 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Pre-training Dividend: Generative versus Latent Self-Supervised Learning for Time Series Foundation Models
May 19, 2026The success of self-supervised learning (SSL) in vision and NLP has motivated its rapid adoption for time series. However, research has focused primarily on Generative paradigms and forecasting tasks, leaving the broader utility of learned representations unquantified. We establish a controlled framework to evaluate the "pre-training dividend": the value added by SSL across diverse temporal tasks. We systematically compare Generative paradigms against Latent Alignment architectures, introducing adaptations of LeJEPA and DINO for time series. These adaptations utilize Discrete Wavelet Transform (DWT) augmentations to enforce invariance to local fluctuations. Our analysis reveals that the pre-training dividend is highly asymmetric: SSL yields gains of up to 375% for anomaly detection and classification, yet remains marginal for forecasting. We demonstrate that representational utility is non-universal, governed by a precision-invariance trade-off where the specific signal resolution required by the task must align with the objective. Finally, we show that representation quality is largely independent of data origin and saturates at moderate architectural depths, suggesting a path to scaling via massive synthetic generation. Our code is available at: https://github.com/noammajor/Models
KappaPlace: Learning Hyperspherical Uncertainty for Visual Place Recognition via Prototype-Anchored Supervision
May 19, 2026Visual Place Recognition (VPR) is critical for autonomous navigation, yet state-of-the-art methods lack well-calibrated uncertainty estimation. Standard pipelines cannot reliably signal when a query is ambiguous or a match is likely incorrect, posing risks in safety-critical robotics. We propose KappaPlace, a principled framework for learning uncertainty-aware VPR representations. Our core contribution is a Prototype-Anchored supervision strategy that leverages latent class representatives as targets for a probabilistic objective. By modeling image descriptors as von Mises-Fisher (vMF) variables, we learn a lightweight module to predict the concentration parameter as a direct proxy for aleatoric uncertainty. While existing VPR uncertainty methods are typically restricted to a query-centric view, we derive a novel match-level formulation to quantify the reliability of specific query-reference pairs. Across five diverse benchmarks, KappaPlace reduces Expected Calibration Error (ECE@K) by up to 50% compared to existing methods while maintaining or improving retrieval recall. We provide both a joint-training variant and a post-training extension for frozen backbones. Our results demonstrate that KappaPlace provides a robust, stable, and well-calibrated signal that enables reliable decision-making within the VPR pipeline. Our code is available at: https://github.com/mayayank95/UncertaintyAwareVPR
JEPA-DNA: Grounding Genomic Foundation Models through Joint-Embedding Predictive Architectures
Feb 19, 2026Genomic Foundation Models (GFMs) have largely relied on Masked Language Modeling (MLM) or Next Token Prediction (NTP) to learn the language of life. While these paradigms excel at capturing local genomic syntax and fine-grained motif patterns, they often fail to capture the broader functional context, resulting in representations that lack a global biological perspective. We introduce JEPA-DNA, a novel pre-training framework that integrates the Joint-Embedding Predictive Architecture (JEPA) with traditional generative objectives. JEPA-DNA introduces latent grounding by coupling token-level recovery with a predictive objective in the latent space by supervising a CLS token. This forces the model to predict the high-level functional embeddings of masked genomic segments rather than focusing solely on individual nucleotides. JEPA-DNA extends both NTP and MLM paradigms and can be deployed either as a standalone from-scratch objective or as a continual pre-training enhancement for existing GFMs. Our evaluations across a diverse suite of genomic benchmarks demonstrate that JEPA-DNA consistently yields superior performance in supervised and zero-shot tasks compared to generative-only baselines. By providing a more robust and biologically grounded representation, JEPA-DNA offers a scalable path toward foundation models that understand not only the genomic alphabet, but also the underlying functional logic of the sequence.
LaVPR: Benchmarking Language and Vision for Place Recognition
Feb 03, 2026Visual Place Recognition (VPR) often fails under extreme environmental changes and perceptual aliasing. Furthermore, standard systems cannot perform "blind" localization from verbal descriptions alone, a capability needed for applications such as emergency response. To address these challenges, we introduce LaVPR, a large-scale benchmark that extends existing VPR datasets with over 650,000 rich natural-language descriptions. Using LaVPR, we investigate two paradigms: Multi-Modal Fusion for enhanced robustness and Cross-Modal Retrieval for language-based localization. Our results show that language descriptions yield consistent gains in visually degraded conditions, with the most significant impact on smaller backbones. Notably, adding language allows compact models to rival the performance of much larger vision-only architectures. For cross-modal retrieval, we establish a baseline using Low-Rank Adaptation (LoRA) and Multi-Similarity loss, which substantially outperforms standard contrastive methods across vision-language models. Ultimately, LaVPR enables a new class of localization systems that are both resilient to real-world stochasticity and practical for resource-constrained deployment. Our dataset and code are available at https://github.com/oferidan1/LaVPR.
Coarse-to-Fine Multi-Scene Pose Regression with Transformers
Aug 22, 2023



Absolute camera pose regressors estimate the position and orientation of a camera given the captured image alone. Typically, a convolutional backbone with a multi-layer perceptron (MLP) head is trained using images and pose labels to embed a single reference scene at a time. Recently, this scheme was extended to learn multiple scenes by replacing the MLP head with a set of fully connected layers. In this work, we propose to learn multi-scene absolute camera pose regression with Transformers, where encoders are used to aggregate activation maps with self-attention and decoders transform latent features and scenes encoding into pose predictions. This allows our model to focus on general features that are informative for localization, while embedding multiple scenes in parallel. We extend our previous MS-Transformer approach \cite{shavit2021learning} by introducing a mixed classification-regression architecture that improves the localization accuracy. Our method is evaluated on commonly benchmark indoor and outdoor datasets and has been shown to exceed both multi-scene and state-of-the-art single-scene absolute pose regressors.
Learning to Localize in Unseen Scenes with Relative Pose Regressors
Mar 05, 2023Relative pose regressors (RPRs) localize a camera by estimating its relative translation and rotation to a pose-labelled reference. Unlike scene coordinate regression and absolute pose regression methods, which learn absolute scene parameters, RPRs can (theoretically) localize in unseen environments, since they only learn the residual pose between camera pairs. In practice, however, the performance of RPRs is significantly degraded in unseen scenes. In this work, we propose to aggregate paired feature maps into latent codes, instead of operating on global image descriptors, in order to improve the generalization of RPRs. We implement aggregation with concatenation, projection, and attention operations (Transformer Encoders) and learn to regress the relative pose parameters from the resulting latent codes. We further make use of a recently proposed continuous representation of rotation matrices, which alleviates the limitations of the commonly used quaternions. Compared to state-of-the-art RPRs, our model is shown to localize significantly better in unseen environments, across both indoor and outdoor benchmarks, while maintaining competitive performance in seen scenes. We validate our findings and architecture design through multiple ablations. Our code and pretrained models is publicly available.
Camera Pose Auto-Encoders for Improving Pose Regression
Jul 12, 2022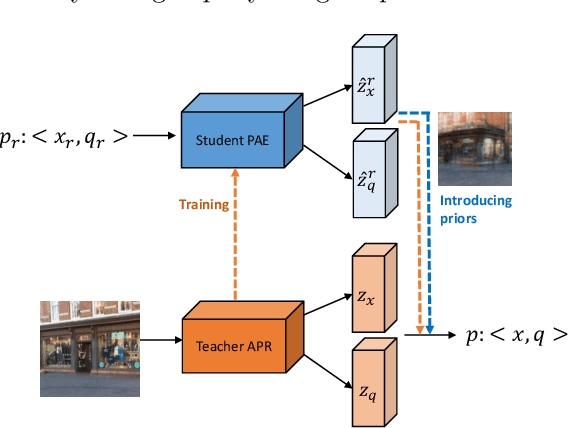

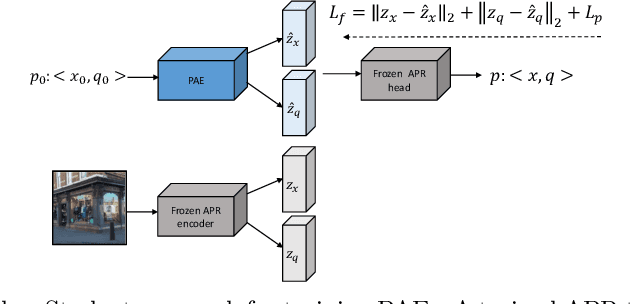
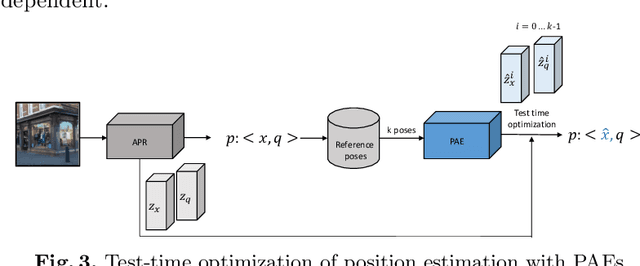
Absolute pose regressor (APR) networks are trained to estimate the pose of the camera given a captured image. They compute latent image representations from which the camera position and orientation are regressed. APRs provide a different tradeoff between localization accuracy, runtime, and memory, compared to structure-based localization schemes that provide state-of-the-art accuracy. In this work, we introduce Camera Pose Auto-Encoders (PAEs), multilayer perceptrons that are trained via a Teacher-Student approach to encode camera poses using APRs as their teachers. We show that the resulting latent pose representations can closely reproduce APR performance and demonstrate their effectiveness for related tasks. Specifically, we propose a light-weight test-time optimization in which the closest train poses are encoded and used to refine camera position estimation. This procedure achieves a new state-of-the-art position accuracy for APRs, on both the CambridgeLandmarks and 7Scenes benchmarks. We also show that train images can be reconstructed from the learned pose encoding, paving the way for integrating visual information from the train set at a low memory cost. Our code and pre-trained models are available at https://github.com/yolish/camera-pose-auto-encoders.
WT-MVSNet: Window-based Transformers for Multi-view Stereo
May 28, 2022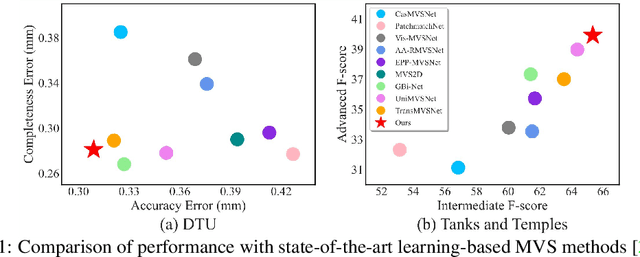
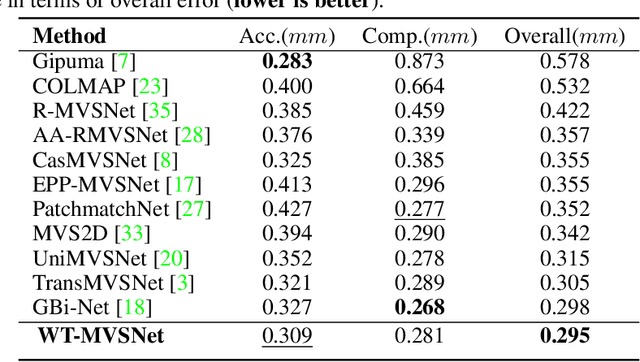
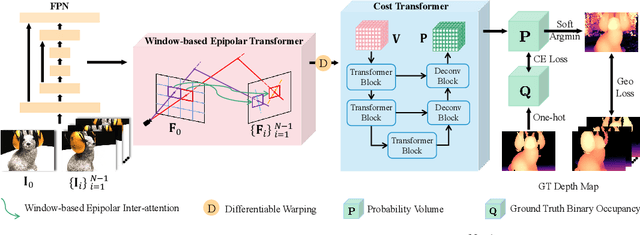
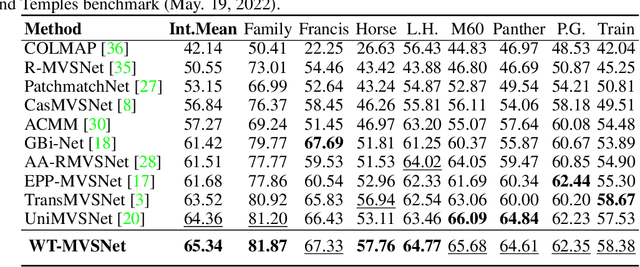
Recently, Transformers were shown to enhance the performance of multi-view stereo by enabling long-range feature interaction. In this work, we propose Window-based Transformers (WT) for local feature matching and global feature aggregation in multi-view stereo. We introduce a Window-based Epipolar Transformer (WET) which reduces matching redundancy by using epipolar constraints. Since point-to-line matching is sensitive to erroneous camera pose and calibration, we match windows near the epipolar lines. A second Shifted WT is employed for aggregating global information within cost volume. We present a novel Cost Transformer (CT) to replace 3D convolutions for cost volume regularization. In order to better constrain the estimated depth maps from multiple views, we further design a novel geometric consistency loss (Geo Loss) which punishes unreliable areas where multi-view consistency is not satisfied. Our WT multi-view stereo method (WT-MVSNet) achieves state-of-the-art performance across multiple datasets and ranks $1^{st}$ on Tanks and Temples benchmark.
Adversarial Learning of Hard Positives for Place Recognition
May 08, 2022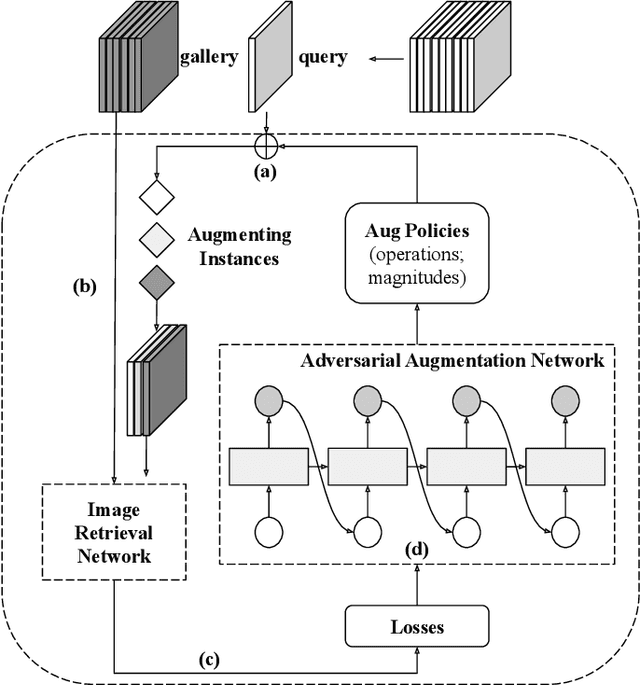
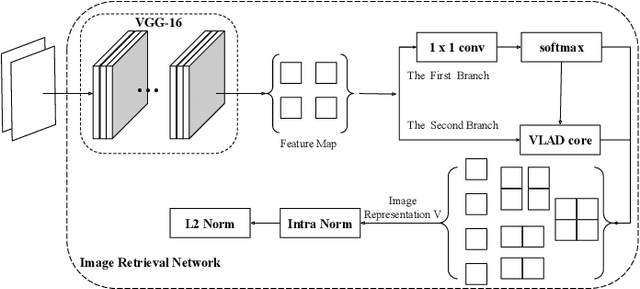

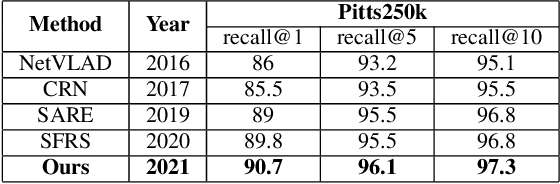
Image retrieval methods for place recognition learn global image descriptors that are used for fetching geo-tagged images at inference time. Recent works have suggested employing weak and self-supervision for mining hard positives and hard negatives in order to improve localization accuracy and robustness to visibility changes (e.g. in illumination or view point). However, generating hard positives, which is essential for obtaining robustness, is still limited to hard-coded or global augmentations. In this work we propose an adversarial method to guide the creation of hard positives for training image retrieval networks. Our method learns local and global augmentation policies which will increase the training loss, while the image retrieval network is forced to learn more powerful features for discriminating increasingly difficult examples. This approach allows the image retrieval network to generalize beyond the hard examples presented in the data and learn features that are robust to a wide range of variations. Our method achieves state-of-the-art recalls on the Pitts250 and Tokyo 24/7 benchmarks and outperforms recent image retrieval methods on the rOxford and rParis datasets by a noticeable margin.
ClusterGNN: Cluster-based Coarse-to-Fine Graph Neural Network for Efficient Feature Matching
Apr 25, 2022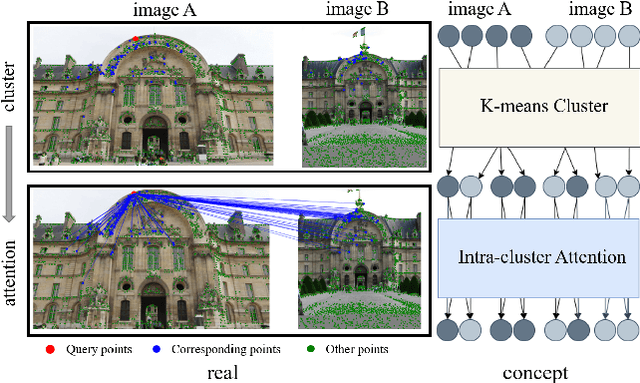
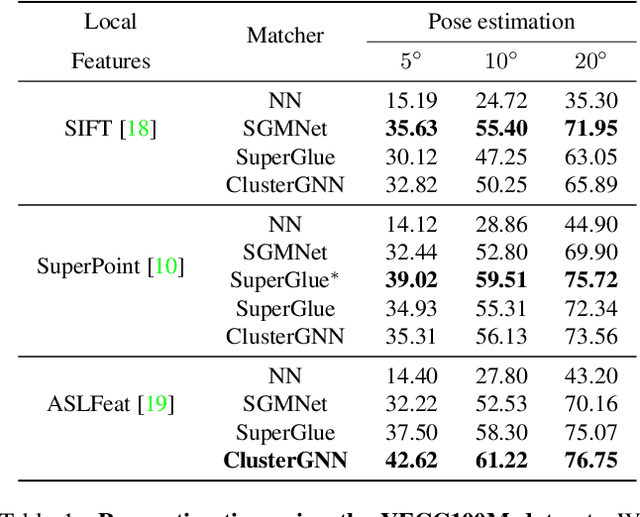
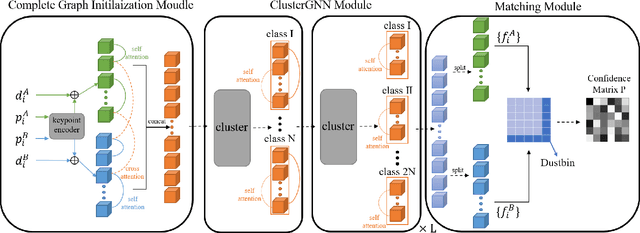
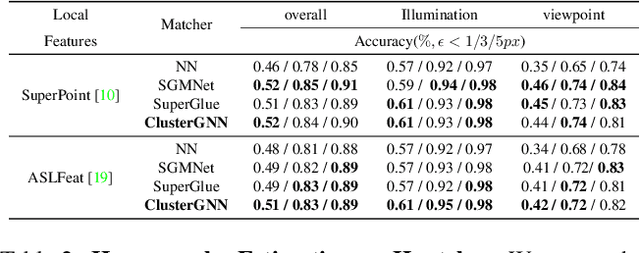
Graph Neural Networks (GNNs) with attention have been successfully applied for learning visual feature matching. However, current methods learn with complete graphs, resulting in a quadratic complexity in the number of features. Motivated by a prior observation that self- and cross- attention matrices converge to a sparse representation, we propose ClusterGNN, an attentional GNN architecture which operates on clusters for learning the feature matching task. Using a progressive clustering module we adaptively divide keypoints into different subgraphs to reduce redundant connectivity, and employ a coarse-to-fine paradigm for mitigating miss-classification within images. Our approach yields a 59.7% reduction in runtime and 58.4% reduction in memory consumption for dense detection, compared to current state-of-the-art GNN-based matching, while achieving a competitive performance on various computer vision tasks.