 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CAPSARII Approach to Cyber-Secure Wearable, Ultra-Low-Power Networked Sensors for Soldier Health Monitoring
Feb 08, 2026The European Defence Agency's revised Capability Development Plan (CDP) identifies as a priority improving ground combat capabilities by enhancing soldiers' equipment for better protection. The CAPSARII project proposes in innovative wearable system and Internet of Battlefield Things (IoBT) framework to monitor soldiers' physiological and psychological status, aiding tactical decisions and medical support. The CAPSARII system will enhance situational awareness and operational effectiveness by monitoring physiological, movement and environmental parameters, providing real-time tactical decision support through AI models deployed on edge nodes and enable data analysis and comparative studies via cloud-based analytics. CAPSARII also aims at improving usability through smart textile integration, longer battery life, reducing energy consumption through software and hardware optimizations, and address security concerns with efficient encryption and strong authentication methods. This innovative approach aims to transform military operations by providing a robust, data-driven decision support tool.
What could go wrong? Discovering and describing failure modes in computer vision
Aug 08, 2024



Deep learning models are effective, yet brittle. Even carefully trained, their behavior tends to be hard to predict when confronted with out-of-distribution samples. In this work, our goal is to propose a simple yet effective solution to predict and describe via natural language potential failure modes of computer vision models. Given a pretrained model and a set of samples, our aim is to find sentences that accurately describe the visual conditions in which the model underperforms. In order to study this important topic and foster future research on it, we formalize the problem of Language-Based Error Explainability (LBEE) and propose a set of metrics to evaluate and compare different methods for this task. We propose solutions that operate in a joint vision-and-language embedding space, and can characterize through language descriptions model failures caused, e.g., by objects unseen during training or adverse visual conditions. We experiment with different tasks, such as classification under the presence of dataset bias and semantic segmentation in unseen environments, and show that the proposed methodology isolates nontrivial sentences associated with specific error causes. We hope our work will help practitioners better understand the behavior of models, increasing their overall safety and interpretability.
SHiNe: Semantic Hierarchy Nexus for Open-vocabulary Object Detection
May 16, 2024Open-vocabulary object detection (OvOD) has transformed detection into a language-guided task, empowering users to freely define their class vocabularies of interest during inference. However, our initial investigation indicates that existing OvOD detectors exhibit significant variability when dealing with vocabularies across various semantic granularities, posing a concern for real-world deployment. To this end, we introduce Semantic Hierarchy Nexus (SHiNe), a novel classifier that uses semantic knowledge from class hierarchies. It runs offline in three steps: i) it retrieves relevant super-/sub-categories from a hierarchy for each target class; ii) it integrates these categories into hierarchy-aware sentences; iii) it fuses these sentence embeddings to generate the nexus classifier vector. Our evaluation on various detection benchmarks demonstrates that SHiNe enhances robustness across diverse vocabulary granularities, achieving up to +31.9% mAP50 with ground truth hierarchies, while retaining improvements using hierarchies generated by large language models. Moreover, when applied to open-vocabulary classification on ImageNet-1k, SHiNe improves the CLIP zero-shot baseline by +2.8% accuracy. SHiNe is training-free and can be seamlessly integrated with any off-the-shelf OvOD detector, without incurring additional computational overhead during inference. The code is open source.
PANDAS: Prototype-based Novel Class Discovery and Detection
Feb 27, 2024



Object detectors are typically trained once and for all on a fixed set of classes. However, this closed-world assumption is unrealistic in practice, as new classes will inevitably emerge after the detector is deployed in the wild. In this work, we look at ways to extend a detector trained for a set of base classes so it can i) spot the presence of novel classes, and ii) automatically enrich its repertoire to be able to detect those newly discovered classes together with the base ones. We propose PANDAS, a method for novel class discovery and detection. It discovers clusters representing novel classes from unlabeled data, and represents old and new classes with prototypes. During inference, a distance-based classifier uses these prototypes to assign a label to each detected object instance. The simplicity of our method makes it widely applicable. We experimentally demonstrate the effectiveness of PANDAS on the VOC 2012 and COCO-to-LVIS benchmarks. It performs favorably against the state of the art for this task while being computationally more affordable.
Placing Objects in Context via Inpainting for Out-of-distribution Segmentation
Feb 26, 2024When deploying a semantic segmentation model into the real world, it will inevitably be confronted with semantic classes unseen during training. Thus, to safely deploy such systems, it is crucial to accurately evaluate and improve their anomaly segmentation capabilities. However, acquiring and labelling semantic segmentation data is expensive and unanticipated conditions are long-tail and potentially hazardous. Indeed, existing anomaly segmentation datasets capture a limited number of anomalies, lack realism or have strong domain shifts. In this paper, we propose the Placing Objects in Context (POC) pipeline to realistically add any object into any image via diffusion models. POC can be used to easily extend any dataset with an arbitrary number of objects. In our experiments, we present different anomaly segmentation datasets based on POC-generated data and show that POC can improve the performance of recent state-of-the-art anomaly fine-tuning methods in several standardized benchmarks. POC is also effective to learn new classes. For example, we use it to edit Cityscapes samples by adding a subset of Pascal classes and show that models trained on such data achieve comparable performance to the Pascal-trained baseline. This corroborates the low sim-to-real gap of models trained on POC-generated images.
RaSP: Relation-aware Semantic Prior for Weakly Supervised Incremental Segmentation
May 31, 2023Class-incremental semantic image segmentation assumes multiple model updates, each enriching the model to segment new categories. This is typically carried out by providing expensive pixel-level annotations to the training algorithm for all new objects, limiting the adoption of such methods in practical applications. Approaches that solely require image-level labels offer an attractive alternative, yet, such coarse annotations lack precise information about the location and boundary of the new objects. In this paper we argue that, since classes represent not just indices but semantic entities, the conceptual relationships between them can provide valuable information that should be leveraged. We propose a weakly supervised approach that exploits such semantic relations to transfer objectness prior from the previously learned classes into the new ones, complementing the supervisory signal from image-level labels. We validate our approach on a number of continual learning tasks, and show how even a simple pairwise interaction between classes can significantly improve the segmentation mask quality of both old and new classes. We show these conclusions still hold for longer and, hence, more realistic sequences of tasks and for a challenging few-shot scenario.
Reliability in Semantic Segmentation: Are We on the Right Track?
Mar 20, 2023



Motivated by the increasing popularity of transformers in computer vision, in recent times there has been a rapid development of novel architectures. While in-domain performance follows a constant, upward trend, properties like robustness or uncertainty estimation are less explored -leaving doubts about advances in model reliability. Studies along these axes exist, but they are mainly limited to classification models. In contrast, we carry out a study on semantic segmentation, a relevant task for many real-world applications where model reliability is paramount. We analyze a broad variety of models, spanning from older ResNet-based architectures to novel transformers and assess their reliability based on four metrics: robustness, calibration, misclassification detection and out-of-distribution (OOD) detection. We find that while recent models are significantly more robust, they are not overall more reliable in terms of uncertainty estimation. We further explore methods that can come to the rescue and show that improving calibration can also help with other uncertainty metrics such as misclassification or OOD detection. This is the first study on modern segmentation models focused on both robustness and uncertainty estimation and we hope it will help practitioners and researchers interested in this fundamental vision task. Code available at https://github.com/naver/relis.
Semantic Image Segmentation: Two Decades of Research
Feb 13, 2023Semantic image segmentation (SiS) plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. This survey is an effort to summarize two decades of research in the field of SiS, where we propose a literature review of solutions starting from early historical methods followed by an overview of more recent deep learning methods including the latest trend of using transformers. We complement the review by discussing particular cases of the weak supervision and side machine learning techniques that can be used to improve the semantic segmentation such as curriculum, incremental or self-supervised learning. State-of-the-art SiS models rely on a large amount of annotated samples, which are more expensive to obtain than labels for tasks such as image classification. Since unlabeled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation (UDA) reached a broad success within the semantic segmentation community. Therefore, a second core contribution of this book is to summarize five years of a rapidly growing field, Domain Adaptation for Semantic Image Segmentation (DASiS) which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. In addition to providing a comprehensive survey on DASiS techniques, we unveil also newer trends such as multi-domain learning, domain generalization, domain incremental learning, test-time adaptation and source-free domain adaptation. Finally, we conclude this survey by describing datasets and benchmarks most widely used in SiS and DASiS and briefly discuss related tasks such as instance and panoptic image segmentation, as well as applications such as medical image segmentation.
On the Road to Online Adaptation for Semantic Image Segmentation
Mar 30, 2022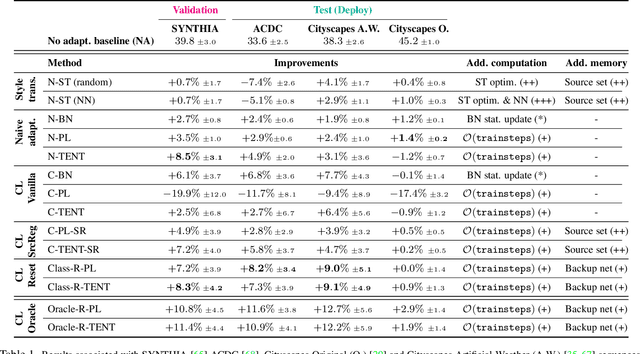

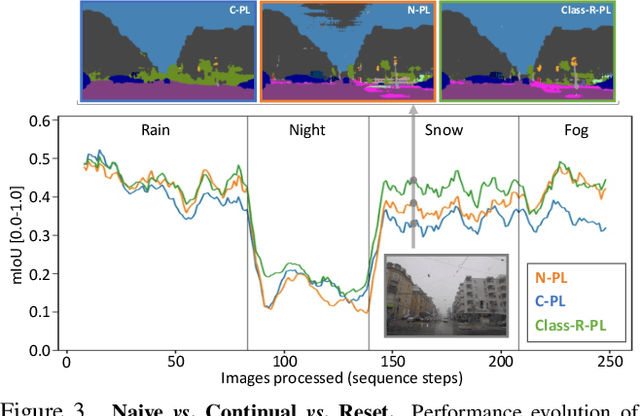
We propose a new problem formulation and a corresponding evaluation framework to advance research on unsupervised domain adaptation for semantic image segmentation. The overall goal is fostering the development of adaptive learning systems that will continuously learn, without supervision, in ever-changing environments. Typical protocols that study adaptation algorithms for segmentation models are limited to few domains, adaptation happens offline, and human intervention is generally required, at least to annotate data for hyper-parameter tuning. We argue that such constraints are incompatible with algorithms that can continuously adapt to different real-world situations. To address this, we propose a protocol where models need to learn online, from sequences of temporally correlated images, requiring continuous, frame-by-frame adaptation. We accompany this new protocol with a variety of baselines to tackle the proposed formulation, as well as an extensive analysis of their behaviors, which can serve as a starting point for future research.
Make Some Noise: Reliable and Efficient Single-Step Adversarial Training
Feb 02, 2022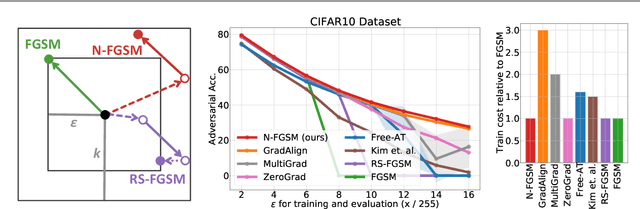
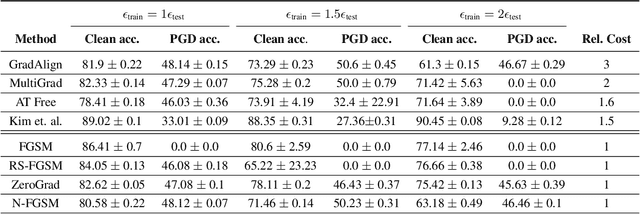
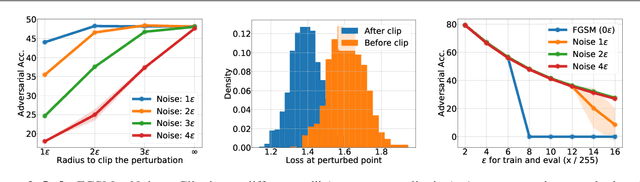
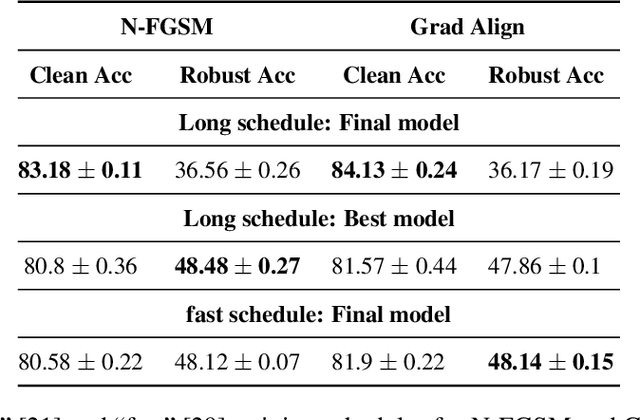
Recently, Wong et al. showed that adversarial training with single-step FGSM leads to a characteristic failure mode named catastrophic overfitting (CO), in which a model becomes suddenly vulnerable to multi-step attacks. They showed that adding a random perturbation prior to FGSM (RS-FGSM) seemed to be sufficient to prevent CO. However, Andriushchenko and Flammarion observed that RS-FGSM still leads to CO for larger perturbations, and proposed an expensive regularizer (GradAlign) to avoid CO. In this work, we methodically revisit the role of noise and clipping in single-step adversarial training. Contrary to previous intuitions, we find that using a stronger noise around the clean sample combined with not clipping is highly effective in avoiding CO for large perturbation radii. Based on these observations, we then propose Noise-FGSM (N-FGSM) that, while providing the benefits of single-step adversarial training, does not suffer from CO. Empirical analyses on a large suite of experiments show that N-FGSM is able to match or surpass the performance of previous single-step methods while achieving a 3$\times$ speed-up.