 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer Questions with Right Image Regions: A Visual Attention Regularization Approach
Paper and Code
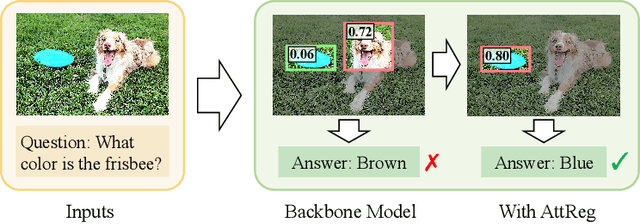
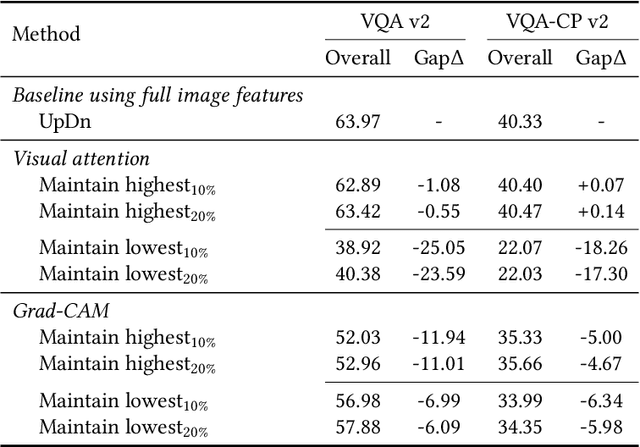
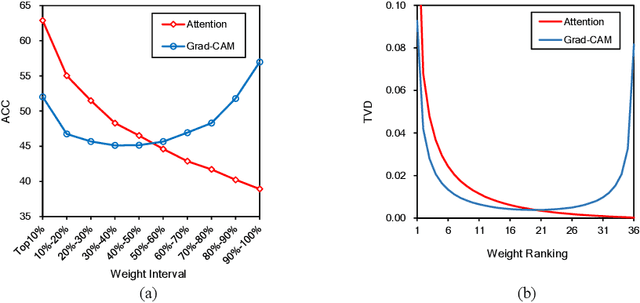
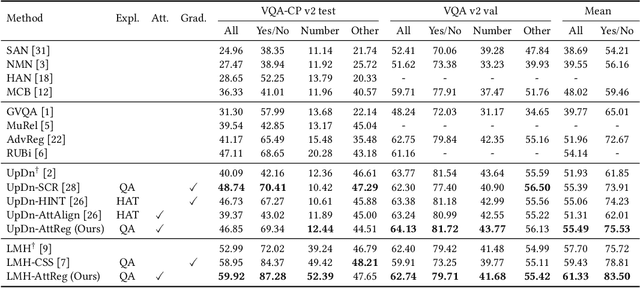
Visual attention in Visual Question Answering (VQA) targets at locating the right image regions regarding the answer prediction. However, recent studies have pointed out that the highlighted image regions from the visual attention are often irrelevant to the given question and answer, leading to model confusion for correct visual reasoning. To tackle this problem, existing methods mostly resort to aligning the visual attention weights with human attentions. Nevertheless, gathering such human data is laborious and expensive, making it burdensome to adapt well-developed models across datasets. To address this issue, in this paper, we devise a novel visual attention regularization approach, namely AttReg, for better visual grounding in VQA. Specifically, AttReg firstly identifies the image regions which are essential for question answering yet unexpectedly ignored (i.e., assigned with low attention weights) by the backbone model. And then a mask-guided learning scheme is leveraged to regularize the visual attention to focus more on these ignored key regions. The proposed method is very flexible and model-agnostic, which can be integrated into most visual attention-based VQA models and require no human attention supervision. Extensive experiments over three benchmark datasets, i.e., VQA-CP v2, VQA-CP v1, and VQA v2, have been conducted to evaluate the effectiveness of AttReg. As a by-product, when incorporating AttReg into the strong baseline LMH, our approach can achieve a new state-of-the-art accuracy of 59.92% with an absolute performance gain of 6.93% on the VQA-CP v2 benchmark dataset. In addition to the effectiveness validation, we recognize that the faithfulness of the visual attention in VQA has not been well explored in literature. In the light of this, we propose to empirically validate such property of visual attention and compare it with the prevalent gradient-based approaches.