 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Two-Phase Object-Based Deep Learning for Multi-temporal SAR Image Change Detection
Jan 17, 2020
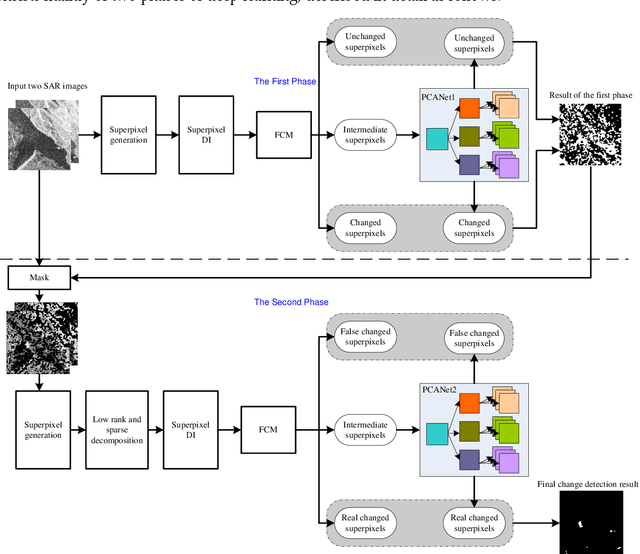
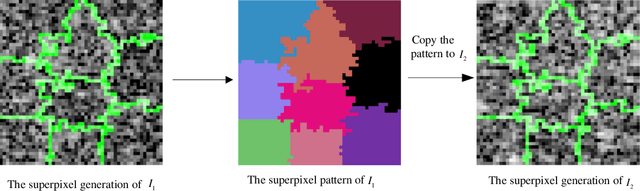
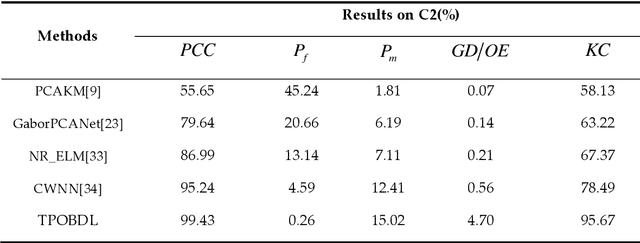
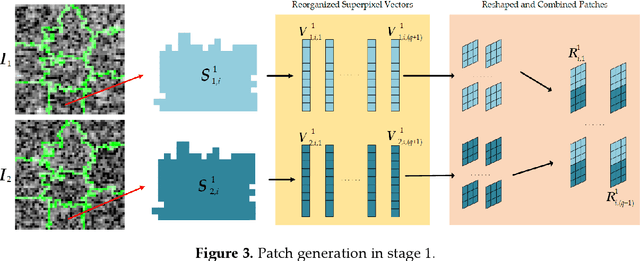
Change detection is one of the fundamental applications of synthetic aperture radar (SAR) images. However, speckle noise presented in SAR images has a much negative effect on change detection. In this research, a novel two-phase object-based deep learning approach is proposed for multi-temporal SAR image change detection. Compared with traditional methods, the proposed approach brings two main innovations. One is to classify all pixels into three categories rather than two categories: unchanged pixels, changed pixels caused by strong speckle (false changes), and changed pixels formed by real terrain variation (real changes). The other is to group neighboring pixels into segmented into superpixel objects (from pixels) such as to exploit local spatial context. Two phases are designed in the methodology: 1) Generate objects based on the simple linear iterative clustering algorithm, and discriminate these objects into changed and unchanged classes using fuzzy c-means (FCM) clustering and a deep PCANet. The prediction of this Phase is the set of changed and unchanged superpixels. 2) Deep learning on the pixel sets over the changed superpixels only, obtained in the first phase, to discriminate real changes from false changes. SLIC is employed again to achieve new superpixels in the second phase. Low rank and sparse decomposition are applied to these new superpixels to suppress speckle noise significantly. A further clustering step is applied to these new superpixels via FCM. A new PCANet is then trained to classify two kinds of changed superpixels to achieve the final change maps. Numerical experiments demonstrate that, compared with benchmark methods, the proposed approach can distinguish real changes from false changes effectively with significantly reduced false alarm rates, and achieve up to 99.71% change detection accuracy using multi-temporal SAR imagery.
MR to X-Ray Projection Image Synthesis
Apr 03, 2018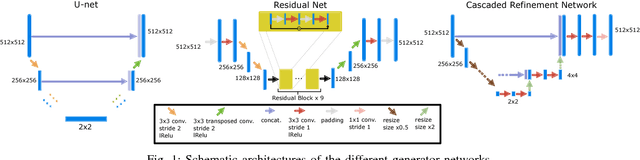
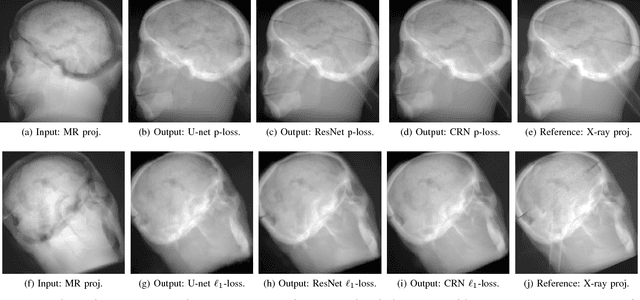
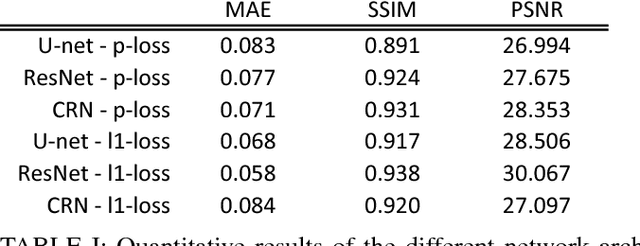
Hybrid imaging promises large potential in medical imaging applications. To fully utilize the possibilities of corresponding information from different modalities, the information must be transferable between the domains. In radiation therapy planning, existing methods make use of reconstructed 3D magnetic resonance imaging data to synthesize corresponding X-ray attenuation maps. In contrast, for fluoroscopic procedures only line integral data, i.e., 2D projection images, are present. The question arises which approaches could potentially be used for this MR to X-ray projection image-to-image translation. We examine three network architectures and two loss-functions regarding their suitability as generator networks for this task. All generators proved to yield suitable results for this task. A cascaded refinement network paired with a perceptual-loss function achieved the best qualitative results in our evaluation. The perceptual-loss showed to be able to preserve most of the high-frequency details in the projection images and, thus, is recommended for the underlying task and similar problems.
Learning to Track Instances without Video Annotations
Apr 01, 2021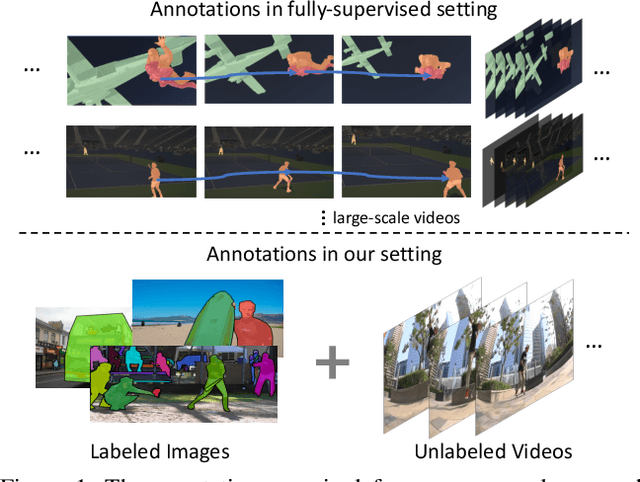

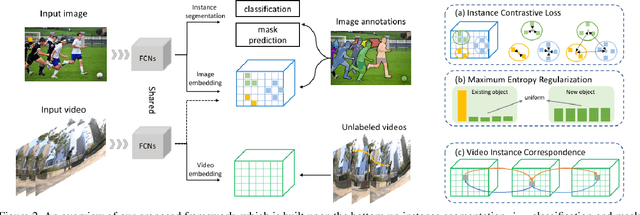

Tracking segmentation masks of multiple instances has been intensively studied, but still faces two fundamental challenges: 1) the requirement of large-scale, frame-wise annotation, and 2) the complexity of two-stage approaches. To resolve these challenges, we introduce a novel semi-supervised framework by learning instance tracking networks with only a labeled image dataset and unlabeled video sequences. With an instance contrastive objective, we learn an embedding to discriminate each instance from the others. We show that even when only trained with images, the learned feature representation is robust to instance appearance variations, and is thus able to track objects steadily across frames. We further enhance the tracking capability of the embedding by learning correspondence from unlabeled videos in a self-supervised manner. In addition, we integrate this module into single-stage instance segmentation and pose estimation frameworks, which significantly reduce the computational complexity of tracking compared to two-stage networks. We conduct experiments on the YouTube-VIS and PoseTrack datasets. Without any video annotation efforts, our proposed method can achieve comparable or even better performance than most fully-supervised methods.
BYOL works even without batch statistics
Oct 20, 2020

Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ($73.9\%$ vs. $74.3\%$ top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-$50$). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
Poisoning MorphNet for Clean-Label Backdoor Attack to Point Clouds
May 11, 2021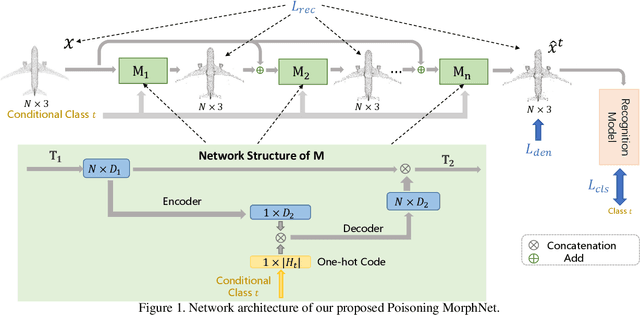

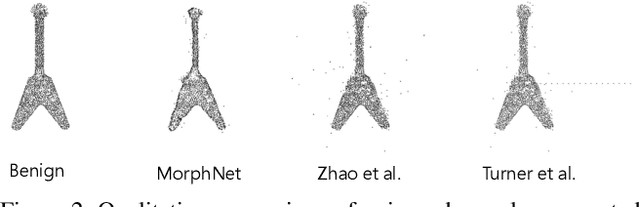

This paper presents Poisoning MorphNet, the first backdoor attack method on point clouds. Conventional adversarial attack takes place in the inference stage, often fooling a model by perturbing samples. In contrast, backdoor attack aims to implant triggers into a model during the training stage, such that the victim model acts normally on the clean data unless a trigger is present in a sample. This work follows a typical setting of clean-label backdoor attack, where a few poisoned samples (with their content tampered yet labels unchanged) are injected into the training set. The unique contributions of MorphNet are two-fold. First, it is key to ensure the implanted triggers both visually imperceptible to humans and lead to high attack success rate on the point clouds. To this end, MorphNet jointly optimizes two objectives for sample-adaptive poisoning: a reconstruction loss that preserves the visual similarity between benign / poisoned point clouds, and a classification loss that enforces a modern recognition model of point clouds tends to mis-classify the poisoned sample to a pre-specified target category. This implicitly conducts spectral separation over point clouds, hiding sample-adaptive triggers in fine-grained high-frequency details. Secondly, existing backdoor attack methods are mainly designed for image data, easily defended by some point cloud specific operations (such as denoising). We propose a third loss in MorphNet for suppressing isolated points, leading to improved resistance to denoising-based defense. Comprehensive evaluations are conducted on ModelNet40 and ShapeNetcorev2. Our proposed Poisoning MorphNet outstrips all previous methods with clear margins.
DeepViT: Towards Deeper Vision Transformer
Apr 19, 2021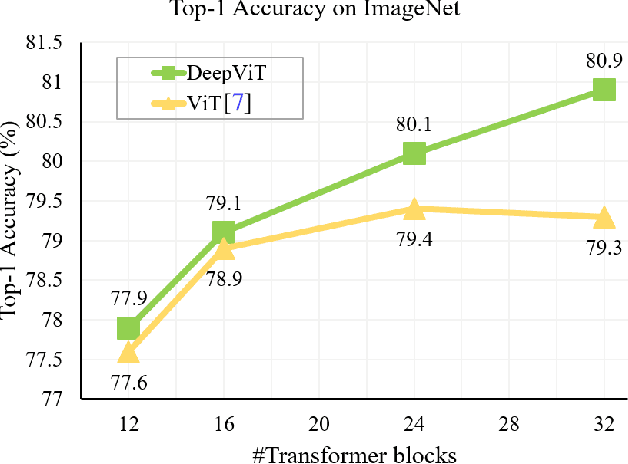
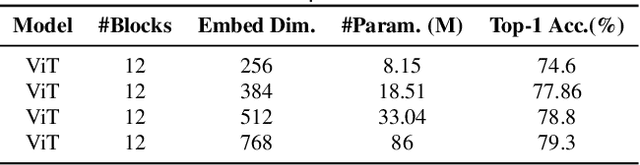
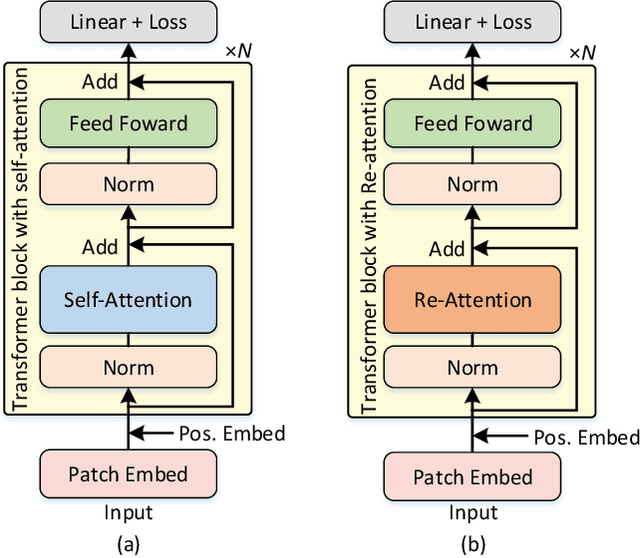

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code is publicly available at https://github.com/zhoudaquan/dvit_repo.
Continual Adaptation of Visual Representations via Domain Randomization and Meta-learning
Dec 08, 2020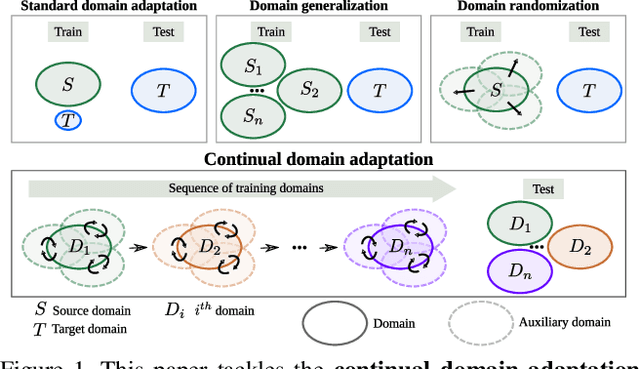
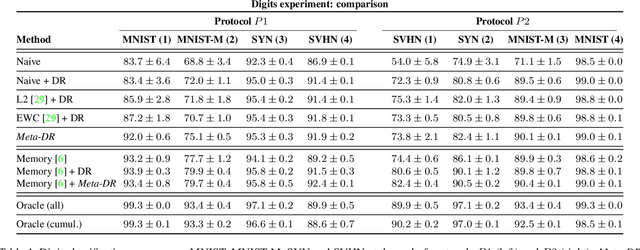
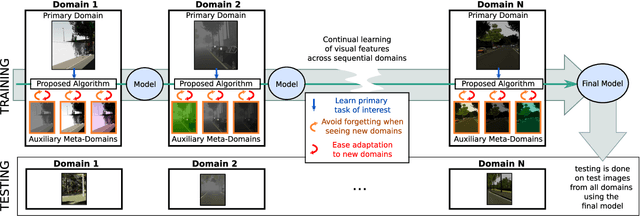
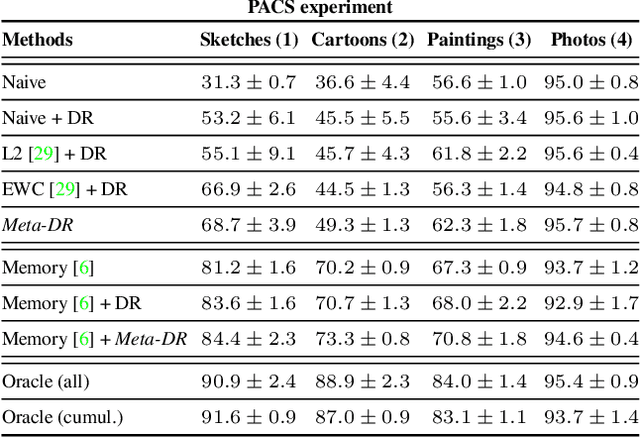
Most standard learning approaches lead to fragile models which are prone to drift when sequentially trained on samples of a different nature - the well-known "catastrophic forgetting" issue. In particular, when a model consecutively learns from different visual domains, it tends to forget the past ones in favor of the most recent. In this context, we show that one way to learn models that are inherently more robust against forgetting is domain randomization - for vision tasks, randomizing the current domain's distribution with heavy image manipulations. Building on this result, we devise a meta-learning strategy where a regularizer explicitly penalizes any loss associated with transferring the model from the current domain to different "auxiliary" meta-domains, while also easing adaptation to them. Such meta-domains, are also generated through randomized image manipulations. We empirically demonstrate in a variety of experiments - spanning from classification to semantic segmentation - that our approach results in models that are less prone to catastrophic forgetting when transferred to new domains.
Learning Multi-Scene Absolute Pose Regression with Transformers
Mar 21, 2021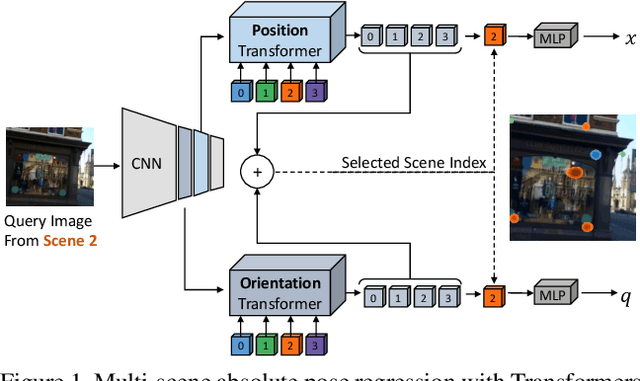
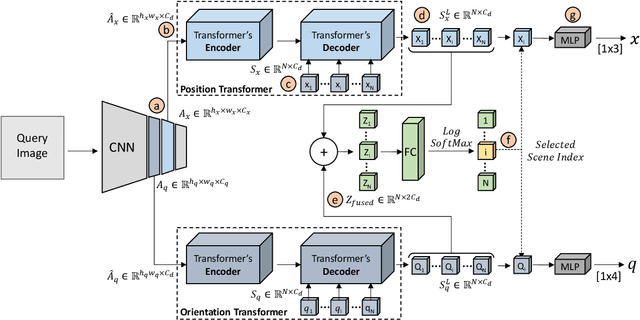
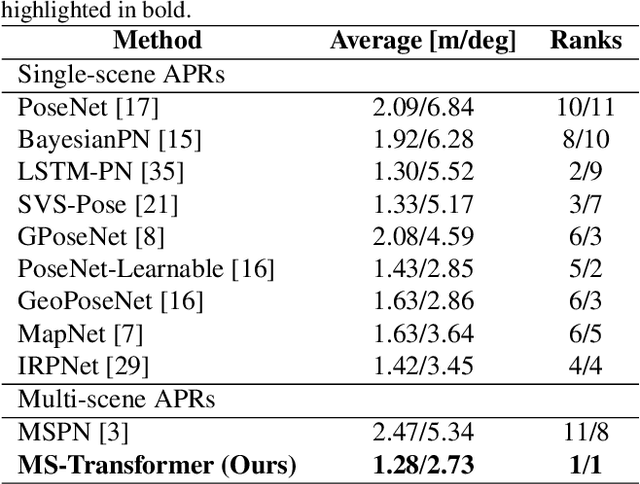

Absolute camera pose regressors estimate the position and orientation of a camera from the captured image alone. Typically, a convolutional backbone with a multi-layer perceptron head is trained with images and pose labels to embed a single reference scene at a time. Recently, this scheme was extended for learning multiple scenes by replacing the MLP head with a set of fully connected layers. In this work, we propose to learn multi-scene absolute camera pose regression with Transformers, where encoders are used to aggregate activation maps with self-attention and decoders transform latent features and scenes encoding into candidate pose predictions. This mechanism allows our model to focus on general features that are informative for localization while embedding multiple scenes in parallel. We evaluate our method on commonly benchmarked indoor and outdoor datasets and show that it surpasses both multi-scene and state-of-the-art single-scene absolute pose regressors. We make our code publicly available from here.
Cross-linguistic differences and similarities in image descriptions
Aug 13, 2017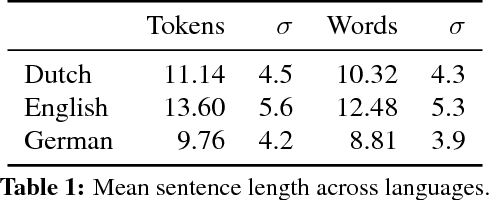
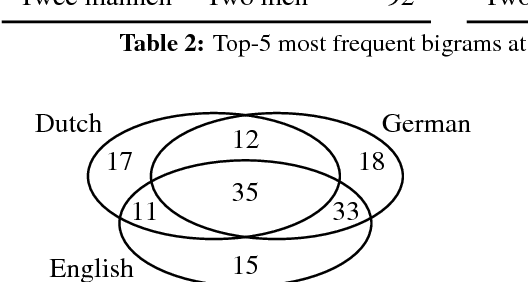


Automatic image description systems are commonly trained and evaluated on large image description datasets. Recently, researchers have started to collect such datasets for languages other than English. An unexplored question is how different these datasets are from English and, if there are any differences, what causes them to differ. This paper provides a cross-linguistic comparison of Dutch, English, and German image descriptions. We find that these descriptions are similar in many respects, but the familiarity of crowd workers with the subjects of the images has a noticeable influence on description specificity.
Weak Multi-View Supervision for Surface Mapping Estimation
May 04, 2021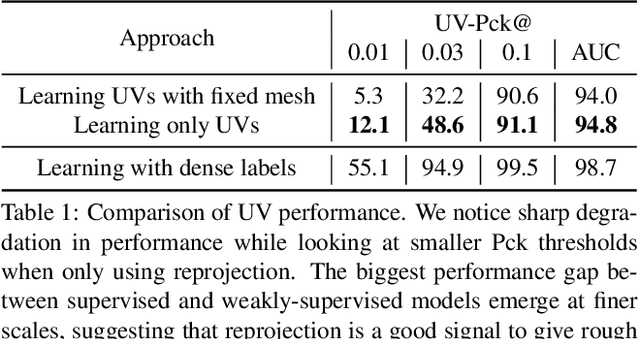
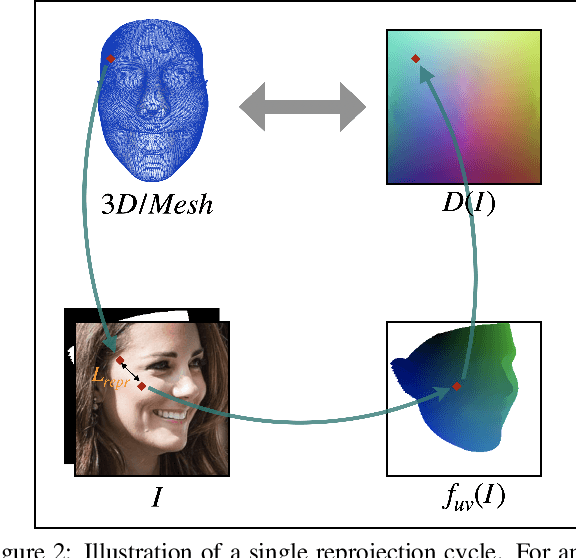
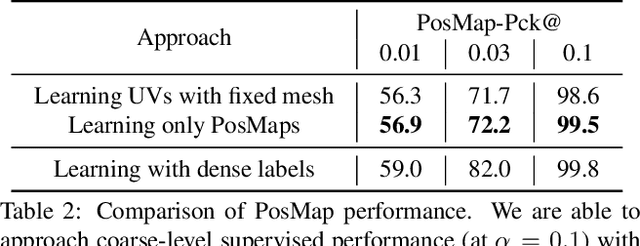

We propose a weakly-supervised multi-view learning approach to learn category-specific surface mapping without dense annotations. We learn the underlying surface geometry of common categories, such as human faces, cars, and airplanes, given instances from those categories. While traditional approaches solve this problem using extensive supervision in the form of pixel-level annotations, we take advantage of the fact that pixel-level UV and mesh predictions can be combined with 3D reprojections to form consistency cycles. As a result of exploiting these cycles, we can establish a dense correspondence mapping between image pixels and the mesh acting as a self-supervisory signal, which in turn helps improve our overall estimates. Our approach leverages information from multiple views of the object to establish additional consistency cycles, thus improving surface mapping understanding without the need for explicit annotations. We also propose the use of deformation fields for predictions of an instance specific mesh. Given the lack of datasets providing multiple images of similar object instances from different viewpoints, we generate and release a multi-view ShapeNet Cars and Airplanes dataset created by rendering ShapeNet meshes using a 360 degree camera trajectory around the mesh. For the human faces category, we process and adapt an existing dataset to a multi-view setup. Through experimental evaluations, we show that, at test time, our method can generate accurate variations away from the mean shape, is multi-view consistent, and performs comparably to fully supervised approaches.