-Temporal Dynamics, to achieve layout design and cinematic evolution through visual metrics. By orchestrating multiple agents in a hierarchical manner within a verification loop, StoryBlender iteratively self-corrects spatial hallucinations via engine-verified feedback. The resulting native 3D scenes support direct, precise editing of cameras and visual assets while preserving unwavering multi-shot continuity. Experiments demonstrate that StoryBlender significantly improves consistency and editability over both diffusion-based and 3D-grounded baselines. Code, data, and demonstration video will be available on https://engineeringai-lab.github.io/StoryBlender/
I3DM: Implicit 3D-aware Memory Retrieval and Injection for Consistent Video Scene Generation
Mar 24, 2026Despite remarkable progress in video generation, maintaining long-term scene consistency upon revisiting previously explored areas remains challenging. Existing solutions rely either on explicitly constructing 3D geometry, which suffers from error accumulation and scale ambiguity, or on naive camera Field-of-View (FoV) retrieval, which typically fails under complex occlusions. To overcome these limitations, we propose I3DM, a novel implicit 3D-aware memory mechanism for consistent video scene generation that bypasses explicit 3D reconstruction. At the core of our approach is a 3D-aware memory retrieval strategy, which leverages the intermediate features of a pre-trained Feed-Forward Novel View Synthesis (FF-NVS) model to score view relevance, enabling robust retrieval even in highly occluded scenarios. Furthermore, to fully utilize the retrieved historical frames, we introduce a 3D-aligned memory injection module. This module implicitly warps historical content to the target view and adaptively conditions the generation on reliable warping regions, leading to improved revisit consistency and accurate camera control. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches, achieving superior revisit consistency, generation fidelity, and camera control precision.
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
Mar 12, 2026We present InSpatio-WorldFM, an open-source real-time frame model for spatial intelligence. Unlike video-based world models that rely on sequential frame generation and incur substantial latency due to window-level processing, InSpatio-WorldFM adopts a frame-based paradigm that generates each frame independently, enabling low-latency real-time spatial inference. By enforcing multi-view spatial consistency through explicit 3D anchors and implicit spatial memory, the model preserves global scene geometry while maintaining fine-grained visual details across viewpoint changes. We further introduce a progressive three-stage training pipeline that transforms a pretrained image diffusion model into a controllable frame model and finally into a real-time generator through few-step distillation. Experimental results show that InSpatio-WorldFM achieves strong multi-view consistency while supporting interactive exploration on consumer-grade GPUs, providing an efficient alternative to traditional video-based world models for real-time world simulation.
3DXTalker: Unifying Identity, Lip Sync, Emotion, and Spatial Dynamics in Expressive 3D Talking Avatars
Feb 12, 2026Audio-driven 3D talking avatar generation is increasingly important in virtual communication, digital humans, and interactive media, where avatars must preserve identity, synchronize lip motion with speech, express emotion, and exhibit lifelike spatial dynamics, collectively defining a broader objective of expressivity. However, achieving this remains challenging due to insufficient training data with limited subject identities, narrow audio representations, and restricted explicit controllability. In this paper, we propose 3DXTalker, an expressive 3D talking avatar through data-curated identity modeling, audio-rich representations, and spatial dynamics controllability. 3DXTalker enables scalable identity modeling via 2D-to-3D data curation pipeline and disentangled representations, alleviating data scarcity and improving identity generalization. Then, we introduce frame-wise amplitude and emotional cues beyond standard speech embeddings, ensuring superior lip synchronization and nuanced expression modulation. These cues are unified by a flow-matching-based transformer for coherent facial dynamics. Moreover, 3DXTalker also enables natural head-pose motion generation while supporting stylized control via prompt-based conditioning. Extensive experiments show that 3DXTalker integrates lip synchronization, emotional expression, and head-pose dynamics within a unified framework, achieves superior performance in 3D talking avatar generation.
BachVid: Training-Free Video Generation with Consistent Background and Character
Oct 24, 2025Diffusion Transformers (DiTs) have recently driven significant progress in text-to-video (T2V) generation. However, generating multiple videos with consistent characters and backgrounds remains a significant challenge. Existing methods typically rely on reference images or extensive training, and often only address character consistency, leaving background consistency to image-to-video models. We introduce BachVid, the first training-free method that achieves consistent video generation without needing any reference images. Our approach is based on a systematic analysis of DiT's attention mechanism and intermediate features, revealing its ability to extract foreground masks and identify matching points during the denoising process. Our method leverages this finding by first generating an identity video and caching the intermediate variables, and then inject these cached variables into corresponding positions in newly generated videos, ensuring both foreground and background consistency across multiple videos. Experimental results demonstrate that BachVid achieves robust consistency in generated videos without requiring additional training, offering a novel and efficient solution for consistent video generation without relying on reference images or additional training.
OpenGV 2.0: Motion prior-assisted calibration and SLAM with vehicle-mounted surround-view systems
Mar 05, 2025

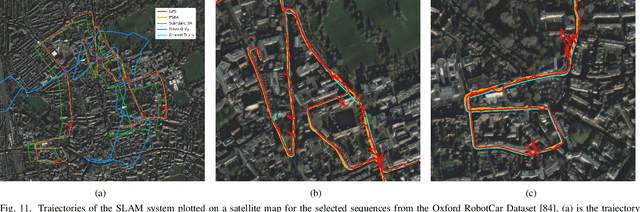
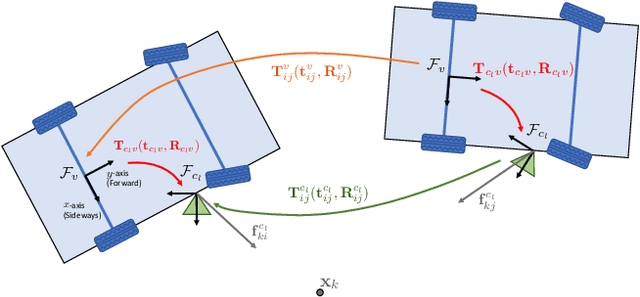
The present paper proposes optimization-based solutions to visual SLAM with a vehicle-mounted surround-view camera system. Owing to their original use-case, such systems often only contain a single camera facing into either direction and very limited overlap between fields of view. Our novelty consist of three optimization modules targeting at practical online calibration of exterior orientations from simple two-view geometry, reliable front-end initialization of relative displacements, and accurate back-end optimization using a continuous-time trajectory model. The commonality between the proposed modules is given by the fact that all three of them exploit motion priors that are related to the inherent non-holonomic characteristics of passenger vehicle motion. In contrast to prior related art, the proposed modules furthermore excel in terms of bypassing partial unobservabilities in the transformation variables that commonly occur for Ackermann-motion. As a further contribution, the modules are built into a novel surround-view camera SLAM system that specifically targets deployment on Ackermann vehicles operating in urban environments. All modules are studied in the context of in-depth ablation studies, and the practical validity of the entire framework is supported by a successful application to challenging, large-scale publicly available online datasets. Note that upon acceptance, the entire framework is scheduled for open-source release as part of an extension of the OpenGV library.
T$^3$-S2S: Training-free Triplet Tuning for Sketch to Scene Generation
Dec 18, 2024Scene generation is crucial to many computer graphics applications. Recent advances in generative AI have streamlined sketch-to-image workflows, easing the workload for artists and designers in creating scene concept art. However, these methods often struggle for complex scenes with multiple detailed objects, sometimes missing small or uncommon instances. In this paper, we propose a Training-free Triplet Tuning for Sketch-to-Scene (T3-S2S) generation after reviewing the entire cross-attention mechanism. This scheme revitalizes the existing ControlNet model, enabling effective handling of multi-instance generations, involving prompt balance, characteristics prominence, and dense tuning. Specifically, this approach enhances keyword representation via the prompt balance module, reducing the risk of missing critical instances. It also includes a characteristics prominence module that highlights TopK indices in each channel, ensuring essential features are better represented based on token sketches. Additionally, it employs dense tuning to refine contour details in the attention map, compensating for instance-related regions. Experiments validate that our triplet tuning approach substantially improves the performance of existing sketch-to-image models. It consistently generates detailed, multi-instance 2D images, closely adhering to the input prompts and enhancing visual quality in complex multi-instance scenes. Code is available at https://github.com/chaos-sun/t3s2s.git.
Sketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User's Casual Sketches
Aug 08, 2024



3D Content Generation is at the heart of many computer graphics applications, including video gaming, film-making, virtual and augmented reality, etc. This paper proposes a novel deep-learning based approach for automatically generating interactive and playable 3D game scenes, all from the user's casual prompts such as a hand-drawn sketch. Sketch-based input offers a natural, and convenient way to convey the user's design intention in the content creation process. To circumvent the data-deficient challenge in learning (i.e. the lack of large training data of 3D scenes), our method leverages a pre-trained 2D denoising diffusion model to generate a 2D image of the scene as the conceptual guidance. In this process, we adopt the isometric projection mode to factor out unknown camera poses while obtaining the scene layout. From the generated isometric image, we use a pre-trained image understanding method to segment the image into meaningful parts, such as off-ground objects, trees, and buildings, and extract the 2D scene layout. These segments and layouts are subsequently fed into a procedural content generation (PCG) engine, such as a 3D video game engine like Unity or Unreal, to create the 3D scene. The resulting 3D scene can be seamlessly integrated into a game development environment and is readily playable. Extensive tests demonstrate that our method can efficiently generate high-quality and interactive 3D game scenes with layouts that closely follow the user's intention.