 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDroneDAR: Long-Range Drone Distance Estimation Using Monocular Vision and Bounding-Box Features
Jun 05, 2026Accurate distance estimation for small drones in long-range imagery is important for tracking and situational awareness, yet remains challenging due to extreme target scale variation, background clutter, and noisy visual cues. This paper studies monocular drone distance estimation using image crops together with bounding-box geometry, a practical setting in which a detector provides a candidate drone region and the model predicts range from appearance and box-derived features. We evaluate a Droneranger-style baseline, and introduce a new DroneDAR (Drone Detection And Ranging) model that combines a convolutional backbone with explicit bounding-box cues through a lightweight gating mechanism. Experiments analyze how backbone capacity, crop resolution, and regression loss functions affect performance across distance regimes. We further examine common failure modes at long distances, including sensitivity to bounding-box noise and reduced texture detail in the crop. The results provide guidance for designing and training range estimators that remain robust under real-world long-range conditions and highlight directions for improving reliability when drones occupy only a few pixels.
LRDDv3: High-Resolution Long-Range Drone Detection Dataset with Range Information and Thermal Data
May 25, 2026Unmanned Aerial Vehicles (UAVs) have quickly become common in various airspaces, representing a wide range of applications from recreation flying to commercial photography and package delivery. With the increasing prevalence of UAVs, it becomes critical that both manned and unmanned aircraft can detect UAVs and other flying objects from long range to effectively track movement and ensure safe operation in shared spaces. While several datasets have been introduced for drone detection, the need for expanded high-quality data persists, especially in the area of high-resolution long-range drone data. To address this, we introduce a high-resolution dataset of 102,532 long-range RGB images of drones, sampled at 5 FPS from 128 distinct video clips taken mid flight during 17 different data collection days spread over 8 months to ensure a wide variety of lighting scenarios, flight locations, and background elements. The dataset boasts comprehensive drone range information across the dataset, as well as 29,630 IR images, all paired with RGB counterparts from the base dataset. As one of the first drone detection datasets to leverage 4K image resolution and paired 640x512 IR images, our work represents a significant advancement to enable the detection of drones at long range. For access to the complete dataset, please visit https://research.coe.drexel.edu/ece/imaple/lrddv3/
GA3T: A Ground-Aerial Terrain Traversability Dataset for Heterogeneous Robot Teams in Unstructured Environments
May 07, 2026Heterogeneous air-ground robot teams combine complementary sensing modalities, mobility characteristics, and spatial viewpoints that can significantly enhance perception in complex outdoor environments. However, progress in multi-robot collaborative perception has been constrained by the lack of real-world datasets featuring overlapping multi-modal observations from platforms operating in unstructured terrain. We present GA3T (Ground-Aerial Team for Terrain Traversal), a real-world multi-robot collaborative perception dataset collected using a Clearpath Husky UGV and an Autel EVO~II UAV across diverse unstructured environments, including forest trails, rocky paths, muddy terrain, snow piles, and grass-covered fields. The ground platform provides 3D LiDAR, stereo camera, IMU, and GPS data, while the aerial platform contributes RGB imagery, thermal/infrared observations, and GPS from a complementary overhead viewpoint, allowing for rich cross-modal and cross-view perception. The dataset is collected in 4 unique environments, with over 13,000 synchronized frames across approximately 29 minutes of operation, and includes both SAM~3-based zero-shot segmentation and over 8,000 manually labeled images. A unique aspect of the dataset is its early-spring collection period, during which sparse tree canopies allow the aerial robot to partially observe the ground robot and terrain through the trees, allowing for occlusion-aware collaborative perception. Unlike prior multi-robot datasets that focus on SLAM or simulated cooperative driving, GA3T is specifically designed to support research on cross-view perception, air-ground viewpoint fusion, traversability estimation, and collaborative scene understanding in real off-road environments.
Predicting Dynamic Map States from Limited Field-of-View Sensor Data
Feb 12, 2026When autonomous systems are deployed in real-world scenarios, sensors are often subject to limited field-of-view (FOV) constraints, either naturally through system design, or through unexpected occlusions or sensor failures. In conditions where a large FOV is unavailable, it is important to be able to infer information about the environment and predict the state of nearby surroundings based on available data to maintain safe and accurate operation. In this work, we explore the effectiveness of deep learning for dynamic map state prediction based on limited FOV time series data. We show that by representing dynamic sensor data in a simple single-image format that captures both spatial and temporal information, we can effectively use a wide variety of existing image-to-image learning models to predict map states with high accuracy in a diverse set of sensing scenarios.
Resnet-conformer network with shared weights and attention mechanism for sound event localization, detection, and distance estimation
Jul 23, 2025This technical report outlines our approach to Task 3A of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2024, focusing on Sound Event Localization and Detection (SELD). SELD provides valuable insights by estimating sound event localization and detection, aiding in various machine cognition tasks such as environmental inference, navigation, and other sound localization-related applications. This year's challenge evaluates models using either audio-only (Track A) or audiovisual (Track B) inputs on annotated recordings of real sound scenes. A notable change this year is the introduction of distance estimation, with evaluation metrics adjusted accordingly for a comprehensive assessment. Our submission is for Task A of the Challenge, which focuses on the audio-only track. Our approach utilizes log-mel spectrograms, intensity vectors, and employs multiple data augmentations. We proposed an EINV2-based [1] network architecture, achieving improved results: an F-score of 40.2%, Angular Error (DOA) of 17.7 degrees, and Relative Distance Error (RDE) of 0.32 on the test set of the Development Dataset [2 ,3].
Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
May 02, 2024A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
Learning Scene Context Without Images
Nov 18, 2023Teaching machines of scene contextual knowledge would enable them to interact more effectively with the environment and to anticipate or predict objects that may not be immediately apparent in their perceptual field. In this paper, we introduce a novel transformer-based approach called $LMOD$ ( Label-based Missing Object Detection) to teach scene contextual knowledge to machines using an attention mechanism. A distinctive aspect of the proposed approach is its reliance solely on labels from image datasets to teach scene context, entirely eliminating the need for the actual image itself. We show how scene-wide relationships among different objects can be learned using a self-attention mechanism. We further show that the contextual knowledge gained from label based learning can enhance performance of other visual based object detection algorithm.
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Jan 20, 2023Image inpainting is an old problem in computer vision that restores occluded regions and completes damaged images. In the case of facial image inpainting, most of the methods generate only one result for each masked image, even though there are other reasonable possibilities. To prevent any potential biases and unnatural constraints stemming from generating only one image, we propose a novel framework for diverse facial inpainting exploiting the embedding space of StyleGAN. Our framework employs pSp encoder and SeFa algorithm to identify semantic components of the StyleGAN embeddings and feed them into our proposed SPARN decoder that adopts region normalization for plausible inpainting. We demonstrate that our proposed method outperforms several state-of-the-art methods.
Reference Guided Image Inpainting using Facial Attributes
Jan 19, 2023



Image inpainting is a technique of completing missing pixels such as occluded region restoration, distracting objects removal, and facial completion. Among these inpainting tasks, facial completion algorithm performs face inpainting according to the user direction. Existing approaches require delicate and well controlled input by the user, thus it is difficult for an average user to provide the guidance sufficiently accurate for the algorithm to generate desired results. To overcome this limitation, we propose an alternative user-guided inpainting architecture that manipulates facial attributes using a single reference image as the guide. Our end-to-end model consists of attribute extractors for accurate reference image attribute transfer and an inpainting model to map the attributes realistically and accurately to generated images. We customize MS-SSIM loss and learnable bidirectional attention maps in which importance structures remain intact even with irregular shaped masks. Based on our evaluation using the publicly available dataset CelebA-HQ, we demonstrate that the proposed method delivers superior performance compared to some state-of-the-art methods specialized in inpainting tasks.
Controllable Face Manipulation and UV Map Generation by Self-supervised Learning
Sep 24, 2022

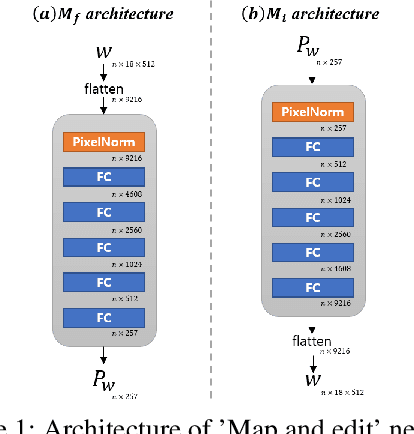
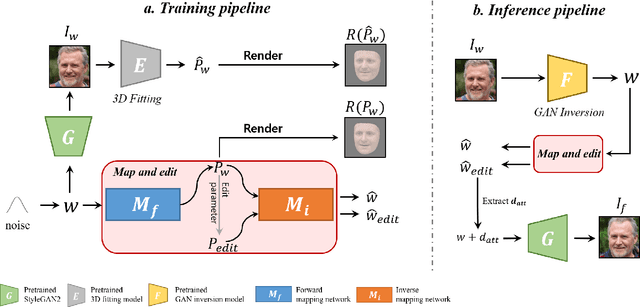
Although manipulating facial attributes by Generative Adversarial Networks (GANs) has been remarkably successful recently, there are still some challenges in explicit control of features such as pose, expression, lighting, etc. Recent methods achieve explicit control over 2D images by combining 2D generative model and 3DMM. However, due to the lack of realism and clarity in texture reconstruction by 3DMM, there is a domain gap between the synthetic image and the rendered image of 3DMM. Since rendered 3DMM images contain facial region only without the background, directly computing the loss between these two domains is not ideal and the resultant trained model will be biased. In this study, we propose to explicitly edit the latent space of the pretrained StyleGAN by controlling the parameters of the 3DMM. To address the domain gap problem, we propose a noval network called 'Map and edit' and a simple but effective attribute editing method to avoid direct loss computation between rendered and synthesized images. Furthermore, since our model can accurately generate multi-view face images while the identity remains unchanged. As a by-product, combined with visibility masks, our proposed model can also generate texture-rich and high-resolution UV facial textures. Our model relies on pretrained StyleGAN, and the proposed model is trained in a self-supervised manner without any manual annotations or datasets.