 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
May 29, 2022

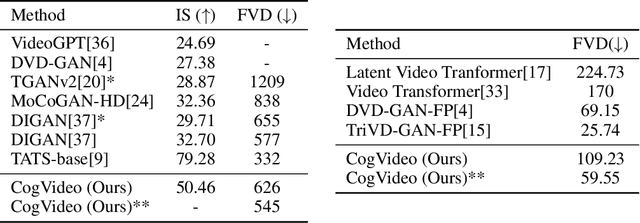
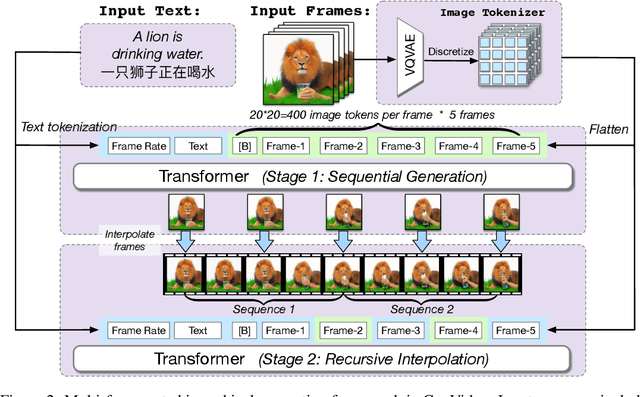

Large-scale pretrained transformers have created milestones in text (GPT-3) and text-to-image (DALL-E and CogView) generation. Its application to video generation is still facing many challenges: The potential huge computation cost makes the training from scratch unaffordable; The scarcity and weak relevance of text-video datasets hinder the model understanding complex movement semantics. In this work, we present 9B-parameter transformer CogVideo, trained by inheriting a pretrained text-to-image model, CogView2. We also propose multi-frame-rate hierarchical training strategy to better align text and video clips. As (probably) the first open-source large-scale pretrained text-to-video model, CogVideo outperforms all publicly available models at a large margin in machine and human evaluations.
Inverse Problem of Ultrasound Beamforming with Denoising-Based Regularized Solutions
Jun 16, 2022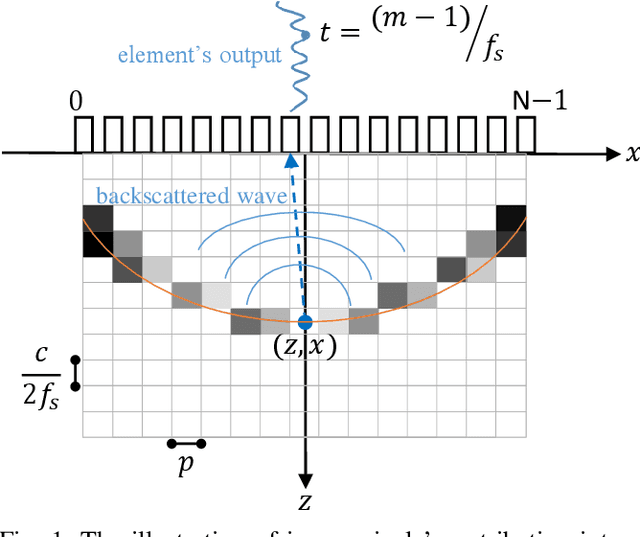
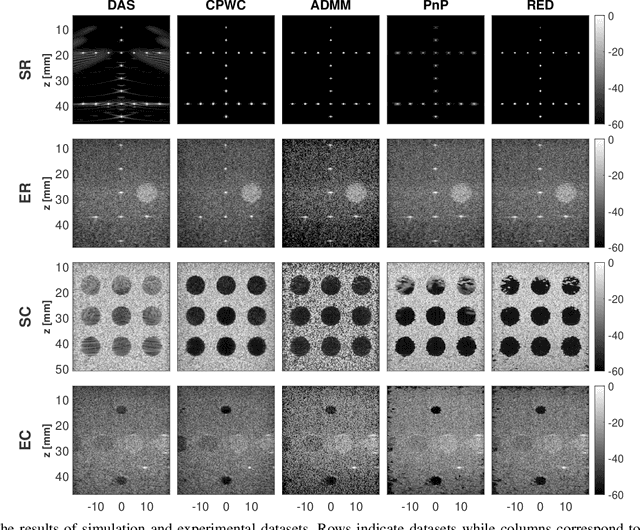
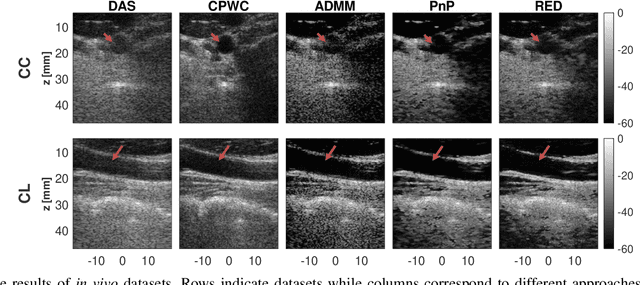
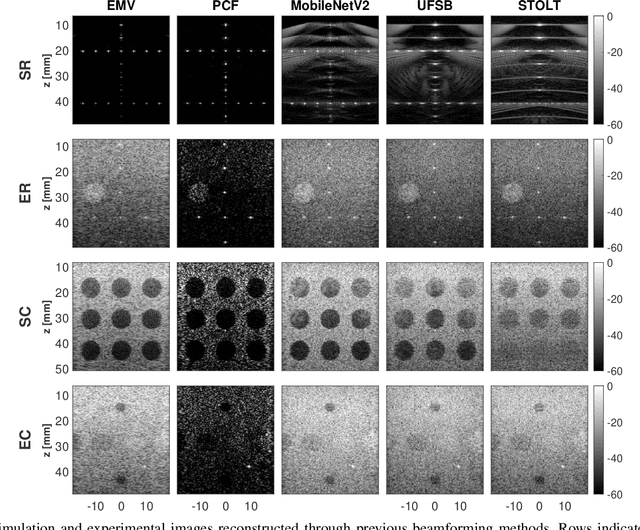
During the past few years, inverse problem formulations of ultrasound beamforming have attracted a growing interest. They usually pose beamforming as a minimization problem of a fidelity term resulting from the measurement model plus a regularization term that enforces a certain class on the resulting image. Herein, we take advantages of alternating direction method of multipliers to propose a flexible framework in which each term is optimized separately. Furthermore, the proposed beamforming formulation is extended to replace the regularization term by a denoising algorithm, based on the recent approaches called plug-and-play (PnP) and regularization by denoising (RED). Such regularizations are shown in this work to better preserve speckle texture, an important feature in ultrasound imaging, than sparsity-based approaches previously proposed in the literature. The efficiency of proposed methods is evaluated on simulations, real phantoms, and \textit{in vivo} data available from a plane-wave imaging challenge in medical ultrasound. Furthermore, a comprehensive comparison with existing ultrasound beamforming methods is also provided. These results show that the RED algorithm gives the best image quality in terms of contrast index while preserving the speckle statistics.
One Model is All You Need: Multi-Task Learning Enables Simultaneous Histology Image Segmentation and Classification
Feb 28, 2022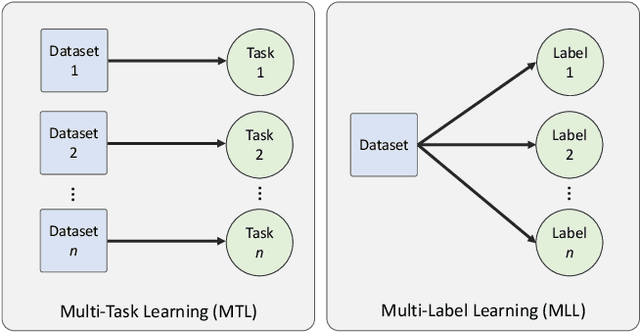
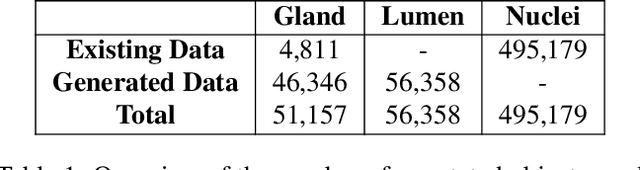
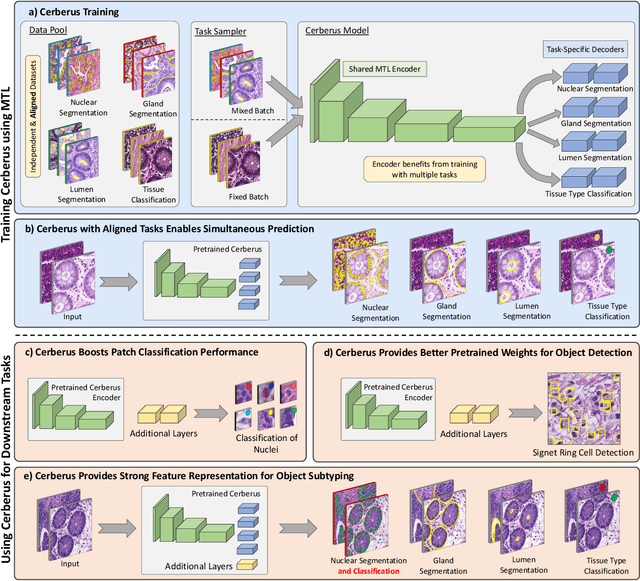

The recent surge in performance for image analysis of digitised pathology slides can largely be attributed to the advance of deep learning. Deep models can be used to initially localise various structures in the tissue and hence facilitate the extraction of interpretable features for biomarker discovery. However, these models are typically trained for a single task and therefore scale poorly as we wish to adapt the model for an increasing number of different tasks. Also, supervised deep learning models are very data hungry and therefore rely on large amounts of training data to perform well. In this paper we present a multi-task learning approach for segmentation and classification of nuclei, glands, lumen and different tissue regions that leverages data from multiple independent data sources. While ensuring that our tasks are aligned by the same tissue type and resolution, we enable simultaneous prediction with a single network. As a result of feature sharing, we also show that the learned representation can be used to improve downstream tasks, including nuclear classification and signet ring cell detection. As part of this work, we use a large dataset consisting of over 600K objects for segmentation and 440K patches for classification and make the data publicly available. We use our approach to process the colorectal subset of TCGA, consisting of 599 whole-slide images, to localise 377 million, 900K and 2.1 million nuclei, glands and lumen respectively. We make this resource available to remove a major barrier in the development of explainable models for computational pathology.
Diverse super-resolution with pretrained deep hiererarchical VAEs
May 20, 2022


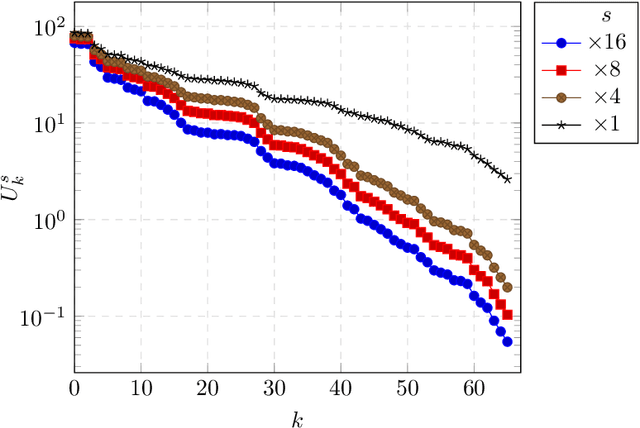
Image super-resolution is a one-to-many problem, but most deep-learning based methods only provide one single solution to this problem. In this work, we tackle the problem of diverse super-resolution by reusing VD-VAE, a state-of-the art variational autoencoder (VAE). We find that the hierarchical latent representation learned by VD-VAE naturally separates the image low-frequency information, encoded in the latent groups at the top of the hierarchy, from the image high-frequency details, determined by the latent groups at the bottom of the latent hierarchy. Starting from this observation, we design a super-resolution model exploiting the specific structure of VD-VAE latent space. Specifically, we train an encoder to encode low-resolution images in the subset of VD-VAE latent space encoding the low-frequency information, and we combine this encoder with VD-VAE generative model to sample diverse super-resolved version of a low-resolution input. We demonstrate the ability of our method to generate diverse solutions to the super-resolution problem on face super-resolution with upsampling factors x4, x8, and x16.
Disentangled Feature Representation for Few-shot Image Classification
Sep 26, 2021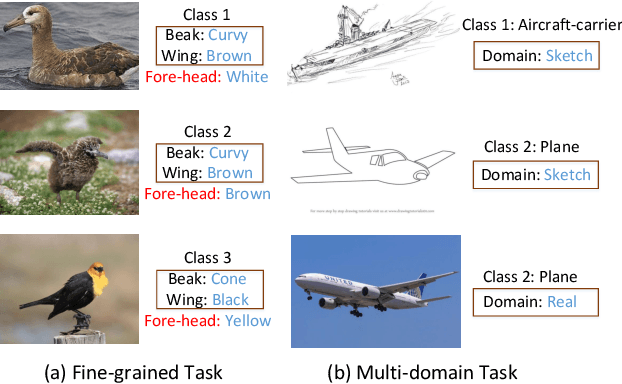
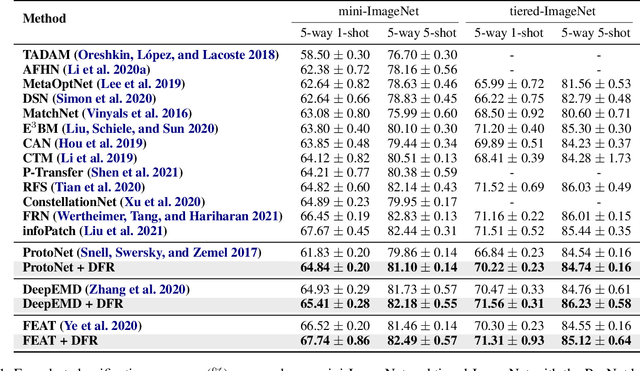
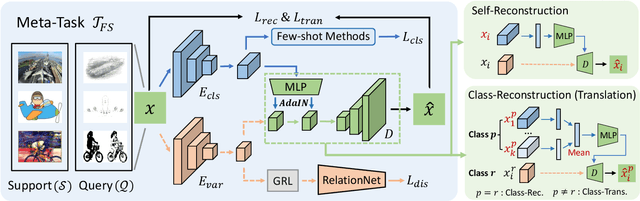
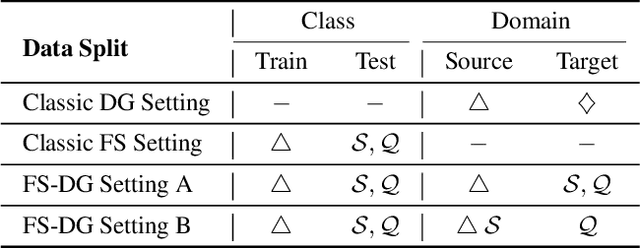
Learning the generalizable feature representation is critical for few-shot image classification. While recent works exploited task-specific feature embedding using meta-tasks for few-shot learning, they are limited in many challenging tasks as being distracted by the excursive features such as the background, domain and style of the image samples. In this work, we propose a novel Disentangled Feature Representation framework, dubbed DFR, for few-shot learning applications. DFR can adaptively decouple the discriminative features that are modeled by the classification branch, from the class-irrelevant component of the variation branch. In general, most of the popular deep few-shot learning methods can be plugged in as the classification branch, thus DFR can boost their performance on various few-shot tasks. Furthermore, we propose a novel FS-DomainNet dataset based on DomainNet, for benchmarking the few-shot domain generalization tasks. We conducted extensive experiments to evaluate the proposed DFR on general and fine-grained few-shot classification, as well as few-shot domain generalization, using the corresponding four benchmarks, i.e., mini-ImageNet, tiered-ImageNet, CUB, as well as the proposed FS-DomainNet. Thanks to the effective feature disentangling, the DFR-based few-shot classifiers achieved the state-of-the-art results on all datasets.
Efficient Medical Image Segmentation Based on Knowledge Distillation
Aug 23, 2021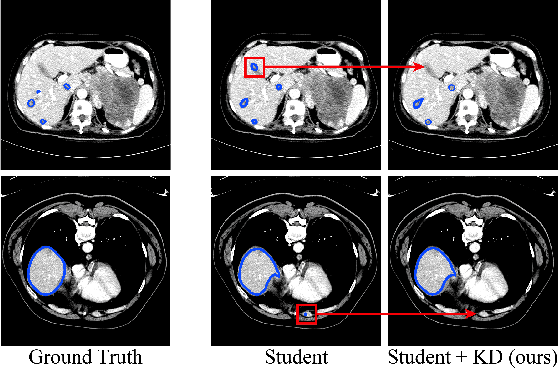
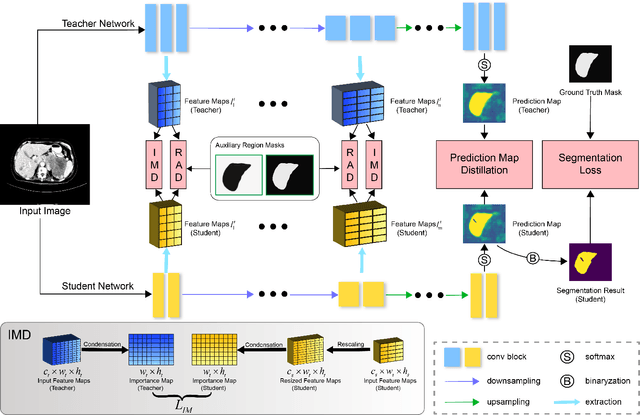
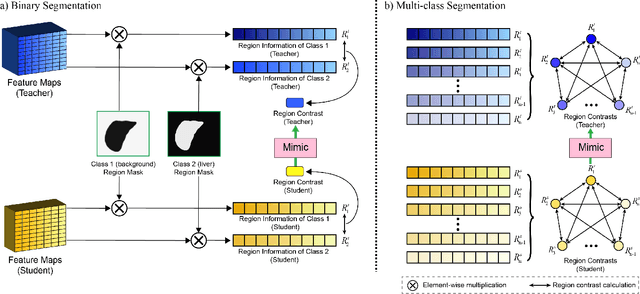
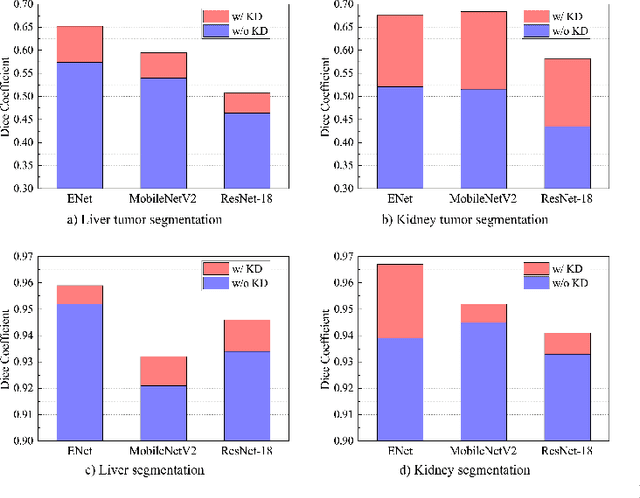
Recent advances have been made in applying convolutional neural networks to achieve more precise prediction results for medical image segmentation problems. However, the success of existing methods has highly relied on huge computational complexity and massive storage, which is impractical in the real-world scenario. To deal with this problem, we propose an efficient architecture by distilling knowledge from well-trained medical image segmentation networks to train another lightweight network. This architecture empowers the lightweight network to get a significant improvement on segmentation capability while retaining its runtime efficiency. We further devise a novel distillation module tailored for medical image segmentation to transfer semantic region information from teacher to student network. It forces the student network to mimic the extent of difference of representations calculated from different tissue regions. This module avoids the ambiguous boundary problem encountered when dealing with medical imaging but instead encodes the internal information of each semantic region for transferring. Benefited from our module, the lightweight network could receive an improvement of up to 32.6% in our experiment while maintaining its portability in the inference phase. The entire structure has been verified on two widely accepted public CT datasets LiTS17 and KiTS19. We demonstrate that a lightweight network distilled by our method has non-negligible value in the scenario which requires relatively high operating speed and low storage usage.
Matching in the Dark: A Dataset for Matching Image Pairs of Low-light Scenes
Sep 08, 2021
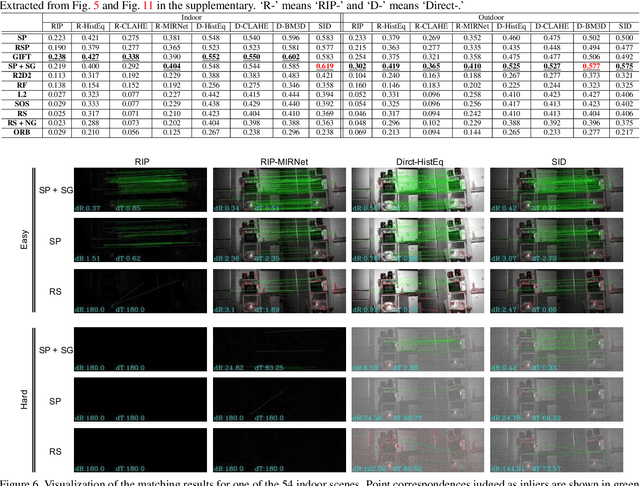
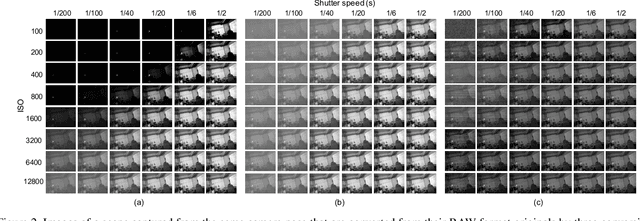
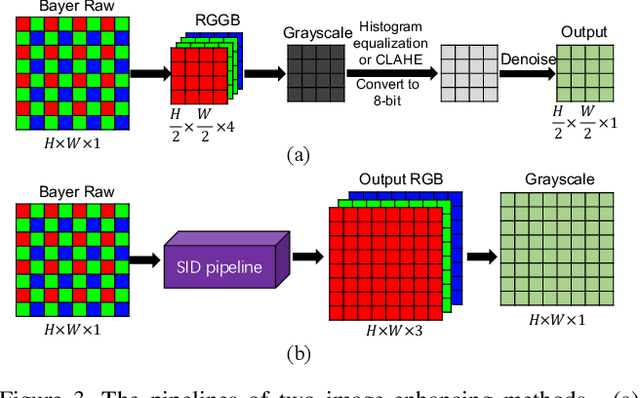
This paper considers matching images of low-light scenes, aiming to widen the frontier of SfM and visual SLAM applications. Recent image sensors can record the brightness of scenes with more than eight-bit precision, available in their RAW-format image. We are interested in making full use of such high-precision information to match extremely low-light scene images that conventional methods cannot handle. For extreme low-light scenes, even if some of their brightness information exists in the RAW format images' low bits, the standard raw image processing on cameras fails to utilize them properly. As was recently shown by Chen et al., CNNs can learn to produce images with a natural appearance from such RAW-format images. To consider if and how well we can utilize such information stored in RAW-format images for image matching, we have created a new dataset named MID (matching in the dark). Using it, we experimentally evaluated combinations of eight image-enhancing methods and eleven image matching methods consisting of classical/neural local descriptors and classical/neural initial point-matching methods. The results show the advantage of using the RAW-format images and the strengths and weaknesses of the above component methods. They also imply there is room for further research.
Enhancing MR Image Segmentation with Realistic Adversarial Data Augmentation
Aug 07, 2021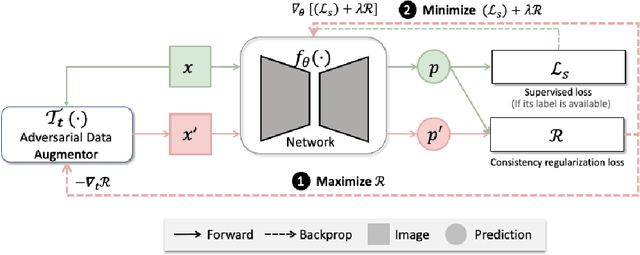

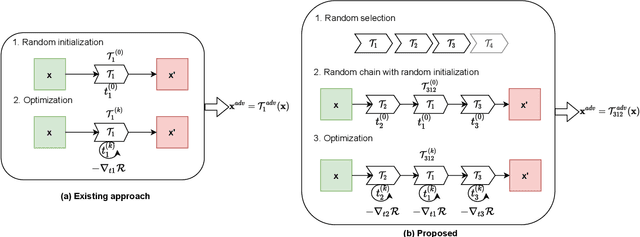
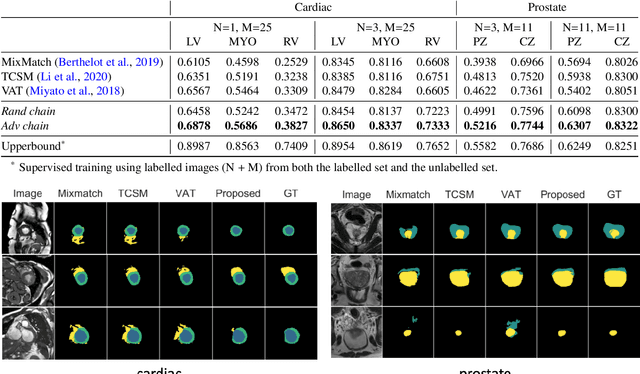
The success of neural networks on medical image segmentation tasks typically relies on large labeled datasets for model training. However, acquiring and manually labeling a large medical image set is resource-intensive, expensive, and sometimes impractical due to data sharing and privacy issues. To address this challenge, we propose an adversarial data augmentation approach to improve the efficiency in utilizing training data and to enlarge the dataset via simulated but realistic transformations. Specifically, we present a generic task-driven learning framework, which jointly optimizes a data augmentation model and a segmentation network during training, generating informative examples to enhance network generalizability for the downstream task. The data augmentation model utilizes a set of photometric and geometric image transformations and chains them to simulate realistic complex imaging variations that could exist in magnetic resonance (MR) imaging. The proposed adversarial data augmentation does not rely on generative networks and can be used as a plug-in module in general segmentation networks. It is computationally efficient and applicable for both supervised and semi-supervised learning. We analyze and evaluate the method on two MR image segmentation tasks: cardiac segmentation and prostate segmentation. Results show that the proposed approach can alleviate the need for labeled data while improving model generalization ability, indicating its practical value in medical imaging applications.
Generate and Edit Your Own Character in a Canonical View
May 06, 2022

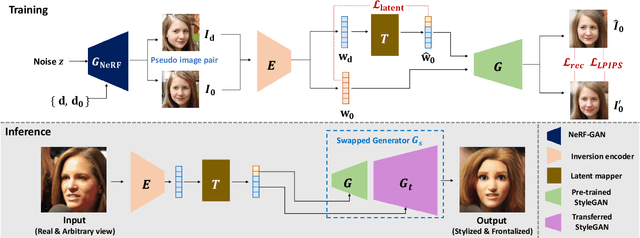

Recently, synthesizing personalized characters from a single user-given portrait has received remarkable attention as a drastic popularization of social media and the metaverse. The input image is not always in frontal view, thus it is important to acquire or predict canonical view for 3D modeling or other applications. Although the progress of generative models enables the stylization of a portrait, obtaining the stylized image in canonical view is still a challenging task. There have been several studies on face frontalization but their performance significantly decreases when input is not in the real image domain, e.g., cartoon or painting. Stylizing after frontalization also results in degenerated output. In this paper, we propose a novel and unified framework which generates stylized portraits in canonical view. With a proposed latent mapper, we analyze and discover frontalization mapping in a latent space of StyleGAN to stylize and frontalize at once. In addition, our model can be trained with unlabelled 2D image sets, without any 3D supervision. The effectiveness of our method is demonstrated by experimental results.
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022
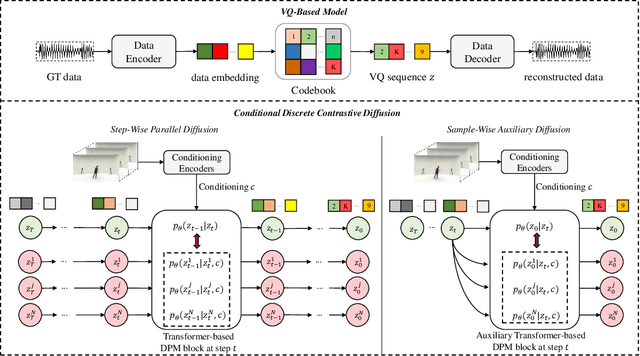

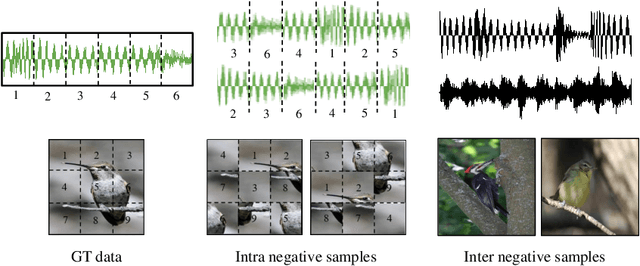
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.