 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisoning MorphNet for Clean-Label Backdoor Attack to Point Clouds
May 11, 2021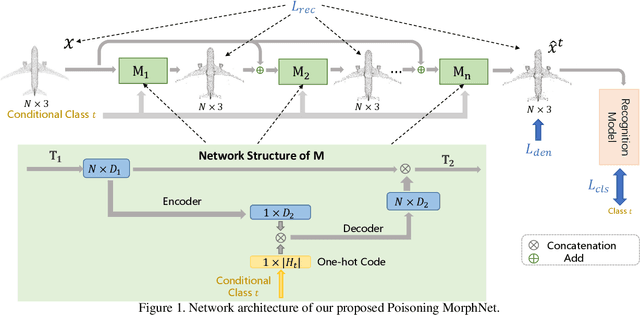

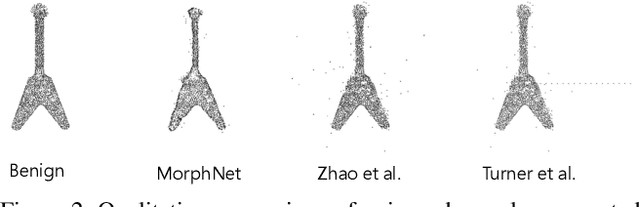

This paper presents Poisoning MorphNet, the first backdoor attack method on point clouds. Conventional adversarial attack takes place in the inference stage, often fooling a model by perturbing samples. In contrast, backdoor attack aims to implant triggers into a model during the training stage, such that the victim model acts normally on the clean data unless a trigger is present in a sample. This work follows a typical setting of clean-label backdoor attack, where a few poisoned samples (with their content tampered yet labels unchanged) are injected into the training set. The unique contributions of MorphNet are two-fold. First, it is key to ensure the implanted triggers both visually imperceptible to humans and lead to high attack success rate on the point clouds. To this end, MorphNet jointly optimizes two objectives for sample-adaptive poisoning: a reconstruction loss that preserves the visual similarity between benign / poisoned point clouds, and a classification loss that enforces a modern recognition model of point clouds tends to mis-classify the poisoned sample to a pre-specified target category. This implicitly conducts spectral separation over point clouds, hiding sample-adaptive triggers in fine-grained high-frequency details. Secondly, existing backdoor attack methods are mainly designed for image data, easily defended by some point cloud specific operations (such as denoising). We propose a third loss in MorphNet for suppressing isolated points, leading to improved resistance to denoising-based defense. Comprehensive evaluations are conducted on ModelNet40 and ShapeNetcorev2. Our proposed Poisoning MorphNet outstrips all previous methods with clear margins.
Two-Stream Video Classification with Cross-Modality Attention
Aug 01, 2019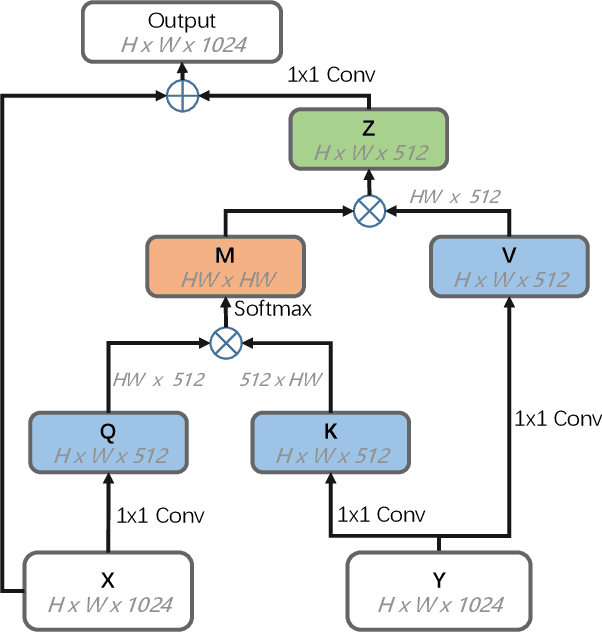
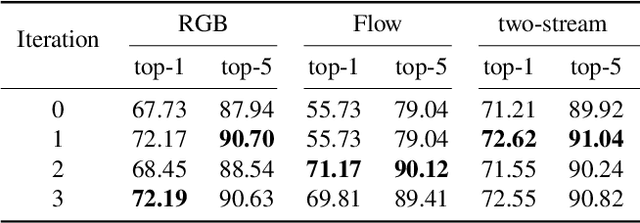
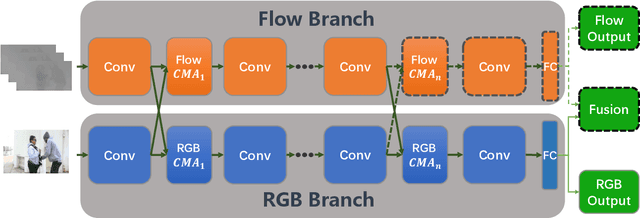

Fusing multi-modality information is known to be able to effectively bring significant improvement in video classification. However, the most popular method up to now is still simply fusing each stream's prediction scores at the last stage. A valid question is whether there exists a more effective method to fuse information cross modality. With the development of attention mechanism in natural language processing, there emerge many successful applications of attention in the field of computer vision. In this paper, we propose a cross-modality attention operation, which can obtain information from other modality in a more effective way than two-stream. Correspondingly we implement a compatible block named CMA block, which is a wrapper of our proposed attention operation. CMA can be plugged into many existing architectures. In the experiments, we comprehensively compare our method with two-stream and non-local models widely used in video classification. All experiments clearly demonstrate strong performance superiority by our proposed method. We also analyze the advantages of the CMA block by visualizing the attention map, which intuitively shows how the block helps the final prediction.