 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SOIT: Segmenting Objects with Instance-Aware Transformers
Dec 23, 2021
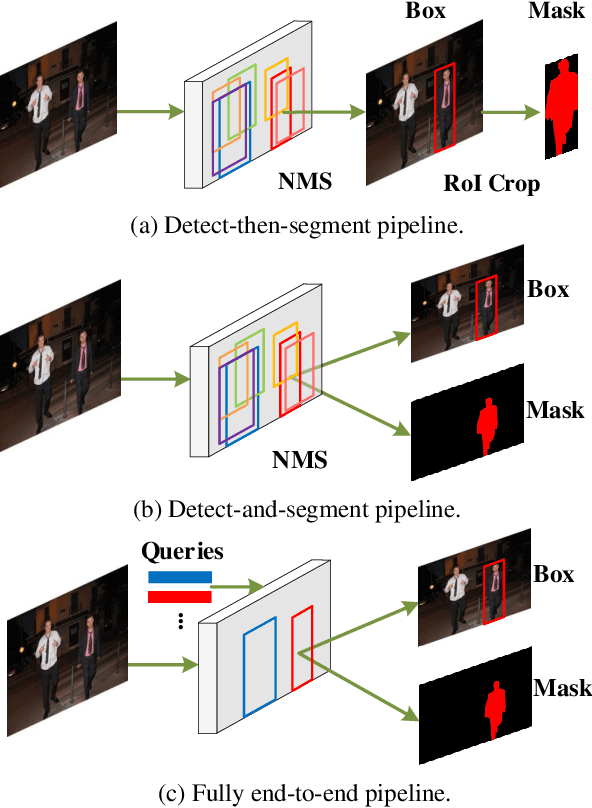
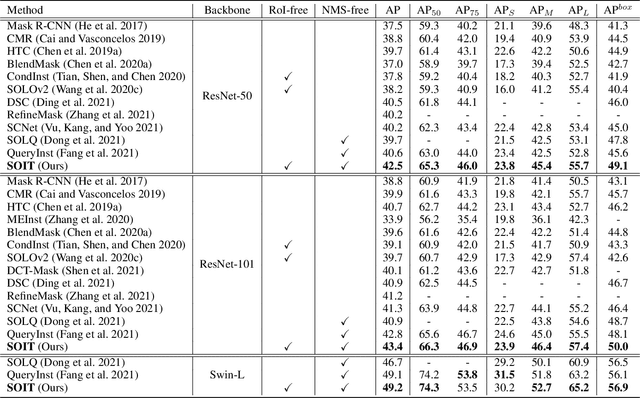
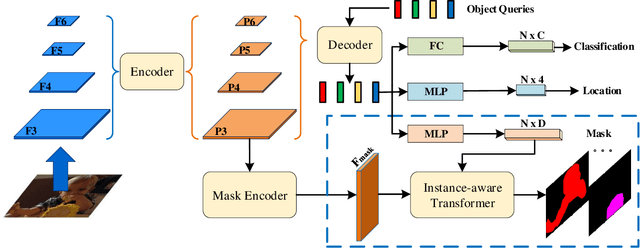
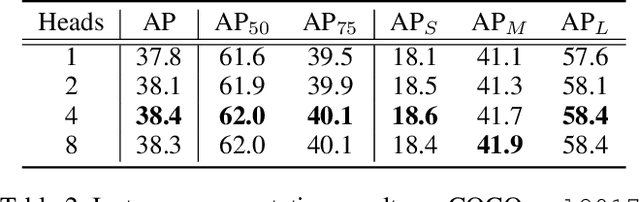
This paper presents an end-to-end instance segmentation framework, termed SOIT, that Segments Objects with Instance-aware Transformers. Inspired by DETR \cite{carion2020end}, our method views instance segmentation as a direct set prediction problem and effectively removes the need for many hand-crafted components like RoI cropping, one-to-many label assignment, and non-maximum suppression (NMS). In SOIT, multiple queries are learned to directly reason a set of object embeddings of semantic category, bounding-box location, and pixel-wise mask in parallel under the global image context. The class and bounding-box can be easily embedded by a fixed-length vector. The pixel-wise mask, especially, is embedded by a group of parameters to construct a lightweight instance-aware transformer. Afterward, a full-resolution mask is produced by the instance-aware transformer without involving any RoI-based operation. Overall, SOIT introduces a simple single-stage instance segmentation framework that is both RoI- and NMS-free. Experimental results on the MS COCO dataset demonstrate that SOIT outperforms state-of-the-art instance segmentation approaches significantly. Moreover, the joint learning of multiple tasks in a unified query embedding can also substantially improve the detection performance. Code is available at \url{https://github.com/yuxiaodongHRI/SOIT}.
Blind Image Restoration without Prior Knowledge
Mar 03, 2020
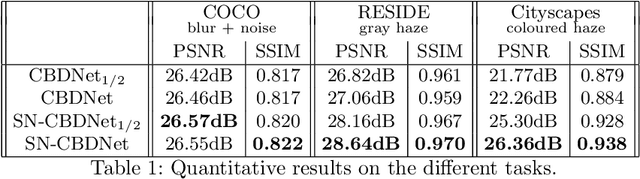
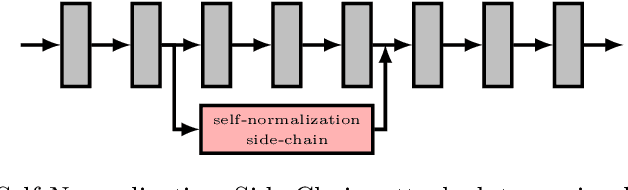
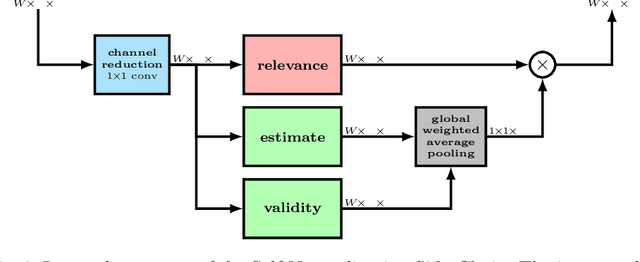
Many image restoration techniques are highly dependent on the degradation used during training, and their performance declines significantly when applied to slightly different input. Blind and universal techniques attempt to mitigate this by producing a trained model that can adapt to varying conditions. However, blind techniques to date require prior knowledge of the degradation process, and assumptions regarding its parameter-space. In this paper we present the Self-Normalization Side-Chain (SCNC), a novel approach to blind universal restoration in which no prior knowledge of the degradation is needed. This module can be added to any existing CNN topology, and is trained along with the rest of the network in an end-to-end manner. The imaging parameters relevant to the task, as well as their dynamics, are deduced from the variety in the training data. We apply our solution to several image restoration tasks, and demonstrate that the SNSC encodes the degradation-parameters, improving restoration performance.
Contrastive Representation Learning with Trainable Augmentation Channel
Nov 15, 2021

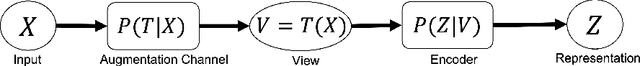

In contrastive representation learning, data representation is trained so that it can classify the image instances even when the images are altered by augmentations. However, depending on the datasets, some augmentations can damage the information of the images beyond recognition, and such augmentations can result in collapsed representations. We present a partial solution to this problem by formalizing a stochastic encoding process in which there exist a tug-of-war between the data corruption introduced by the augmentations and the information preserved by the encoder. We show that, with the infoMax objective based on this framework, we can learn a data-dependent distribution of augmentations to avoid the collapse of the representation.
G-image Segmentation: Similarity-preserving Fuzzy C-Means with Spatial Information Constraint in Wavelet Space
Jul 01, 2020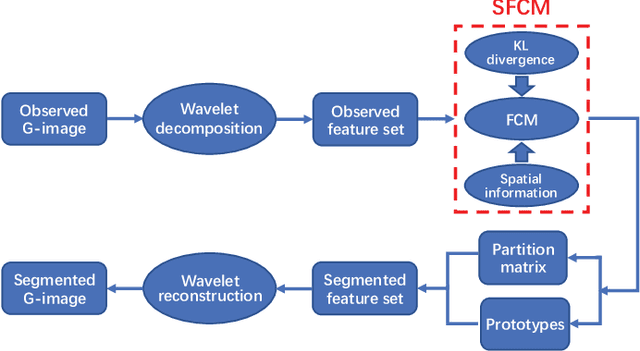
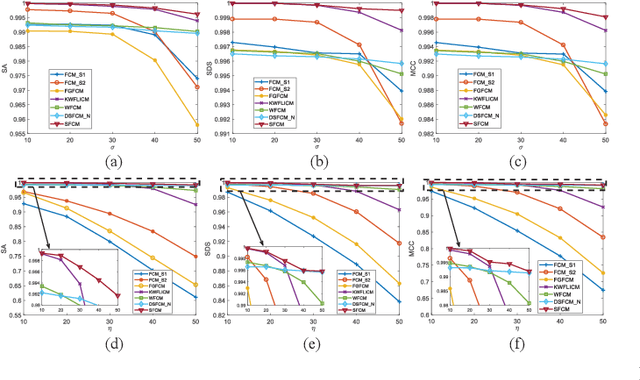
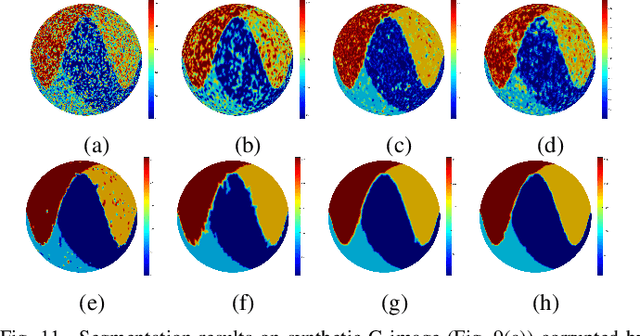
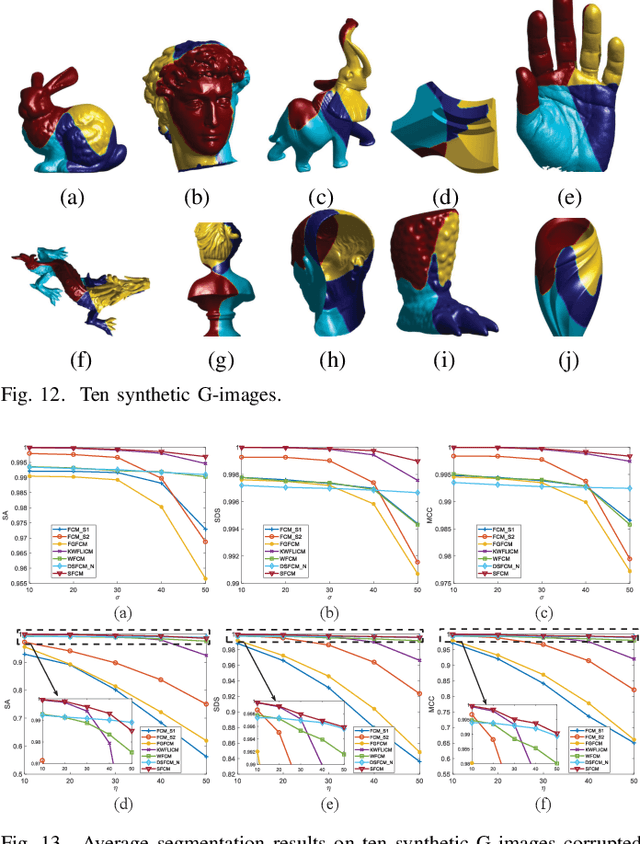
G-images refer to image data defined on irregular graph domains. This work elaborates a similarity-preserving Fuzzy C-Means (FCM) algorithm for G-image segmentation and aims to develop techniques and tools for segmenting G-images. To preserve the membership similarity between an arbitrary image pixel and its neighbors, a Kullback-Leibler divergence term on membership partition is introduced as a part of FCM. As a result, similarity-preserving FCM is developed by considering spatial information of image pixels for its robustness enhancement. Due to superior characteristics of a wavelet space, the proposed FCM is performed in this space rather than Euclidean one used in conventional FCM to secure its high robustness. Experiments on synthetic and real-world G-images demonstrate that it indeed achieves higher robustness and performance than the state-of-the-art FCM algorithms. Moreover, it requires less computation than most of them.
IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning
Oct 25, 2021
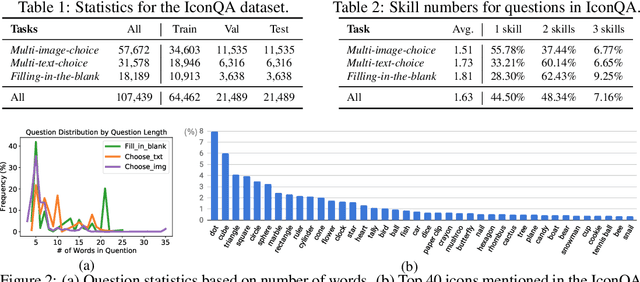
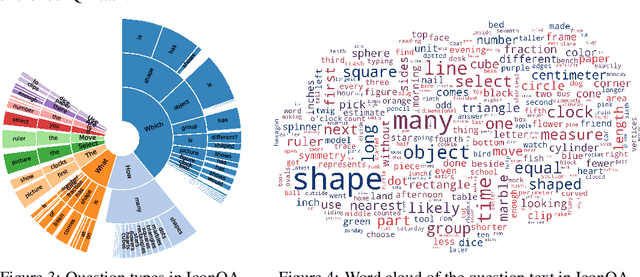

Current visual question answering (VQA) tasks mainly consider answering human-annotated questions for natural images. However, aside from natural images, abstract diagrams with semantic richness are still understudied in visual understanding and reasoning research. In this work, we introduce a new challenge of Icon Question Answering (IconQA) with the goal of answering a question in an icon image context. We release IconQA, a large-scale dataset that consists of 107,439 questions and three sub-tasks: multi-image-choice, multi-text-choice, and filling-in-the-blank. The IconQA dataset is inspired by real-world diagram word problems that highlight the importance of abstract diagram understanding and comprehensive cognitive reasoning. Thus, IconQA requires not only perception skills like object recognition and text understanding, but also diverse cognitive reasoning skills, such as geometric reasoning, commonsense reasoning, and arithmetic reasoning. To facilitate potential IconQA models to learn semantic representations for icon images, we further release an icon dataset Icon645 which contains 645,687 colored icons on 377 classes. We conduct extensive user studies and blind experiments and reproduce a wide range of advanced VQA methods to benchmark the IconQA task. Also, we develop a strong IconQA baseline Patch-TRM that applies a pyramid cross-modal Transformer with input diagram embeddings pre-trained on the icon dataset. IconQA and Icon645 are available at https://iconqa.github.io.
Linguistic Structure Guided Context Modeling for Referring Image Segmentation
Oct 01, 2020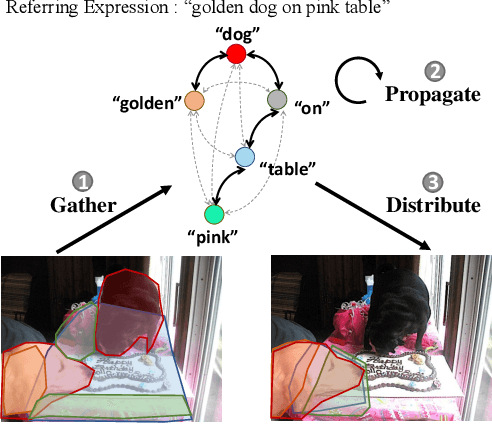
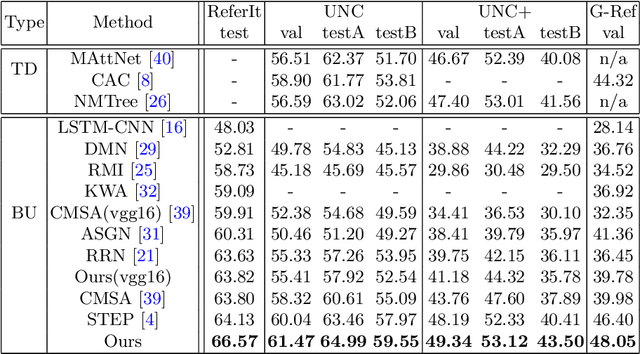
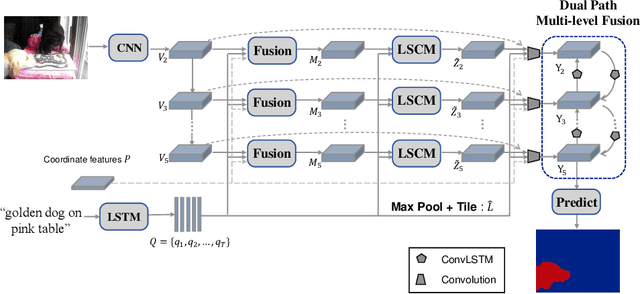
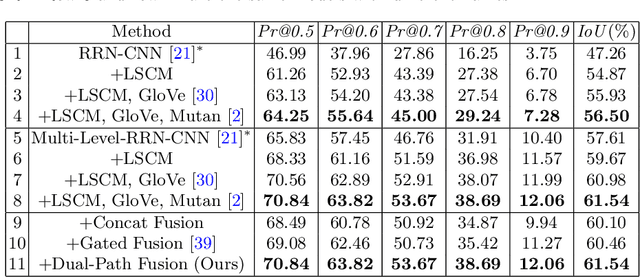
Referring image segmentation aims to predict the foreground mask of the object referred by a natural language sentence. Multimodal context of the sentence is crucial to distinguish the referent from the background. Existing methods either insufficiently or redundantly model the multimodal context.To tackle this problem, we propose a "gather-propagate-distribute" scheme to model multimodal context by cross-modal interaction and implement this scheme as a novel Linguistic Structure guided Context Modeling (LSCM) module. Our LSCM module builds a Dependency Parsing Tree suppressed Word Graph (DPT-WG) which guides all the words to include valid multimodal context of the sentence while excluding disturbing ones through three steps over the multimodal feature, i.e., gathering, constrained propagation and distributing. Extensive experiments on four benchmarks demonstrate that our method outperforms all the previous state-of-the-arts.
Multi-Scale Progressive Fusion Network for Single Image Deraining
Mar 28, 2020
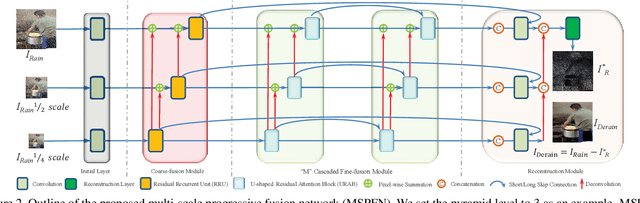
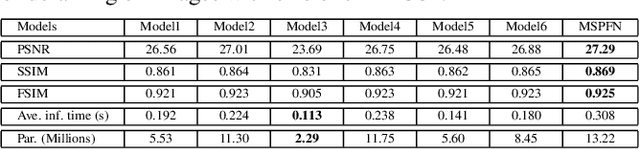
Rain streaks in the air appear in various blurring degrees and resolutions due to different distances from their positions to the camera. Similar rain patterns are visible in a rain image as well as its multi-scale (or multi-resolution) versions, which makes it possible to exploit such complementary information for rain streak representation. In this work, we explore the multi-scale collaborative representation for rain streaks from the perspective of input image scales and hierarchical deep features in a unified framework, termed multi-scale progressive fusion network (MSPFN) for single image rain streak removal. For similar rain streaks at different positions, we employ recurrent calculation to capture the global texture, thus allowing to explore the complementary and redundant information at the spatial dimension to characterize target rain streaks. Besides, we construct multi-scale pyramid structure, and further introduce the attention mechanism to guide the fine fusion of this correlated information from different scales. This multi-scale progressive fusion strategy not only promotes the cooperative representation, but also boosts the end-to-end training. Our proposed method is extensively evaluated on several benchmark datasets and achieves state-of-the-art results. Moreover, we conduct experiments on joint deraining, detection, and segmentation tasks, and inspire a new research direction of vision task-driven image deraining. The source code is available at \url{https://github.com/kuihua/MSPFN}.
B-SCST: Bayesian Self-Critical Sequence Training for Image Captioning
Apr 06, 2020
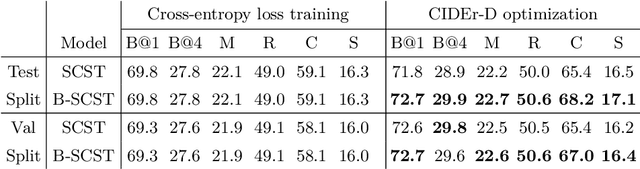
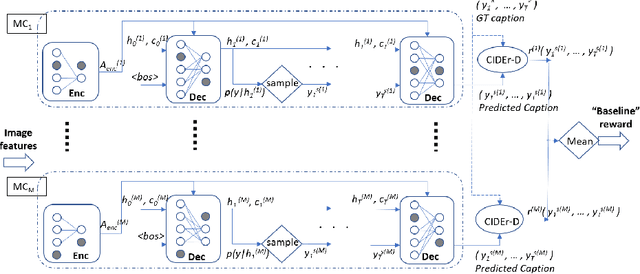
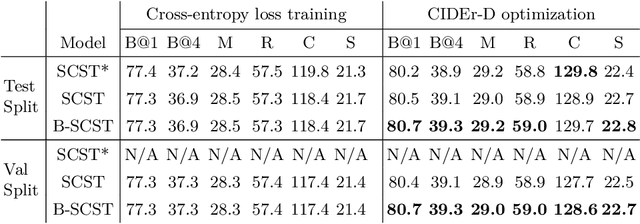
Bayesian deep neural networks (DNN) provide a mathematically grounded framework to quantify uncertainty in their predictions. We propose a Bayesian variant of policy-gradient based reinforcement learning training technique for image captioning models to directly optimize non-differentiable image captioning quality metrics such as CIDEr-D. We extend the well-known Self-Critical Sequence Training (SCST) approach for image captioning models by incorporating Bayesian inference, and refer to it as B-SCST. The "baseline" reward for the policy-gradients in B-SCST is generated by averaging predictive quality metrics (CIDEr-D) of the captions drawn from the distribution obtained using a Bayesian DNN model. This predictive distribution is inferred using Monte Carlo (MC) dropout, which is one of the standard ways to approximate variational inference. We observe that B-SCST improves all the standard captioning quality scores on both Flickr30k and MS COCO datasets, compared to the SCST approach. We also provide a detailed study of uncertainty quantification for the predicted captions, and demonstrate that it correlates well with the CIDEr-D scores. To our knowledge, this is the first such analysis, and it can pave way to more practical image captioning solutions with interpretable models.
Joint optimization of system design and reconstruction in MIMO radar imaging
Oct 07, 2021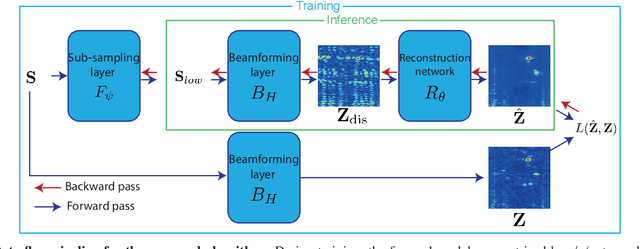
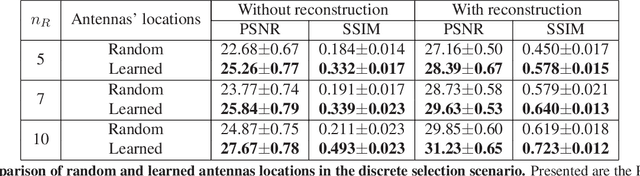
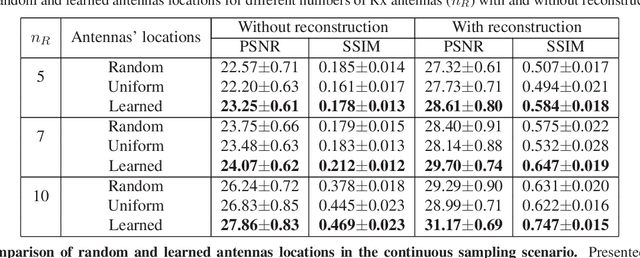
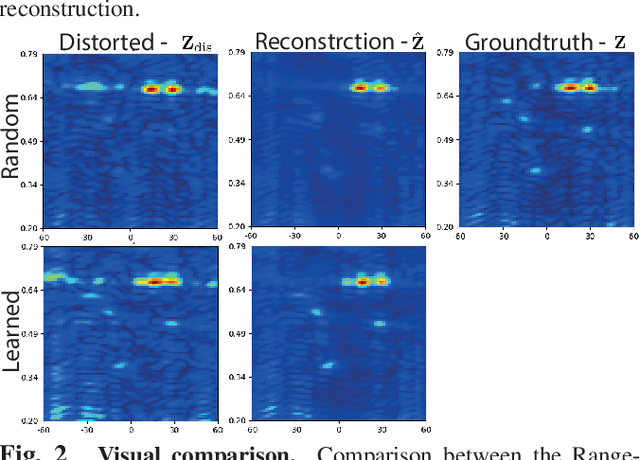
Multiple-input multiple-output (MIMO) radar is one of the leading depth sensing modalities. However, the usage of multiple receive channels lead to relative high costs and prevent the penetration of MIMOs in many areas such as the automotive industry. Over the last years, few studies concentrated on designing reduced measurement schemes and image reconstruction schemes for MIMO radars, however these problems have been so far addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of simultaneous learning-based design of the acquisition and reconstruction schemes, manifesting significant improvement in the reconstruction quality. Inspired by these successes, in this work, we propose to learn MIMO acquisition parameters in the form of receive (Rx) antenna elements locations jointly with an image neural-network based reconstruction. To this end, we propose an algorithm for training the combined acquisition-reconstruction pipeline end-to-end in a differentiable way. We demonstrate the significance of using our learned acquisition parameters with and without the neural-network reconstruction.
Image-Guided Navigation of a Robotic Ultrasound Probe for Autonomous Spinal Sonography Using a Shadow-aware Dual-Agent Framework
Nov 03, 2021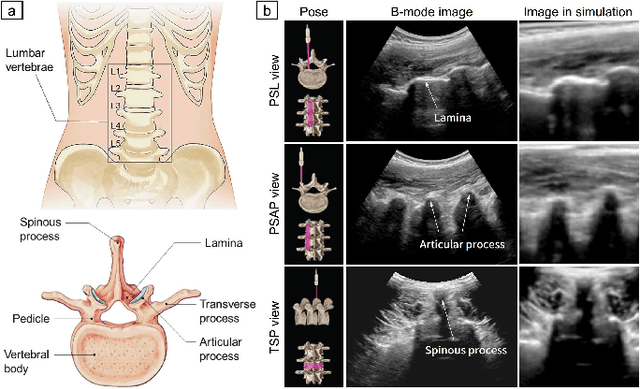
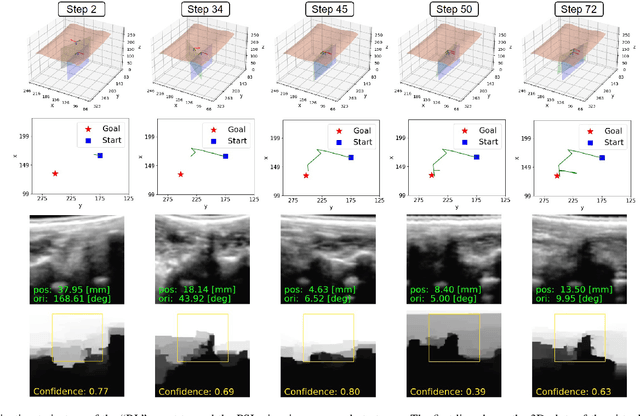
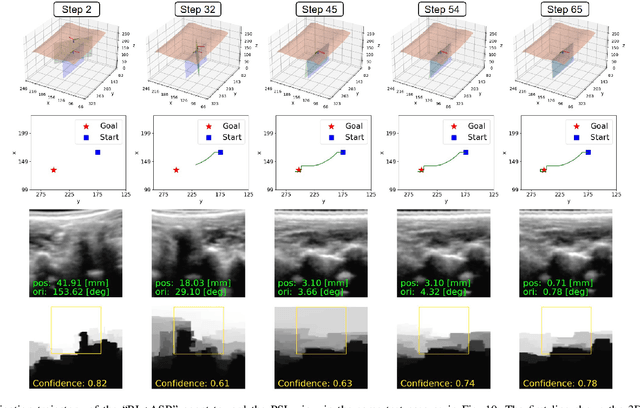
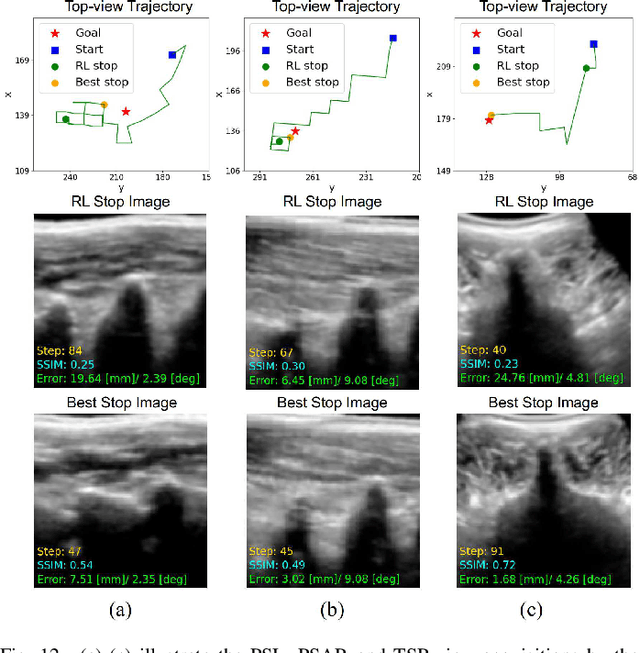
Ultrasound (US) imaging is commonly used to assist in the diagnosis and interventions of spine diseases, while the standardized US acquisitions performed by manually operating the probe require substantial experience and training of sonographers. In this work, we propose a novel dual-agent framework that integrates a reinforcement learning (RL) agent and a deep learning (DL) agent to jointly determine the movement of the US probe based on the real-time US images, in order to mimic the decision-making process of an expert sonographer to achieve autonomous standard view acquisitions in spinal sonography. Moreover, inspired by the nature of US propagation and the characteristics of the spinal anatomy, we introduce a view-specific acoustic shadow reward to utilize the shadow information to implicitly guide the navigation of the probe toward different standard views of the spine. Our method is validated in both quantitative and qualitative experiments in a simulation environment built with US data acquired from $17$ volunteers. The average navigation accuracy toward different standard views achieves $5.18mm/5.25^\circ$ and $12.87mm/17.49^\circ$ in the intra- and inter-subject settings, respectively. The results demonstrate that our method can effectively interpret the US images and navigate the probe to acquire multiple standard views of the spine.