 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Omnifont Persian OCR System Using Primitives
Feb 13, 2022
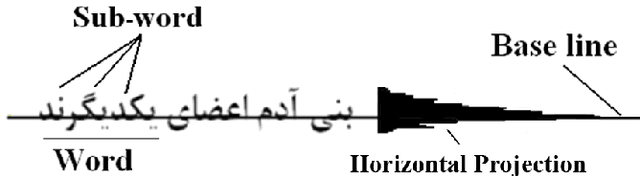
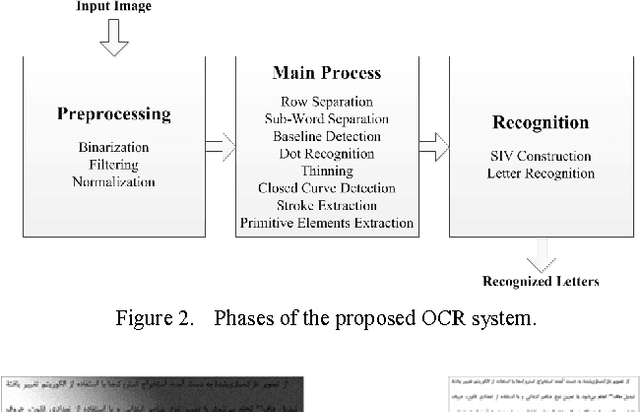


In this paper, we introduce a model-based omnifont Persian OCR system. The system uses a set of 8 primitive elements as structural features for recognition. First, the scanned document is preprocessed. After normalizing the preprocessed image, text rows and sub-words are separated and then thinned. After recognition of dots in sub-words, strokes are extracted and primitive elements of each sub-word are recognized using the strokes. Finally, the primitives are compared with a predefined set of character identification vectors in order to identify sub-word characters. The separation and recognition steps of the system are concurrent, eliminating unavoidable errors of independent separation of letters. The system has been tested on documents with 14 standard Persian fonts in 6 sizes. The achieved precision is 97.06%.
Answer Questions with Right Image Regions: A Visual Attention Regularization Approach
Feb 03, 2021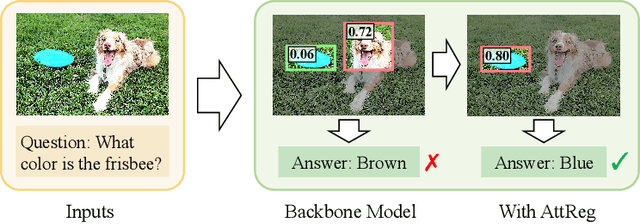
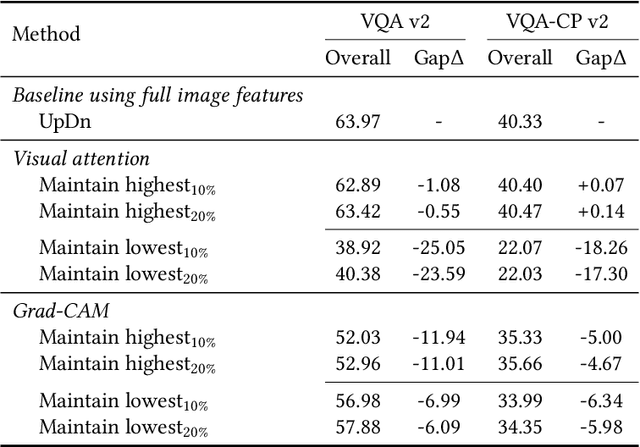
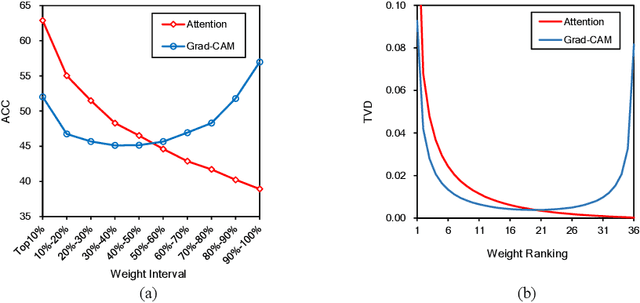
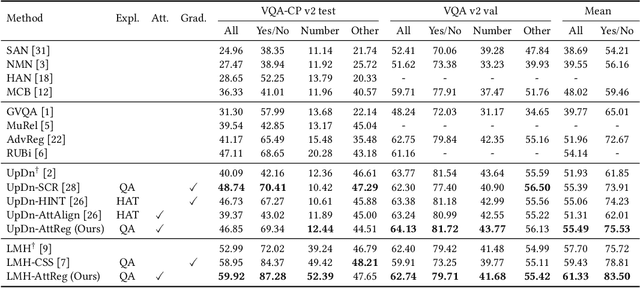
Visual attention in Visual Question Answering (VQA) targets at locating the right image regions regarding the answer prediction. However, recent studies have pointed out that the highlighted image regions from the visual attention are often irrelevant to the given question and answer, leading to model confusion for correct visual reasoning. To tackle this problem, existing methods mostly resort to aligning the visual attention weights with human attentions. Nevertheless, gathering such human data is laborious and expensive, making it burdensome to adapt well-developed models across datasets. To address this issue, in this paper, we devise a novel visual attention regularization approach, namely AttReg, for better visual grounding in VQA. Specifically, AttReg firstly identifies the image regions which are essential for question answering yet unexpectedly ignored (i.e., assigned with low attention weights) by the backbone model. And then a mask-guided learning scheme is leveraged to regularize the visual attention to focus more on these ignored key regions. The proposed method is very flexible and model-agnostic, which can be integrated into most visual attention-based VQA models and require no human attention supervision. Extensive experiments over three benchmark datasets, i.e., VQA-CP v2, VQA-CP v1, and VQA v2, have been conducted to evaluate the effectiveness of AttReg. As a by-product, when incorporating AttReg into the strong baseline LMH, our approach can achieve a new state-of-the-art accuracy of 59.92% with an absolute performance gain of 6.93% on the VQA-CP v2 benchmark dataset. In addition to the effectiveness validation, we recognize that the faithfulness of the visual attention in VQA has not been well explored in literature. In the light of this, we propose to empirically validate such property of visual attention and compare it with the prevalent gradient-based approaches.
On the Issues of TrueDepth Sensor Data for Computer Vision Tasks Across Different iPad Generations
Jan 26, 2022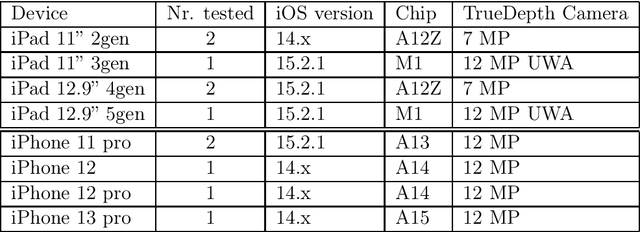
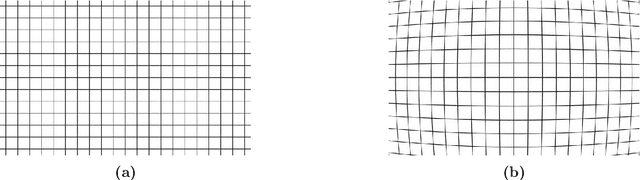

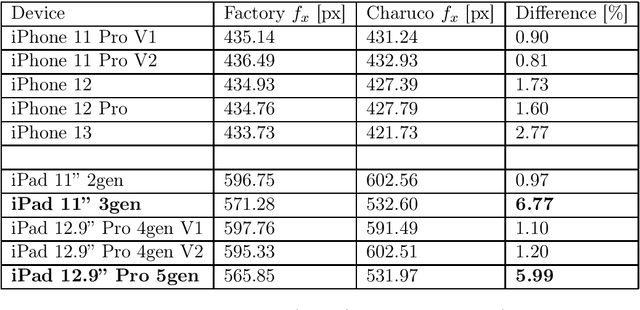
In 2017 Apple introduced the TrueDepth sensor with the iPhone X release. Although its primary use case is biometric face recognition, the exploitation of accurate depth data for other computer vision tasks like segmentation, portrait image generation and metric 3D reconstruction seems natural and lead to the development of various applications. In this report, we investigate the reliability of TrueDepth data - accessed through two different APIs - on various devices including different iPhone and iPad generations and reveal two different and significant issues on all tested iPads.
Auto-Encoding Knowledge Graph for Unsupervised Medical Report Generation
Nov 15, 2021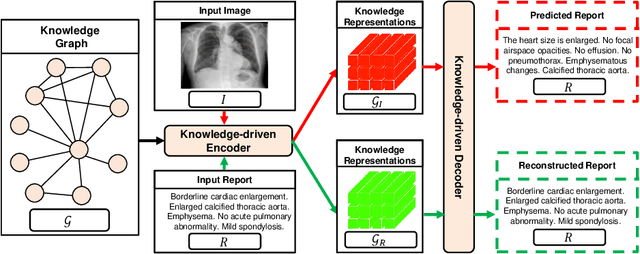
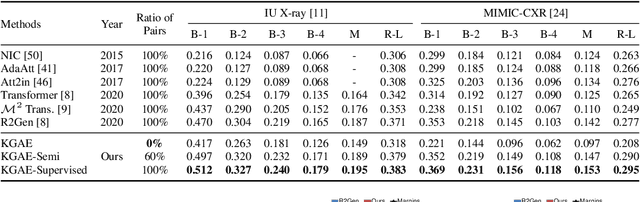
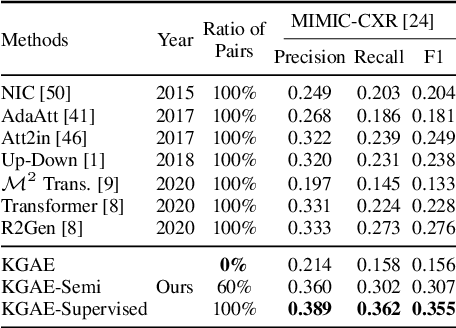

Medical report generation, which aims to automatically generate a long and coherent report of a given medical image, has been receiving growing research interests. Existing approaches mainly adopt a supervised manner and heavily rely on coupled image-report pairs. However, in the medical domain, building a large-scale image-report paired dataset is both time-consuming and expensive. To relax the dependency on paired data, we propose an unsupervised model Knowledge Graph Auto-Encoder (KGAE) which accepts independent sets of images and reports in training. KGAE consists of a pre-constructed knowledge graph, a knowledge-driven encoder and a knowledge-driven decoder. The knowledge graph works as the shared latent space to bridge the visual and textual domains; The knowledge-driven encoder projects medical images and reports to the corresponding coordinates in this latent space and the knowledge-driven decoder generates a medical report given a coordinate in this space. Since the knowledge-driven encoder and decoder can be trained with independent sets of images and reports, KGAE is unsupervised. The experiments show that the unsupervised KGAE generates desirable medical reports without using any image-report training pairs. Moreover, KGAE can also work in both semi-supervised and supervised settings, and accept paired images and reports in training. By further fine-tuning with image-report pairs, KGAE consistently outperforms the current state-of-the-art models on two datasets.
Using a GAN to Generate Adversarial Examples to Facial Image Recognition
Nov 30, 2021
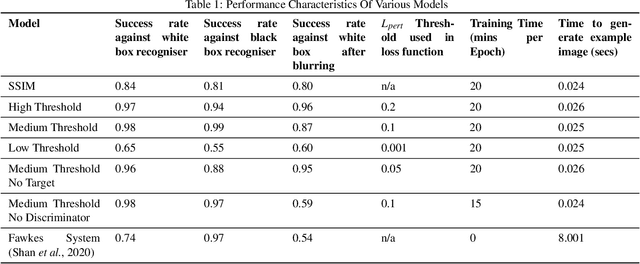
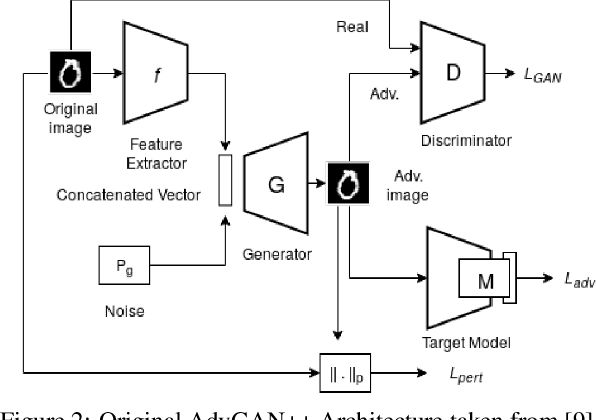
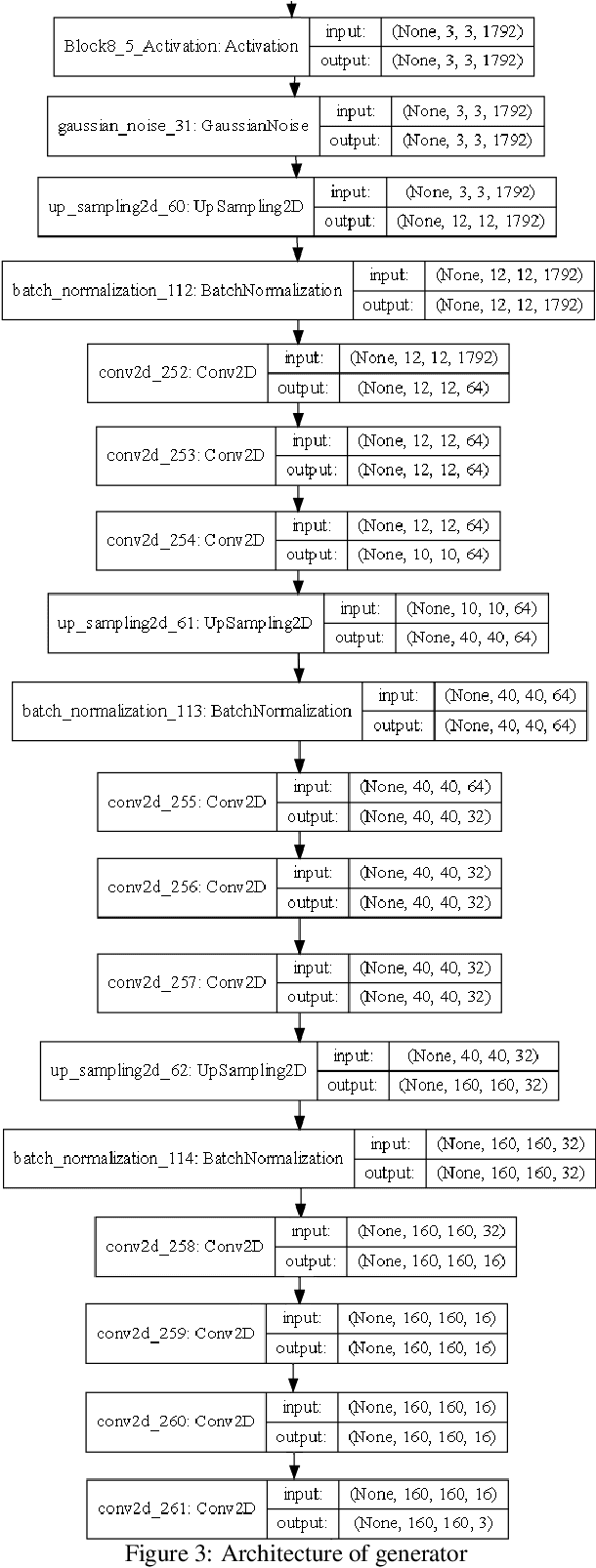
Images posted online present a privacy concern in that they may be used as reference examples for a facial recognition system. Such abuse of images is in violation of privacy rights but is difficult to counter. It is well established that adversarial example images can be created for recognition systems which are based on deep neural networks. These adversarial examples can be used to disrupt the utility of the images as reference examples or training data. In this work we use a Generative Adversarial Network (GAN) to create adversarial examples to deceive facial recognition and we achieve an acceptable success rate in fooling the face recognition. Our results reduce the training time for the GAN by removing the discriminator component. Furthermore, our results show knowledge distillation can be employed to drastically reduce the size of the resulting model without impacting performance indicating that our contribution could run comfortably on a smartphone
High Quality Segmentation for Ultra High-resolution Images
Dec 26, 2021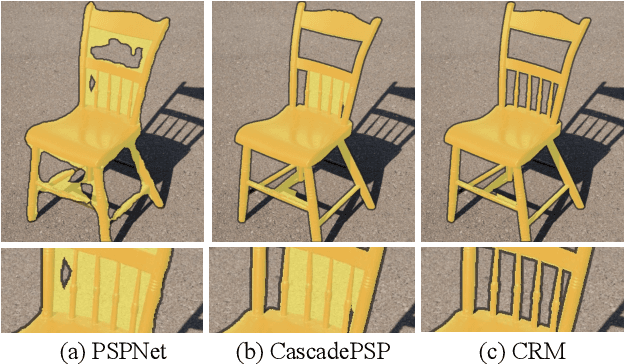
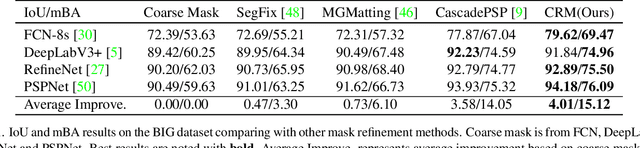
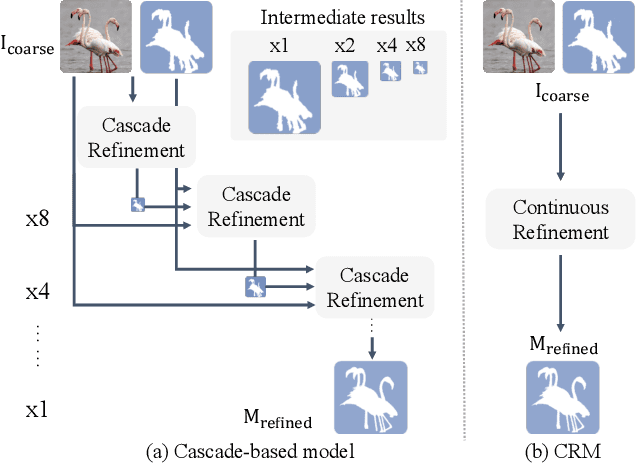
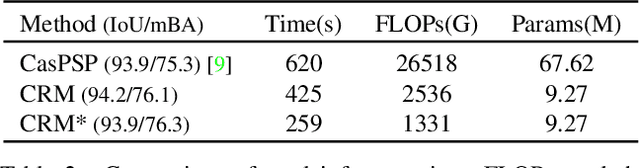
To segment 4K or 6K ultra high-resolution images needs extra computation consideration in image segmentation. Common strategies, such as down-sampling, patch cropping, and cascade model, cannot address well the balance issue between accuracy and computation cost. Motivated by the fact that humans distinguish among objects continuously from coarse to precise levels, we propose the Continuous Refinement Model~(CRM) for the ultra high-resolution segmentation refinement task. CRM continuously aligns the feature map with the refinement target and aggregates features to reconstruct these images' details. Besides, our CRM shows its significant generalization ability to fill the resolution gap between low-resolution training images and ultra high-resolution testing ones. We present quantitative performance evaluation and visualization to show that our proposed method is fast and effective on image segmentation refinement. Code will be released at https://github.com/dvlab-research/Entity.
CaCL: Class-aware Codebook Learning for Weakly Supervised Segmentation on Diffuse Image Patterns
Nov 02, 2020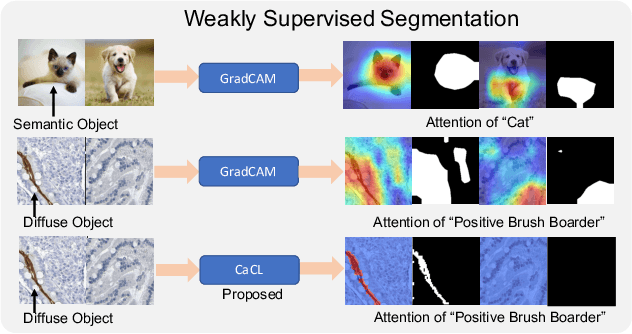
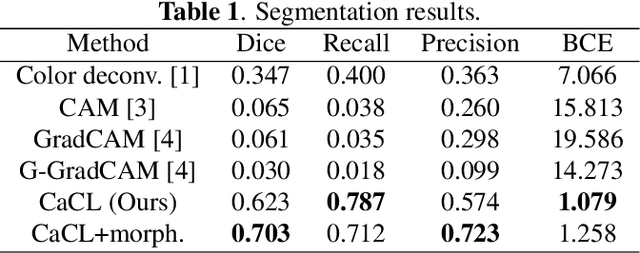
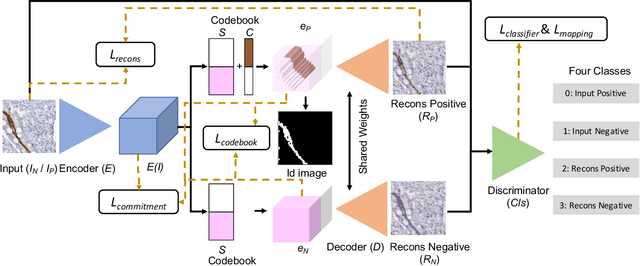
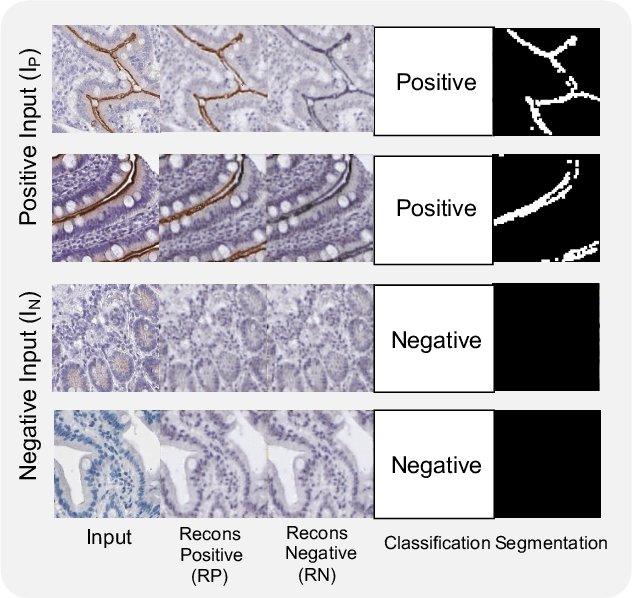
Weakly supervised learning has been rapidly advanced in biomedical image analysis to achieve pixel-wise labels (segmentation) from image-wise annotations (classification), as biomedical images naturally contain image-wise labels in many scenarios. The current weakly supervised learning algorithms from the computer vision community are largely designed for focal objects (e.g., dogs and cats). However, such algorithms are not optimized for diffuse patterns in biomedical imaging (e.g., stains and fluorescent in microscopy imaging). In this paper, we propose a novel class-aware codebook learning (CaCL) algorithm to perform weakly supervised learning for diffuse image patterns. Specifically, the CaCL algorithm is deployed to segment protein expressed brush border regions from histological images of human duodenum. This paper makes the following contributions: (1) we approach the weakly supervised segmentation from a novel codebook learning perspective; (2) the CaCL algorithm segments diffuse image patterns rather than focal objects; and (3) The proposed algorithm is implemented in a multi-task framework based on Vector Quantised-Variational AutoEncoder (VQ-VAE) to perform image reconstruction, classification, feature embedding, and segmentation. The experimental results show that our method achieved superior performance compared with baseline weakly supervised algorithms.
Learning Affordance Grounding from Exocentric Images
Mar 18, 2022
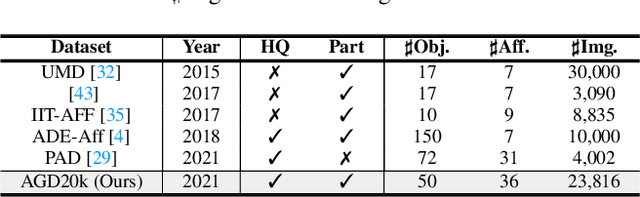
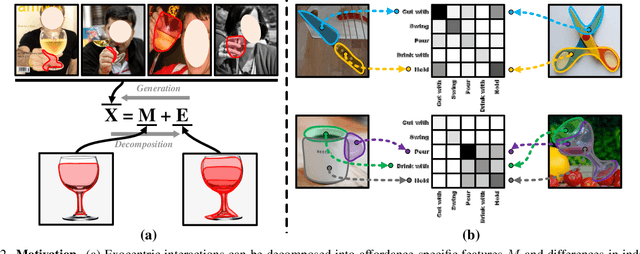
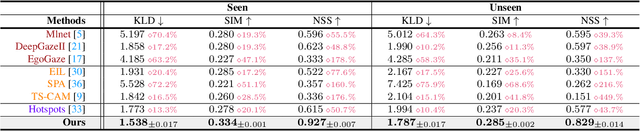
Affordance grounding, a task to ground (i.e., localize) action possibility region in objects, which faces the challenge of establishing an explicit link with object parts due to the diversity of interactive affordance. Human has the ability that transform the various exocentric interactions to invariant egocentric affordance so as to counter the impact of interactive diversity. To empower an agent with such ability, this paper proposes a task of affordance grounding from exocentric view, i.e., given exocentric human-object interaction and egocentric object images, learning the affordance knowledge of the object and transferring it to the egocentric image using only the affordance label as supervision. To this end, we devise a cross-view knowledge transfer framework that extracts affordance-specific features from exocentric interactions and enhances the perception of affordance regions by preserving affordance correlation. Specifically, an Affordance Invariance Mining module is devised to extract specific clues by minimizing the intra-class differences originated from interaction habits in exocentric images. Besides, an Affordance Co-relation Preserving strategy is presented to perceive and localize affordance by aligning the co-relation matrix of predicted results between the two views. Particularly, an affordance grounding dataset named AGD20K is constructed by collecting and labeling over 20K images from 36 affordance categories. Experimental results demonstrate that our method outperforms the representative models in terms of objective metrics and visual quality. Code: github.com/lhc1224/Cross-View-AG.
Spatial-Spectral Clustering with Anchor Graph for Hyperspectral Image
Apr 24, 2021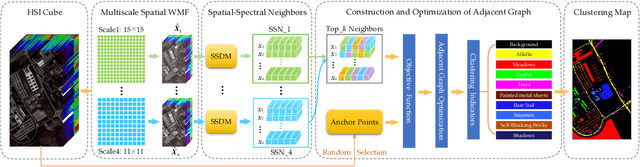
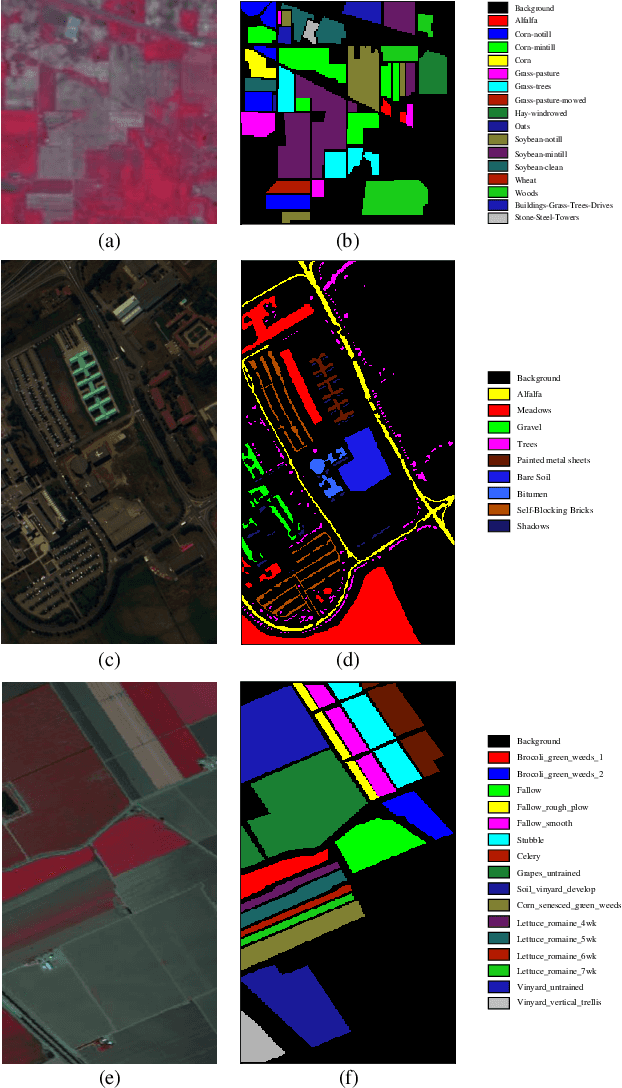
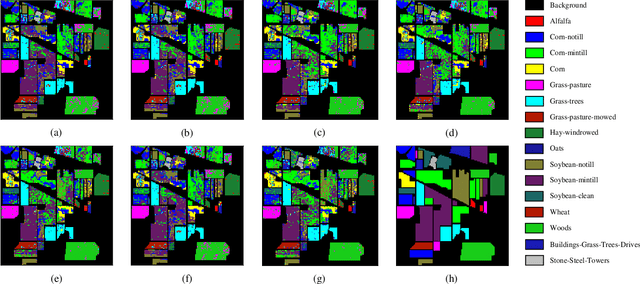
Hyperspectral image (HSI) clustering, which aims at dividing hyperspectral pixels into clusters, has drawn significant attention in practical applications. Recently, many graph-based clustering methods, which construct an adjacent graph to model the data relationship, have shown dominant performance. However, the high dimensionality of HSI data makes it hard to construct the pairwise adjacent graph. Besides, abundant spatial structures are often overlooked during the clustering procedure. In order to better handle the high dimensionality problem and preserve the spatial structures, this paper proposes a novel unsupervised approach called spatial-spectral clustering with anchor graph (SSCAG) for HSI data clustering. The SSCAG has the following contributions: 1) the anchor graph-based strategy is used to construct a tractable large graph for HSI data, which effectively exploits all data points and reduces the computational complexity; 2) a new similarity metric is presented to embed the spatial-spectral information into the combined adjacent graph, which can mine the intrinsic property structure of HSI data; 3) an effective neighbors assignment strategy is adopted in the optimization, which performs the singular value decomposition (SVD) on the adjacent graph to get solutions efficiently. Extensive experiments on three public HSI datasets show that the proposed SSCAG is competitive against the state-of-the-art approaches.
Weakly-Supervised Salient Object Detection Using Point Supervison
Mar 22, 2022
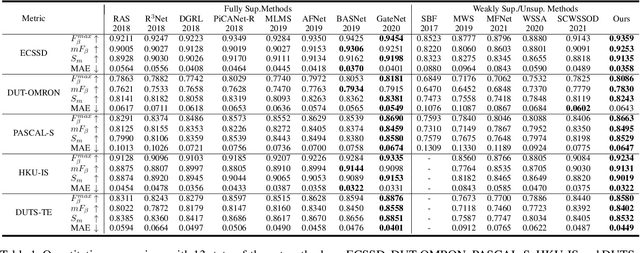
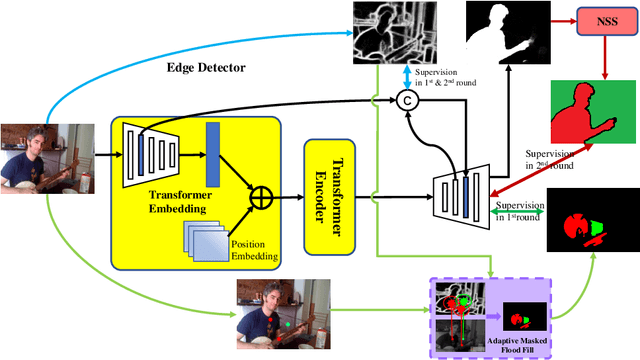
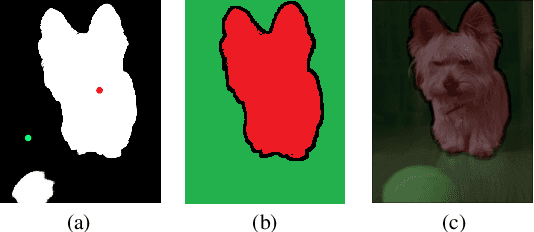
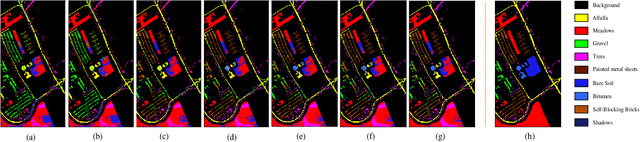
Current state-of-the-art saliency detection models rely heavily on large datasets of accurate pixel-wise annotations, but manually labeling pixels is time-consuming and labor-intensive. There are some weakly supervised methods developed for alleviating the problem, such as image label, bounding box label, and scribble label, while point label still has not been explored in this field. In this paper, we propose a novel weakly-supervised salient object detection method using point supervision. To infer the saliency map, we first design an adaptive masked flood filling algorithm to generate pseudo labels. Then we develop a transformer-based point-supervised saliency detection model to produce the first round of saliency maps. However, due to the sparseness of the label, the weakly supervised model tends to degenerate into a general foreground detection model. To address this issue, we propose a Non-Salient Suppression (NSS) method to optimize the erroneous saliency maps generated in the first round and leverage them for the second round of training. Moreover, we build a new point-supervised dataset (P-DUTS) by relabeling the DUTS dataset. In P-DUTS, there is only one labeled point for each salient object. Comprehensive experiments on five largest benchmark datasets demonstrate our method outperforms the previous state-of-the-art methods trained with the stronger supervision and even surpass several fully supervised state-of-the-art models. The code is available at: https://github.com/shuyonggao/PSOD.