 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Lines to Shapes: Geometric-Constrained Segmentation of X-Ray Collimators via Hough Transform
Sep 04, 2025Collimation in X-ray imaging restricts exposure to the region-of-interest (ROI) and minimizes the radiation dose applied to the patient. The detection of collimator shadows is an essential image-based preprocessing step in digital radiography posing a challenge when edges get obscured by scattered X-ray radiation. Regardless, the prior knowledge that collimation forms polygonal-shaped shadows is evident. For this reason, we introduce a deep learning-based segmentation that is inherently constrained to its geometry. We achieve this by incorporating a differentiable Hough transform-based network to detect the collimation borders and enhance its capability to extract the information about the ROI center. During inference, we combine the information of both tasks to enable the generation of refined, line-constrained segmentation masks. We demonstrate robust reconstruction of collimated regions achieving median Hausdorff distances of 4.3-5.0mm on diverse test sets of real Xray images. While this application involves at most four shadow borders, our method is not fundamentally limited by a specific number of edges.
An Interpretable X-ray Style Transfer via Trainable Local Laplacian Filter
Nov 11, 2024



Radiologists have preferred visual impressions or 'styles' of X-ray images that are manually adjusted to their needs to support their diagnostic performance. In this work, we propose an automatic and interpretable X-ray style transfer by introducing a trainable version of the Local Laplacian Filter (LLF). From the shape of the LLF's optimized remap function, the characteristics of the style transfer can be inferred and reliability of the algorithm can be ensured. Moreover, we enable the LLF to capture complex X-ray style features by replacing the remap function with a Multi-Layer Perceptron (MLP) and adding a trainable normalization layer. We demonstrate the effectiveness of the proposed method by transforming unprocessed mammographic X-ray images into images that match the style of target mammograms and achieve a Structural Similarity Index (SSIM) of 0.94 compared to 0.82 of the baseline LLF style transfer method from Aubry et al.
Data-driven Modeling in Metrology -- A Short Introduction, Current Developments and Future Perspectives
Jun 24, 2024Mathematical models are vital to the field of metrology, playing a key role in the derivation of measurement results and the calculation of uncertainties from measurement data, informed by an understanding of the measurement process. These models generally represent the correlation between the quantity being measured and all other pertinent quantities. Such relationships are used to construct measurement systems that can interpret measurement data to generate conclusions and predictions about the measurement system itself. Classic models are typically analytical, built on fundamental physical principles. However, the rise of digital technology, expansive sensor networks, and high-performance computing hardware have led to a growing shift towards data-driven methodologies. This trend is especially prominent when dealing with large, intricate networked sensor systems in situations where there is limited expert understanding of the frequently changing real-world contexts. Here, we demonstrate the variety of opportunities that data-driven modeling presents, and how they have been already implemented in various real-world applications.
StyleX: A Trainable Metric for X-ray Style Distances
May 23, 2024



The progression of X-ray technology introduces diverse image styles that need to be adapted to the preferences of radiologists. To support this task, we introduce a novel deep learning-based metric that quantifies style differences of non-matching image pairs. At the heart of our metric is an encoder capable of generating X-ray image style representations. This encoder is trained without any explicit knowledge of style distances by exploiting Simple Siamese learning. During inference, the style representations produced by the encoder are used to calculate a distance metric for non-matching image pairs. Our experiments investigate the proposed concept for a disclosed reproducible and a proprietary image processing pipeline along two dimensions: First, we use a t-distributed stochastic neighbor embedding (t-SNE) analysis to illustrate that the encoder outputs provide meaningful and discriminative style representations. Second, the proposed metric calculated from the encoder outputs is shown to quantify style distances for non-matching pairs in good alignment with the human perception. These results confirm that our proposed method is a promising technique to quantify style differences, which can be used for guided style selection as well as automatic optimization of image pipeline parameters.
The Artificial Neural Twin -- Process Optimization and Continual Learning in Distributed Process Chains
Mar 27, 2024Industrial process optimization and control is crucial to increase economic and ecologic efficiency. However, data sovereignty, differing goals, or the required expert knowledge for implementation impede holistic implementation. Further, the increasing use of data-driven AI-methods in process models and industrial sensory often requires regular fine-tuning to accommodate distribution drifts. We propose the Artificial Neural Twin, which combines concepts from model predictive control, deep learning, and sensor networks to address these issues. Our approach introduces differentiable data fusion to estimate the state of distributed process steps and their dependence on input data. By treating the interconnected process steps as a quasi neural-network, we can backpropagate loss gradients for process optimization or model fine-tuning to process parameters or AI models respectively. The concept is demonstrated on a virtual machine park simulated in Unity, consisting of bulk material processes in plastic recycling.
Task-based Generation of Optimized Projection Sets using Differentiable Ranking
Mar 21, 2023


We present a method for selecting valuable projections in computed tomography (CT) scans to enhance image reconstruction and diagnosis. The approach integrates two important factors, projection-based detectability and data completeness, into a single feed-forward neural network. The network evaluates the value of projections, processes them through a differentiable ranking function and makes the final selection using a straight-through estimator. Data completeness is ensured through the label provided during training. The approach eliminates the need for heuristically enforcing data completeness, which may exclude valuable projections. The method is evaluated on simulated data in a non-destructive testing scenario, where the aim is to maximize the reconstruction quality within a specified region of interest. We achieve comparable results to previous methods, laying the foundation for using reconstruction-based loss functions to learn the selection of projections.
Optimizing CT Scan Geometries With and Without Gradients
Feb 13, 2023In computed tomography (CT), the projection geometry used for data acquisition needs to be known precisely to obtain a clear reconstructed image. Rigid patient motion is a cause for misalignment between measured data and employed geometry. Commonly, such motion is compensated by solving an optimization problem that, e.g., maximizes the quality of the reconstructed image with respect to the projection geometry. So far, gradient-free optimization algorithms have been utilized to find the solution for this problem. Here, we show that gradient-based optimization algorithms are a possible alternative and compare the performance to their gradient-free counterparts on a benchmark motion compensation problem. Gradient-based algorithms converge substantially faster while being comparable to gradient-free algorithms in terms of capture range and robustness to the number of free parameters. Hence, gradient-based optimization is a viable alternative for the given type of problems.
Geometric Constraints Enable Self-Supervised Sinogram Inpainting in Sparse-View Tomography
Feb 13, 2023


The diagnostic quality of computed tomography (CT) scans is usually restricted by the induced patient dose, scan speed, and image quality. Sparse-angle tomographic scans reduce radiation exposure and accelerate data acquisition, but suffer from image artifacts and noise. Existing image processing algorithms can restore CT reconstruction quality but often require large training data sets or can not be used for truncated objects. This work presents a self-supervised projection inpainting method that allows learning missing projective views via gradient-based optimization. By reconstructing independent stacks of projection data, a self-supervised loss is calculated in the CT image domain and used to directly optimize projection image intensities to match the missing tomographic views constrained by the projection geometry. Our experiments on real X-ray microscope (XRM) tomographic mouse tibia bone scans show that our method improves reconstructions by 3.1-7.4%/7.7-17.6% in terms of PSNR/SSIM with respect to the interpolation baseline. Our approach is applicable as a flexible self-supervised projection inpainting tool for tomographic applications.
Is Medical Chest X-ray Data Anonymous?
Mar 15, 2021
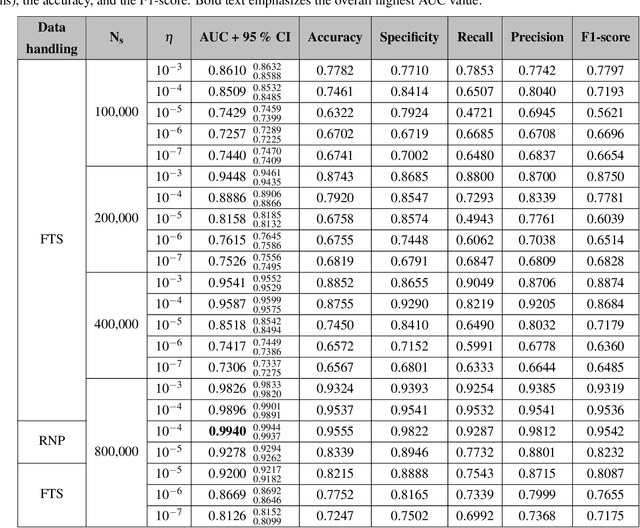
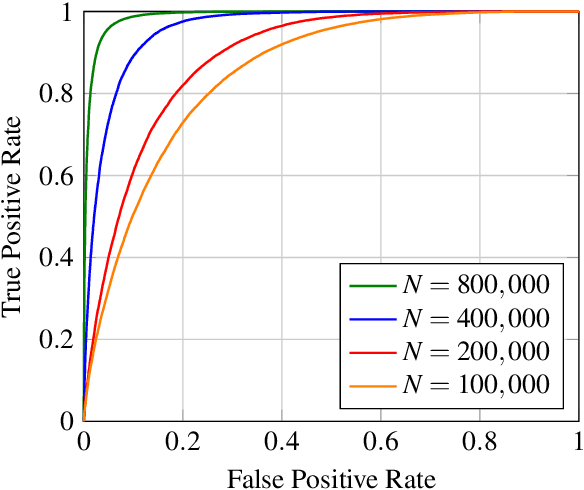
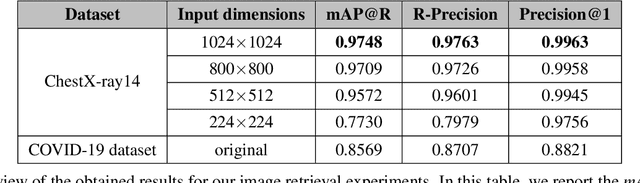
With the rise and ever-increasing potential of deep learning techniques in recent years, publicly available medical data sets became a key factor to enable reproducible development of diagnostic algorithms in the medical domain. Medical data contains sensitive patient-related information and is therefore usually anonymized by removing patient identifiers, e.g., patient names before publication. To the best of our knowledge, we are the first to show that a well-trained deep learning system is able to recover the patient identity from chest X-ray data. We demonstrate this using the publicly available large-scale ChestX-ray14 dataset, a collection of 112,120 frontal-view chest X-ray images from 30,805 unique patients. Our verification system is able to identify whether two frontal chest X-ray images are from the same person with an AUC of 0.9940 and a classification accuracy of 95.55%. We further highlight that the proposed system is able to reveal the same person even ten and more years after the initial scan. When pursuing a retrieval approach, we observe an mAP@R of 0.9748 and a precision@1 of 0.9963. Based on this high identification rate, a potential attacker may leak patient-related information and additionally cross-reference images to obtain more information. Thus, there is a great risk of sensitive content falling into unauthorized hands or being disseminated against the will of the concerned patients. Especially during the COVID-19 pandemic, numerous chest X-ray datasets have been published to advance research. Therefore, such data may be vulnerable to potential attacks by deep learning-based re-identification algorithms.
X-ray Scatter Estimation Using Deep Splines
Jan 22, 2021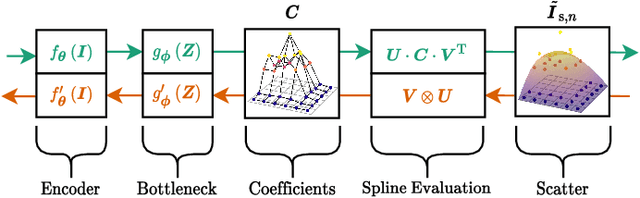
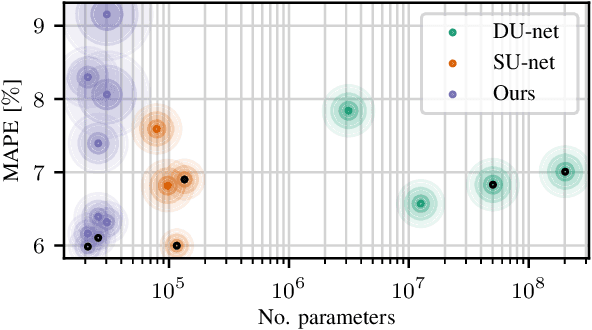
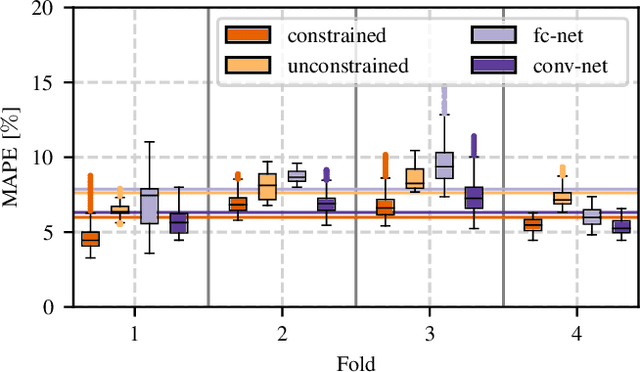
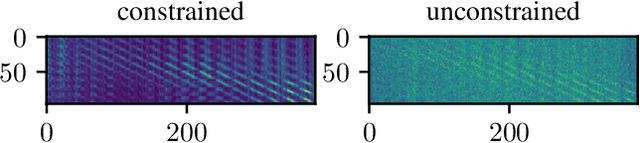
Algorithmic X-ray scatter compensation is a desirable technique in flat-panel X-ray imaging and cone-beam computed tomography. State-of-the-art U-net based image translation approaches yielded promising results. As there are no physics constraints applied to the output of the U-Net, it cannot be ruled out that it yields spurious results. Unfortunately, those may be misleading in the context of medical imaging. To overcome this problem, we propose to embed B-splines as a known operator into neural networks. This inherently limits their predictions to well-behaved and smooth functions. In a study using synthetic head and thorax data as well as real thorax phantom data, we found that our approach performed on par with U-net when comparing both algorithms based on quantitative performance metrics. However, our approach not only reduces runtime and parameter complexity, but we also found it much more robust to unseen noise levels. While the U-net responded with visible artifacts, our approach preserved the X-ray signal's frequency characteristics.