 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning for Human Parsing: A Survey
Jan 29, 2023

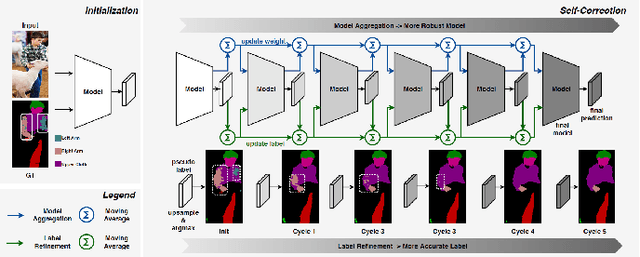
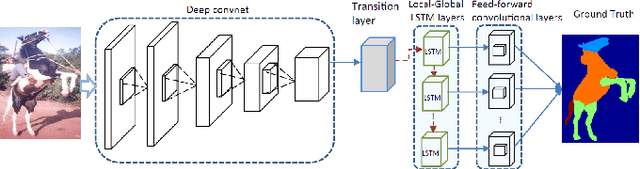
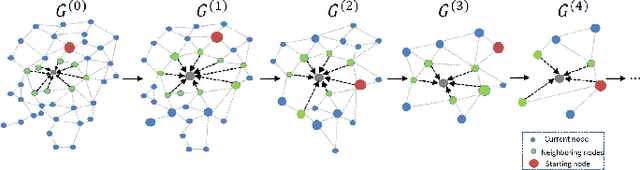
Human parsing is a key topic in image processing with many applications, such as surveillance analysis, human-robot interaction, person search, and clothing category classification, among many others. Recently, due to the success of deep learning in computer vision, there are a number of works aimed at developing human parsing algorithms using deep learning models. As methods have been proposed, a comprehensive survey of this topic is of great importance. In this survey, we provide an analysis of state-of-the-art human parsing methods, covering a broad spectrum of pioneering works for semantic human parsing. We introduce five insightful categories: (1) structure-driven architectures exploit the relationship of different human parts and the inherent hierarchical structure of a human body, (2) graph-based networks capture the global information to achieve an efficient and complete human body analysis, (3) context-aware networks explore useful contexts across all pixel to characterize a pixel of the corresponding class, (4) LSTM-based methods can combine short-distance and long-distance spatial dependencies to better exploit abundant local and global contexts, and (5) combined auxiliary information approaches use related tasks or supervision to improve network performance. We also discuss the advantages/disadvantages of the methods in each category and the relationships between methods in different categories, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
Learning to Unlearn: Instance-wise Unlearning for Pre-trained Classifiers
Jan 27, 2023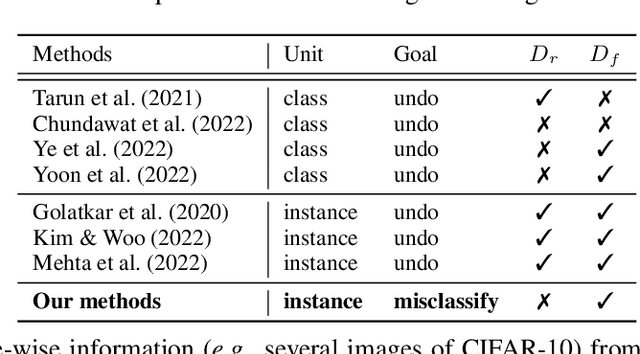
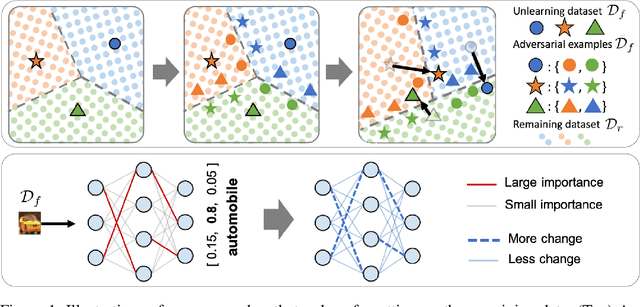
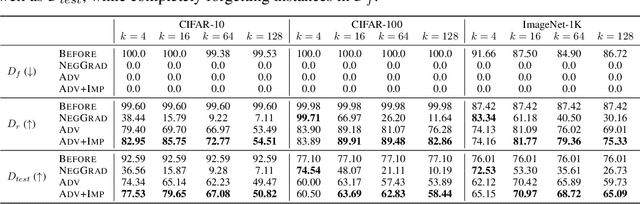
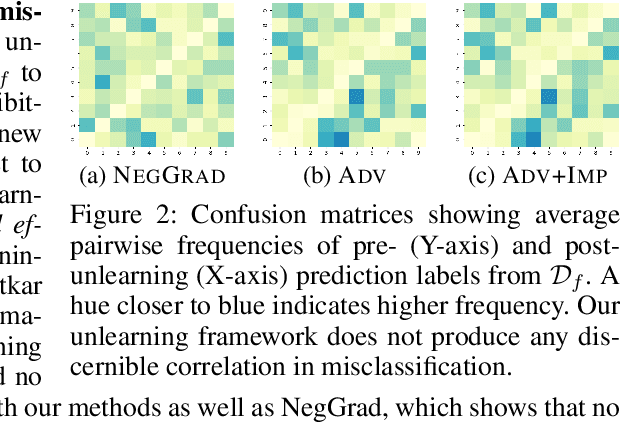
Since the recent advent of regulations for data protection (e.g., the General Data Protection Regulation), there has been increasing demand in deleting information learned from sensitive data in pre-trained models without retraining from scratch. The inherent vulnerability of neural networks towards adversarial attacks and unfairness also calls for a robust method to remove or correct information in an instance-wise fashion, while retaining the predictive performance across remaining data. To this end, we define instance-wise unlearning, of which the goal is to delete information on a set of instances from a pre-trained model, by either misclassifying each instance away from its original prediction or relabeling the instance to a different label. We also propose two methods that reduce forgetting on the remaining data: 1) utilizing adversarial examples to overcome forgetting at the representation-level and 2) leveraging weight importance metrics to pinpoint network parameters guilty of propagating unwanted information. Both methods only require the pre-trained model and data instances to forget, allowing painless application to real-life settings where the entire training set is unavailable. Through extensive experimentation on various image classification benchmarks, we show that our approach effectively preserves knowledge of remaining data while unlearning given instances in both single-task and continual unlearning scenarios.
Localizing Semantic Patches for Accelerating Image Classification
Jun 07, 2022
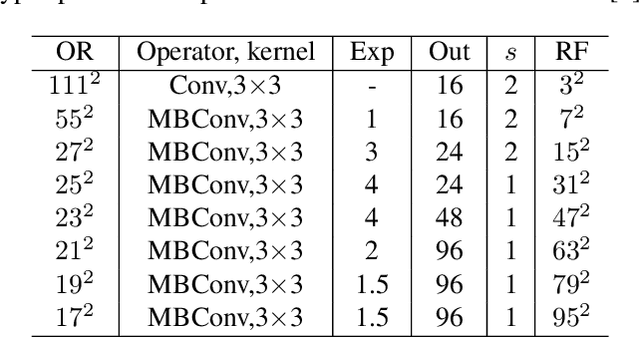
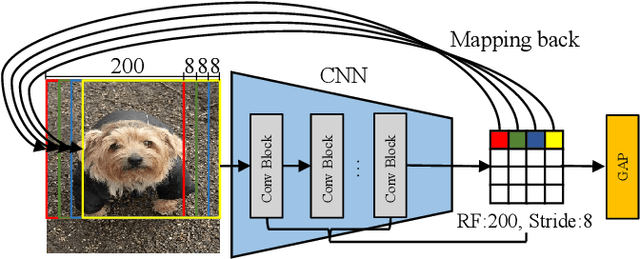
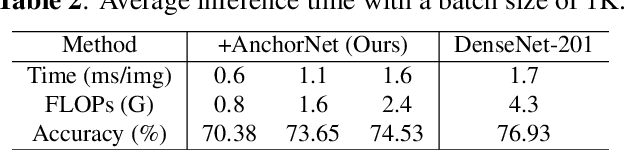
Existing works often focus on reducing the architecture redundancy for accelerating image classification but ignore the spatial redundancy of the input image. This paper proposes an efficient image classification pipeline to solve this problem. We first pinpoint task-aware regions over the input image by a lightweight patch proposal network called AnchorNet. We then feed these localized semantic patches with much smaller spatial redundancy into a general classification network. Unlike the popular design of deep CNN, we aim to carefully design the Receptive Field of AnchorNet without intermediate convolutional paddings. This ensures the exact mapping from a high-level spatial location to the specific input image patch. The contribution of each patch is interpretable. Moreover, AnchorNet is compatible with any downstream architecture. Experimental results on ImageNet show that our method outperforms SOTA dynamic inference methods with fewer inference costs. Our code is available at https://github.com/winycg/AnchorNet.
Deep Learning (DL)-based Automatic Segmentation of the Internal Pudendal Artery (IPA) for Reduction of Erectile Dysfunction in Definitive Radiotherapy of Localized Prostate Cancer
Feb 03, 2023Background and purpose: Radiation-induced erectile dysfunction (RiED) is commonly seen in prostate cancer patients. Clinical trials have been developed in multiple institutions to investigate whether dose-sparing to the internal-pudendal-arteries (IPA) will improve retention of sexual potency. The IPA is usually not considered a conventional organ-at-risk (OAR) due to segmentation difficulty. In this work, we propose a deep learning (DL)-based auto-segmentation model for the IPA that utilizes CT and MRI or CT alone as the input image modality to accommodate variation in clinical practice. Materials and methods: 86 patients with CT and MRI images and noisy IPA labels were recruited in this study. We split the data into 42/14/30 for model training, testing, and a clinical observer study, respectively. There were three major innovations in this model: 1) we designed an architecture with squeeze-and-excite blocks and modality attention for effective feature extraction and production of accurate segmentation, 2) a novel loss function was used for training the model effectively with noisy labels, and 3) modality dropout strategy was used for making the model capable of segmentation in the absence of MRI. Results: The DSC, ASD, and HD95 values for the test dataset were 62.2%, 2.54mm, and 7mm, respectively. AI segmented contours were dosimetrically equivalent to the expert physician's contours. The observer study showed that expert physicians' scored AI contours (mean=3.7) higher than inexperienced physicians' contours (mean=3.1). When inexperienced physicians started with AI contours, the score improved to 3.7. Conclusion: The proposed model achieved good quality IPA contours to improve uniformity of segmentation and to facilitate introduction of standardized IPA segmentation into clinical trials and practice.
Evaluating the Possibility of Integrating Augmented Reality and Internet of Things Technologies to Help Patients with Alzheimer's Disease
Jan 20, 2023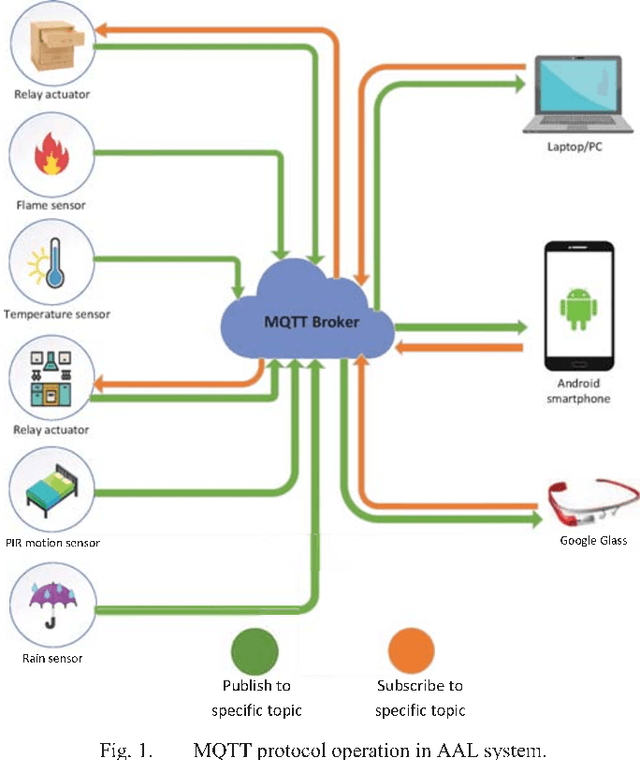
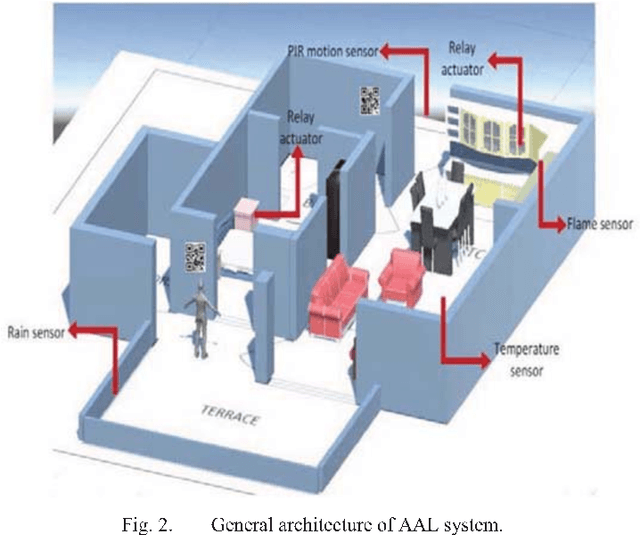
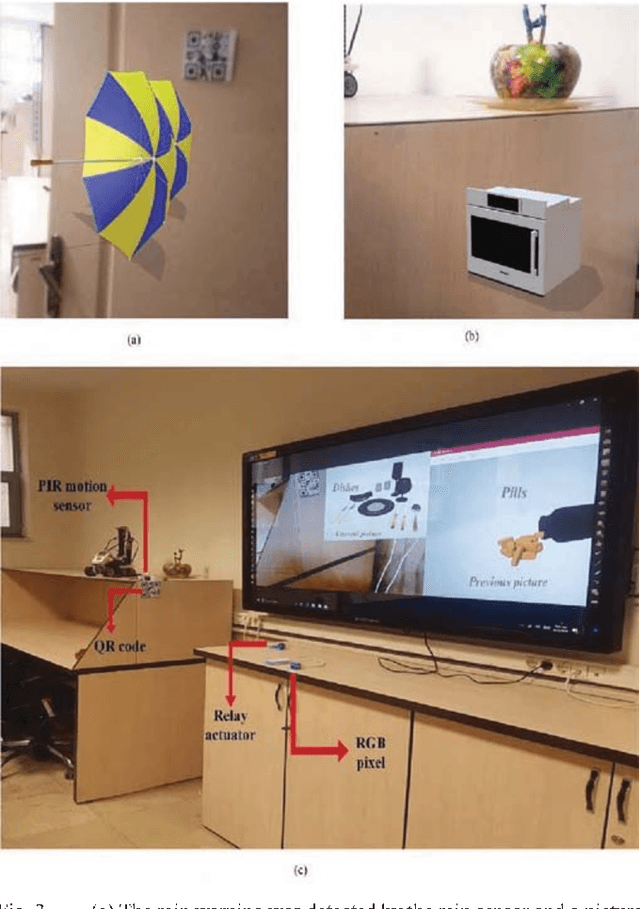
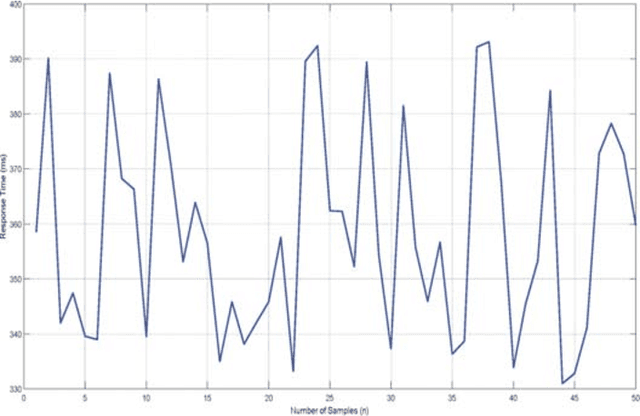
People suffering from Alzheimer's disease (AD) and their caregivers seek different approaches to cope with memory loss. Although AD patients want to live independently, they often need help from caregivers. In this situation, caregivers may attach notes on every single object or take out the contents of a drawer to make them visible before leaving the patient alone at home. This study reports preliminary results on an Ambient Assisted Living (AAL) real-time system, achieved through the Internet of Things (IoT) and Augmented Reality (AR) concepts, aimed at helping people suffering from AD. The system has two main sections: the smartphone or windows application allows caregivers to monitor patients' status at home and be notified if patients are at risk. The second part allows patients to use smart glasses to recognize QR codes in the environment and receive information related to tags in the form of audio, text, or three-dimensional image. This work presents preliminary results and investigates the possibility of implementing such a system.
Video Object of Interest Segmentation
Dec 06, 2022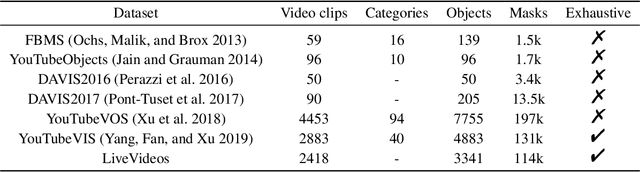



In this work, we present a new computer vision task named video object of interest segmentation (VOIS). Given a video and a target image of interest, our objective is to simultaneously segment and track all objects in the video that are relevant to the target image. This problem combines the traditional video object segmentation task with an additional image indicating the content that users are concerned with. Since no existing dataset is perfectly suitable for this new task, we specifically construct a large-scale dataset called LiveVideos, which contains 2418 pairs of target images and live videos with instance-level annotations. In addition, we propose a transformer-based method for this task. We revisit Swin Transformer and design a dual-path structure to fuse video and image features. Then, a transformer decoder is employed to generate object proposals for segmentation and tracking from the fused features. Extensive experiments on LiveVideos dataset show the superiority of our proposed method.
Multiscale Metamorphic VAE for 3D Brain MRI Synthesis
Jan 11, 2023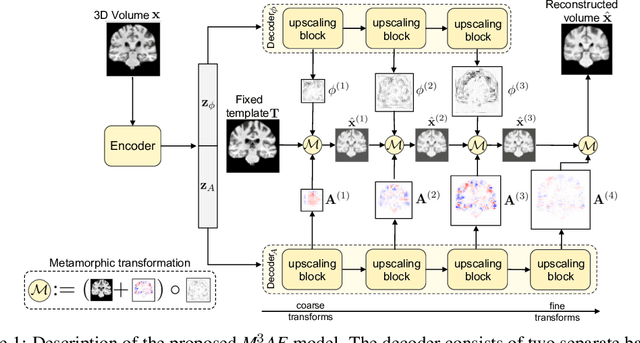
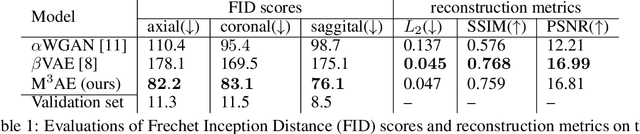
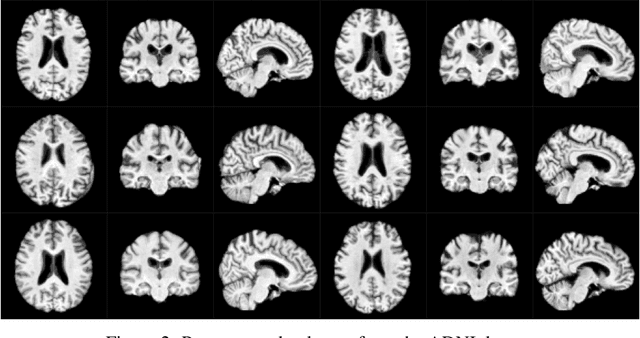
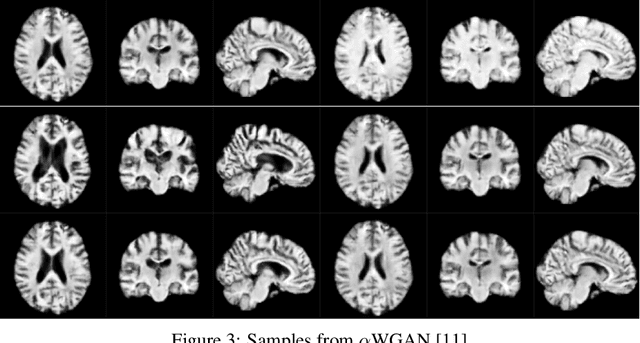
Generative modeling of 3D brain MRIs presents difficulties in achieving high visual fidelity while ensuring sufficient coverage of the data distribution. In this work, we propose to address this challenge with composable, multiscale morphological transformations in a variational autoencoder (VAE) framework. These transformations are applied to a chosen reference brain image to generate MRI volumes, equipping the model with strong anatomical inductive biases. We structure the VAE latent space in a way such that the model covers the data distribution sufficiently well. We show substantial performance improvements in FID while retaining comparable, or superior, reconstruction quality compared to prior work based on VAEs and generative adversarial networks (GANs).
Does progress on ImageNet transfer to real-world datasets?
Jan 11, 2023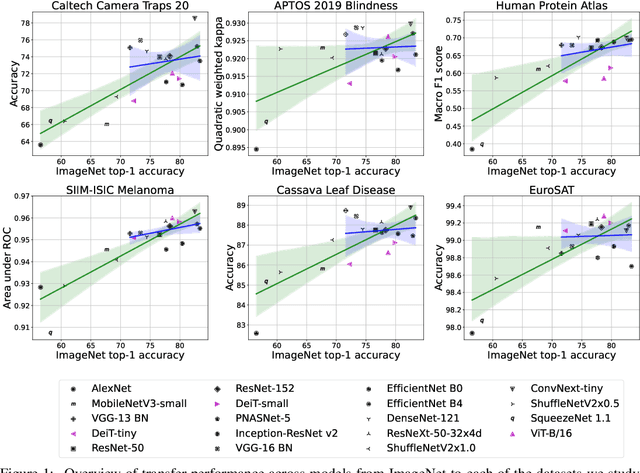
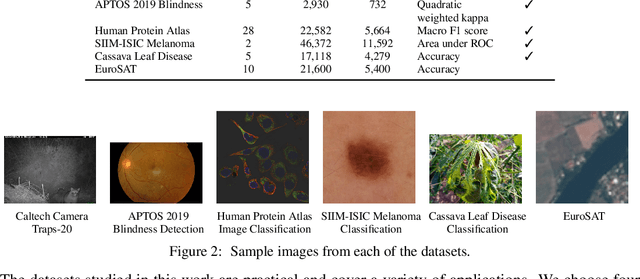
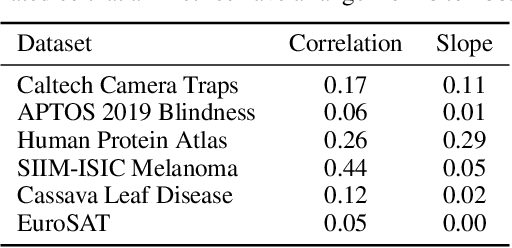
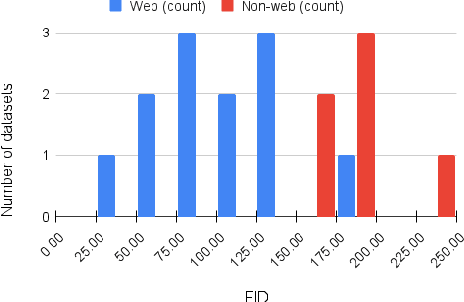
Does progress on ImageNet transfer to real-world datasets? We investigate this question by evaluating ImageNet pre-trained models with varying accuracy (57% - 83%) on six practical image classification datasets. In particular, we study datasets collected with the goal of solving real-world tasks (e.g., classifying images from camera traps or satellites), as opposed to web-scraped benchmarks collected for comparing models. On multiple datasets, models with higher ImageNet accuracy do not consistently yield performance improvements. For certain tasks, interventions such as data augmentation improve performance even when architectures do not. We hope that future benchmarks will include more diverse datasets to encourage a more comprehensive approach to improving learning algorithms.
UMFuse: Unified Multi View Fusion for Human Editing applications
Dec 01, 2022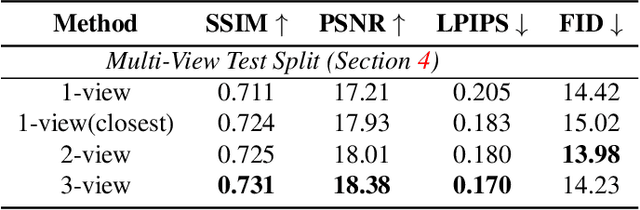
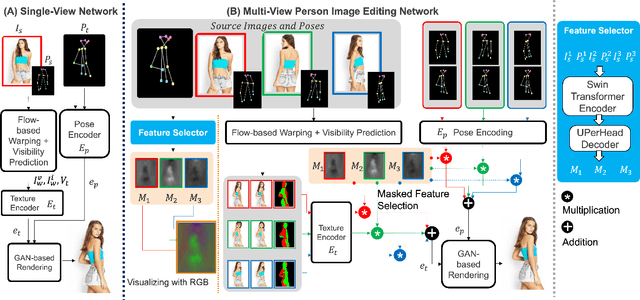
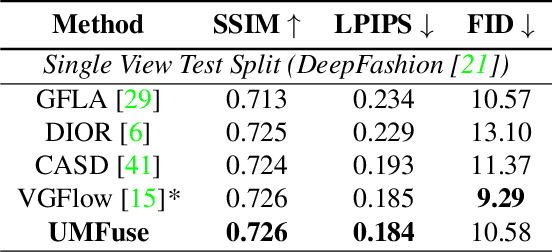
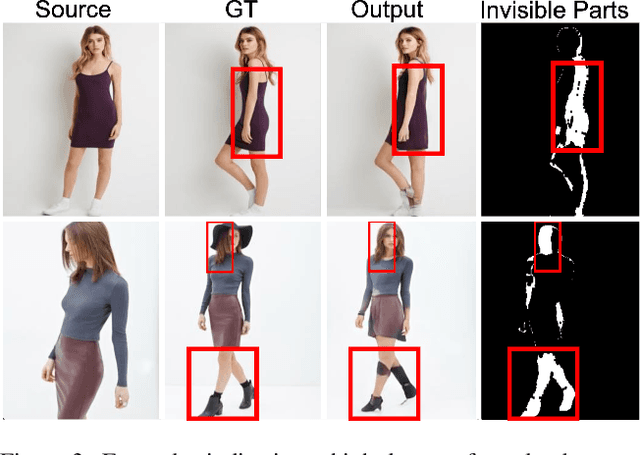
The vision community has explored numerous pose guided human editing methods due to their extensive practical applications. Most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. However, the problem is ill-defined in cases when the target pose is significantly different from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse the knowledge from multiple viewpoints, we design a selector network that takes the pose keypoints and texture from images and generates an interpretable per-pixel selection map. After that, the encodings from a separate network (trained on a single image human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on 2 newly proposed tasks - Multi-view human reposing, and Mix-and-match human image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a much better alternative.
The state-of-the-art 3D anisotropic intracranial hemorrhage segmentation on non-contrast head CT: The INSTANCE challenge
Jan 09, 2023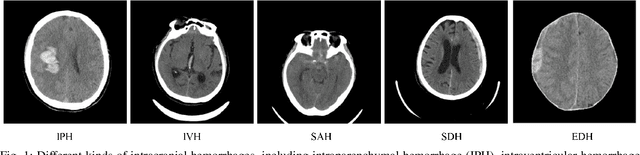
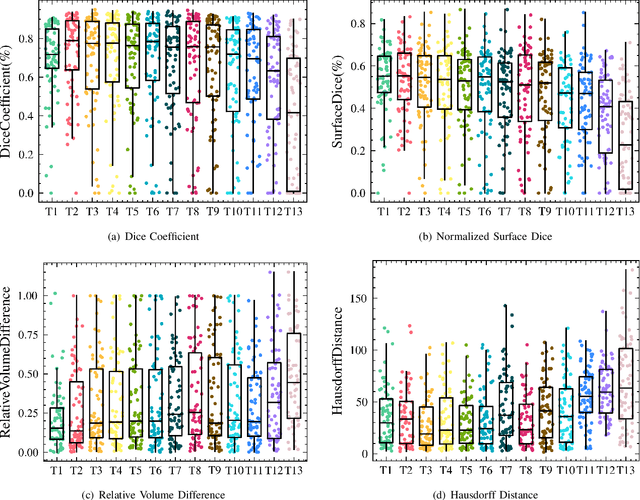
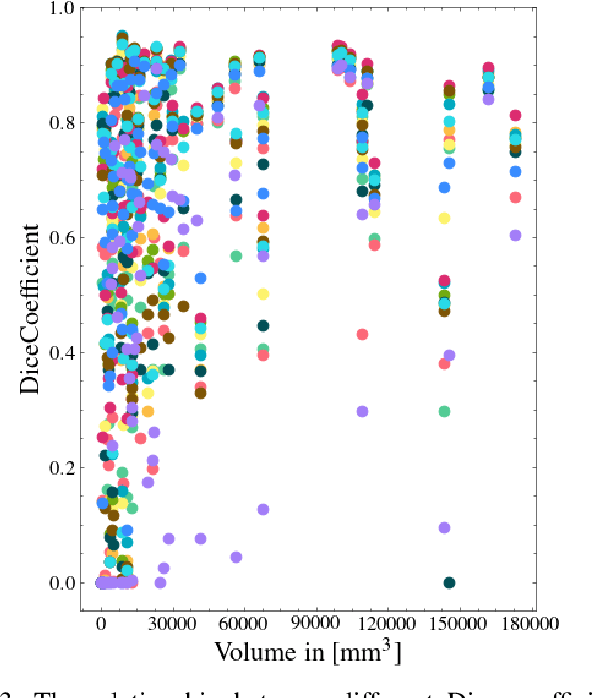
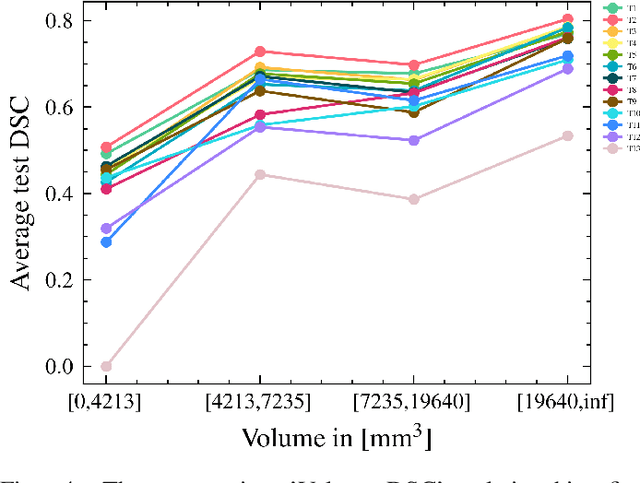
Automatic intracranial hemorrhage segmentation in 3D non-contrast head CT (NCCT) scans is significant in clinical practice. Existing hemorrhage segmentation methods usually ignores the anisotropic nature of the NCCT, and are evaluated on different in-house datasets with distinct metrics, making it highly challenging to improve segmentation performance and perform objective comparisons among different methods. The INSTANCE 2022 was a grand challenge held in conjunction with the 2022 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). It is intended to resolve the above-mentioned problems and promote the development of both intracranial hemorrhage segmentation and anisotropic data processing. The INSTANCE released a training set of 100 cases with ground-truth and a validation set with 30 cases without ground-truth labels that were available to the participants. A held-out testing set with 70 cases is utilized for the final evaluation and ranking. The methods from different participants are ranked based on four metrics, including Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), Relative Volume Difference (RVD) and Normalized Surface Dice (NSD). A total of 13 teams submitted distinct solutions to resolve the challenges, making several baseline models, pre-processing strategies and anisotropic data processing techniques available to future researchers. The winner method achieved an average DSC of 0.6925, demonstrating a significant growth over our proposed baseline method. To the best of our knowledge, the proposed INSTANCE challenge releases the first intracranial hemorrhage segmentation benchmark, and is also the first challenge that intended to resolve the anisotropic problem in 3D medical image segmentation, which provides new alternatives in these research fields.