 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Adversarial and Collaborative Learning for Self-Supervised Action Recognition
Jul 15, 2023



Considering the instance-level discriminative ability, contrastive learning methods, including MoCo and SimCLR, have been adapted from the original image representation learning task to solve the self-supervised skeleton-based action recognition task. These methods usually use multiple data streams (i.e., joint, motion, and bone) for ensemble learning, meanwhile, how to construct a discriminative feature space within a single stream and effectively aggregate the information from multiple streams remains an open problem. To this end, we first apply a new contrastive learning method called BYOL to learn from skeleton data and formulate SkeletonBYOL as a simple yet effective baseline for self-supervised skeleton-based action recognition. Inspired by SkeletonBYOL, we further present a joint Adversarial and Collaborative Learning (ACL) framework, which combines Cross-Model Adversarial Learning (CMAL) and Cross-Stream Collaborative Learning (CSCL). Specifically, CMAL learns single-stream representation by cross-model adversarial loss to obtain more discriminative features. To aggregate and interact with multi-stream information, CSCL is designed by generating similarity pseudo label of ensemble learning as supervision and guiding feature generation for individual streams. Exhaustive experiments on three datasets verify the complementary properties between CMAL and CSCL and also verify that our method can perform favorably against state-of-the-art methods using various evaluation protocols. Our code and models are publicly available at \url{https://github.com/Levigty/ACL}.
FSAR: Federated Skeleton-based Action Recognition with Adaptive Topology Structure and Knowledge Distillation
Jun 19, 2023



Existing skeleton-based action recognition methods typically follow a centralized learning paradigm, which can pose privacy concerns when exposing human-related videos. Federated Learning (FL) has attracted much attention due to its outstanding advantages in privacy-preserving. However, directly applying FL approaches to skeleton videos suffers from unstable training. In this paper, we investigate and discover that the heterogeneous human topology graph structure is the crucial factor hindering training stability. To address this limitation, we pioneer a novel Federated Skeleton-based Action Recognition (FSAR) paradigm, which enables the construction of a globally generalized model without accessing local sensitive data. Specifically, we introduce an Adaptive Topology Structure (ATS), separating generalization and personalization by learning a domain-invariant topology shared across clients and a domain-specific topology decoupled from global model aggregation.Furthermore, we explore Multi-grain Knowledge Distillation (MKD) to mitigate the discrepancy between clients and server caused by distinct updating patterns through aligning shallow block-wise motion features. Extensive experiments on multiple datasets demonstrate that FSAR outperforms state-of-the-art FL-based methods while inherently protecting privacy.
The state-of-the-art 3D anisotropic intracranial hemorrhage segmentation on non-contrast head CT: The INSTANCE challenge
Jan 12, 2023Automatic intracranial hemorrhage segmentation in 3D non-contrast head CT (NCCT) scans is significant in clinical practice. Existing hemorrhage segmentation methods usually ignores the anisotropic nature of the NCCT, and are evaluated on different in-house datasets with distinct metrics, making it highly challenging to improve segmentation performance and perform objective comparisons among different methods. The INSTANCE 2022 was a grand challenge held in conjunction with the 2022 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). It is intended to resolve the above-mentioned problems and promote the development of both intracranial hemorrhage segmentation and anisotropic data processing. The INSTANCE released a training set of 100 cases with ground-truth and a validation set with 30 cases without ground-truth labels that were available to the participants. A held-out testing set with 70 cases is utilized for the final evaluation and ranking. The methods from different participants are ranked based on four metrics, including Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), Relative Volume Difference (RVD) and Normalized Surface Dice (NSD). A total of 13 teams submitted distinct solutions to resolve the challenges, making several baseline models, pre-processing strategies and anisotropic data processing techniques available to future researchers. The winner method achieved an average DSC of 0.6925, demonstrating a significant growth over our proposed baseline method. To the best of our knowledge, the proposed INSTANCE challenge releases the first intracranial hemorrhage segmentation benchmark, and is also the first challenge that intended to resolve the anisotropic problem in 3D medical image segmentation, which provides new alternatives in these research fields.
Identity-Sensitive Knowledge Propagation for Cloth-Changing Person Re-identification
Aug 25, 2022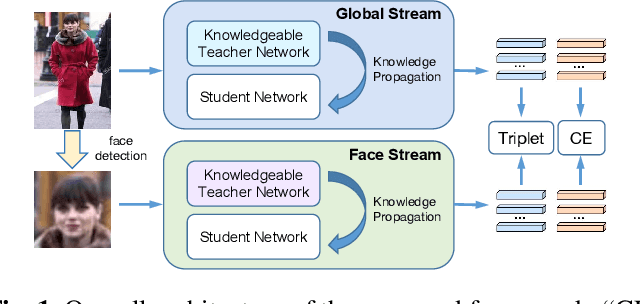
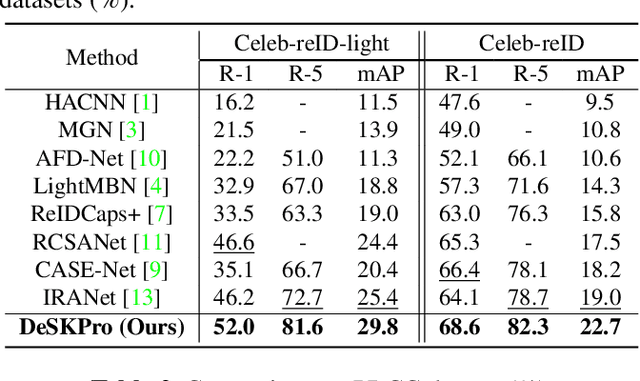
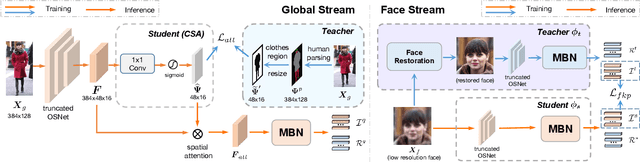
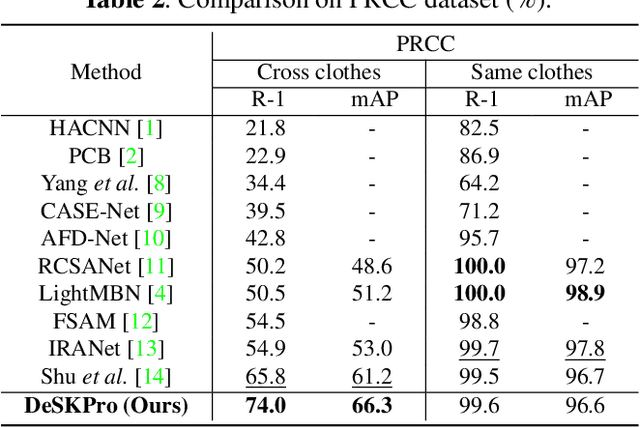
Cloth-changing person re-identification (CC-ReID), which aims to match person identities under clothing changes, is a new rising research topic in recent years. However, typical biometrics-based CC-ReID methods often require cumbersome pose or body part estimators to learn cloth-irrelevant features from human biometric traits, which comes with high computational costs. Besides, the performance is significantly limited due to the resolution degradation of surveillance images. To address the above limitations, we propose an effective Identity-Sensitive Knowledge Propagation framework (DeSKPro) for CC-ReID. Specifically, a Cloth-irrelevant Spatial Attention module is introduced to eliminate the distraction of clothing appearance by acquiring knowledge from the human parsing module. To mitigate the resolution degradation issue and mine identity-sensitive cues from human faces, we propose to restore the missing facial details using prior facial knowledge, which is then propagated to a smaller network. After training, the extra computations for human parsing or face restoration are no longer required. Extensive experiments show that our framework outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/KimbingNg/DeskPro.