 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meta-Learned Kernel For Blind Super-Resolution Kernel Estimation
Dec 15, 2022
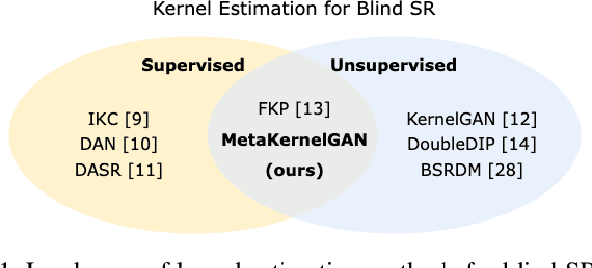
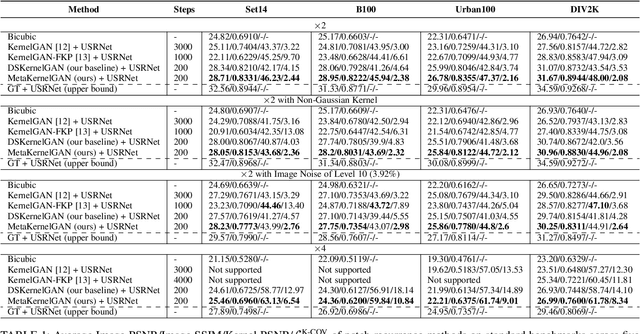
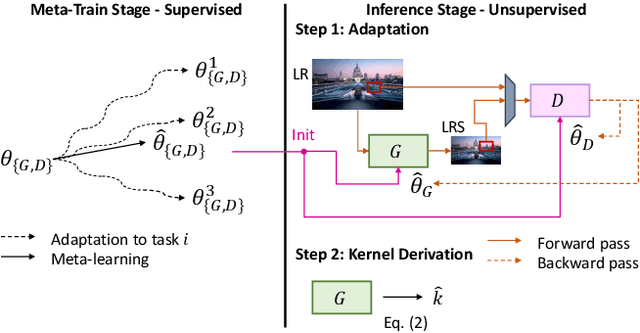
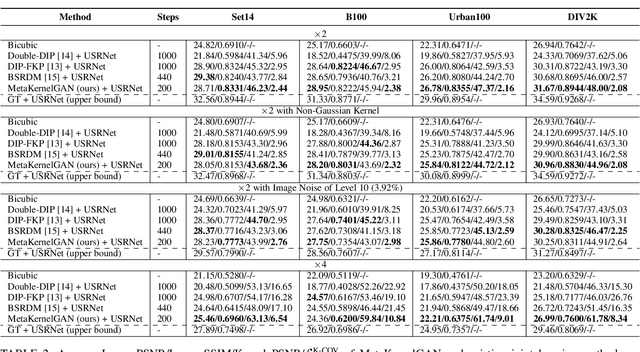
Recent image degradation estimation methods have enabled single-image super-resolution (SR) approaches to better upsample real-world images. Among these methods, explicit kernel estimation approaches have demonstrated unprecedented performance at handling unknown degradations. Nonetheless, a number of limitations constrain their efficacy when used by downstream SR models. Specifically, this family of methods yields i) excessive inference time due to long per-image adaptation times and ii) inferior image fidelity due to kernel mismatch. In this work, we introduce a learning-to-learn approach that meta-learns from the information contained in a distribution of images, thereby enabling significantly faster adaptation to new images with substantially improved performance in both kernel estimation and image fidelity. Specifically, we meta-train a kernel-generating GAN, named MetaKernelGAN, on a range of tasks, such that when a new image is presented, the generator starts from an informed kernel estimate and the discriminator starts with a strong capability to distinguish between patch distributions. Compared with state-of-the-art methods, our experiments show that MetaKernelGAN better estimates the magnitude and covariance of the kernel, leading to state-of-the-art blind SR results within a similar computational regime when combined with a non-blind SR model. Through supervised learning of an unsupervised learner, our method maintains the generalizability of the unsupervised learner, improves the optimization stability of kernel estimation, and hence image adaptation, and leads to a faster inference with a speedup between 14.24 to 102.1x over existing methods.
Criteria Comparative Learning for Real-scene Image Super-Resolution
Jul 26, 2022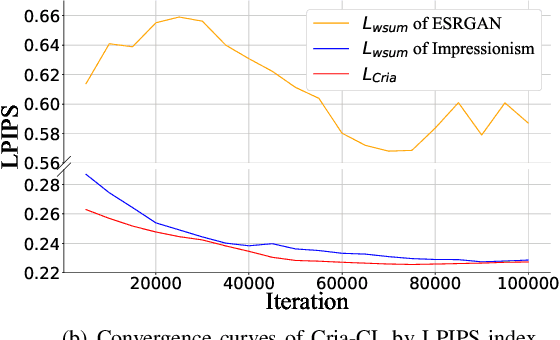
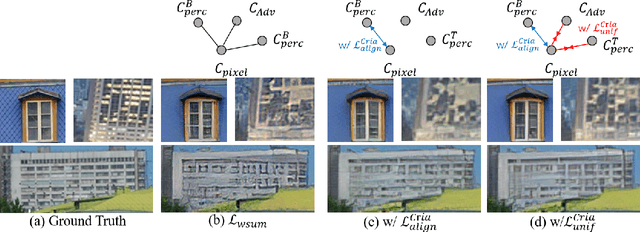
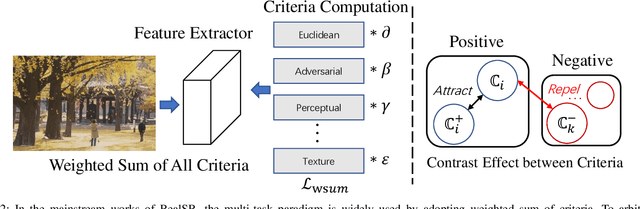
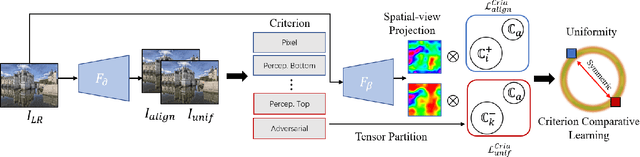
Real-scene image super-resolution aims to restore real-world low-resolution images into their high-quality versions. A typical RealSR framework usually includes the optimization of multiple criteria which are designed for different image properties, by making the implicit assumption that the ground-truth images can provide a good trade-off between different criteria. However, this assumption could be easily violated in practice due to the inherent contrastive relationship between different image properties. Contrastive learning (CL) provides a promising recipe to relieve this problem by learning discriminative features using the triplet contrastive losses. Though CL has achieved significant success in many computer vision tasks, it is non-trivial to introduce CL to RealSR due to the difficulty in defining valid positive image pairs in this case. Inspired by the observation that the contrastive relationship could also exist between the criteria, in this work, we propose a novel training paradigm for RealSR, named Criteria Comparative Learning (Cria-CL), by developing contrastive losses defined on criteria instead of image patches. In addition, a spatial projector is proposed to obtain a good view for Cria-CL in RealSR. Our experiments demonstrate that compared with the typical weighted regression strategy, our method achieves a significant improvement under similar parameter settings.
IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Feb 12, 2023
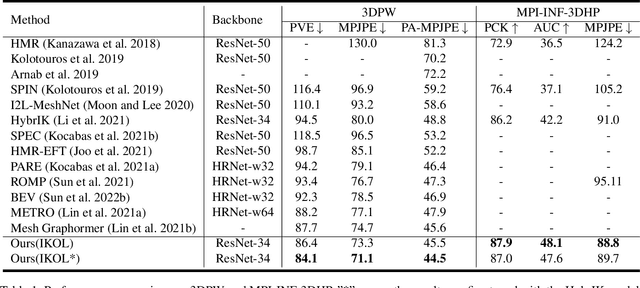
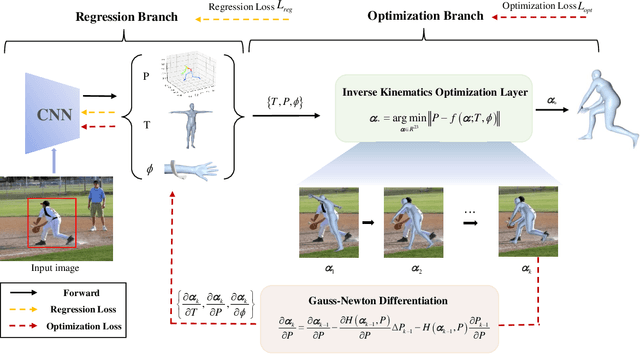
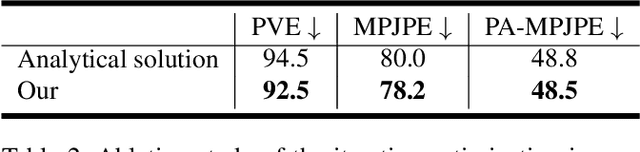
This paper presents an inverse kinematic optimization layer (IKOL) for 3D human pose and shape estimation that leverages the strength of both optimization- and regression-based methods within an end-to-end framework. IKOL involves a nonconvex optimization that establishes an implicit mapping from an image's 3D keypoints and body shapes to the relative body-part rotations. The 3D keypoints and the body shapes are the inputs and the relative body-part rotations are the solutions. However, this procedure is implicit and hard to make differentiable. So, to overcome this issue, we designed a Gauss-Newton differentiation (GN-Diff) procedure to differentiate IKOL. GN-Diff iteratively linearizes the nonconvex objective function to obtain Gauss-Newton directions with closed form solutions. Then, an automatic differentiation procedure is directly applied to generate a Jacobian matrix for end-to-end training. Notably, the GN-Diff procedure works fast because it does not rely on a time-consuming implicit differentiation procedure. The twist rotation and shape parameters are learned from the neural networks and, as a result, IKOL has a much lower computational overhead than most existing optimization-based methods. Additionally, compared to existing regression-based methods, IKOL provides a more accurate mesh-image correspondence. This is because it iteratively reduces the distance between the keypoints and also enhances the reliability of the pose structures. Extensive experiments demonstrate the superiority of our proposed framework over a wide range of 3D human pose and shape estimation methods.
Study on the identification limits of craniofacial superimposition
Jan 24, 2023
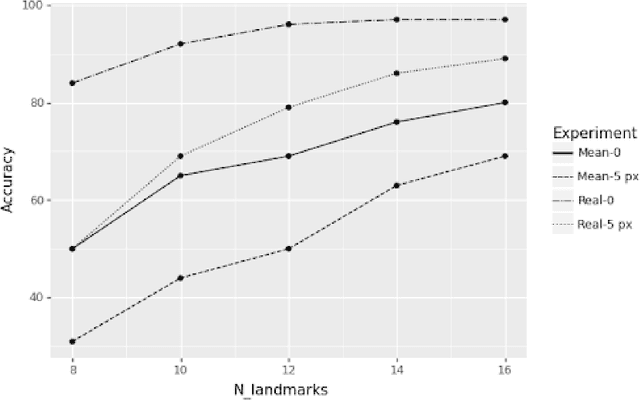
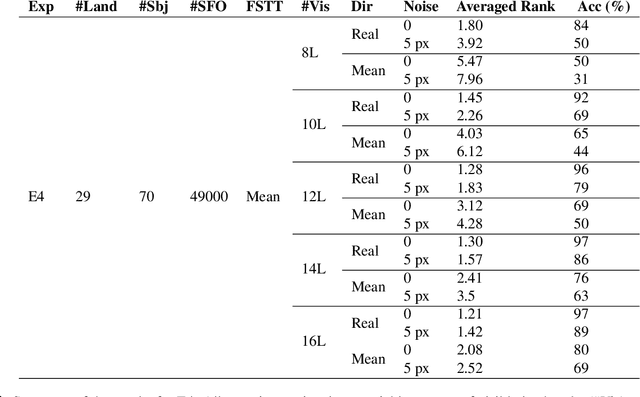
Craniofacial Superimposition involves the superimposition of an image of a skull with a number of ante-mortem face images of an individual and the analysis of their morphological correspondence. Despite being used for one century, it is not yet a mature and fully accepted technique due to the absence of solid scientific approaches, significant reliability studies, and international standards. In this paper we present a comprehensive experimentation on the limitations of Craniofacial Superimposition as a forensic identification technique. The study involves different experiments over more than 1 Million comparisons performed by a landmark-based automatic 3D/2D superimposition method. The total sample analyzed consists of 320 subjects and 29 craniofacial landmarks.
SlideVQA: A Dataset for Document Visual Question Answering on Multiple Images
Jan 12, 2023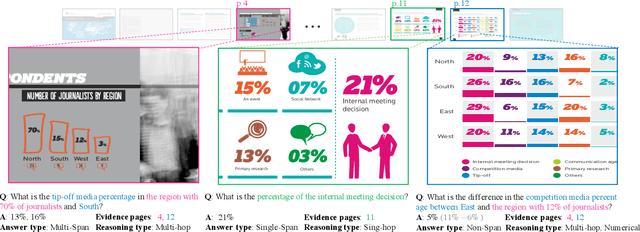

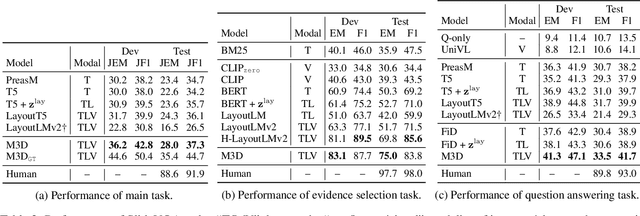
Visual question answering on document images that contain textual, visual, and layout information, called document VQA, has received much attention recently. Although many datasets have been proposed for developing document VQA systems, most of the existing datasets focus on understanding the content relationships within a single image and not across multiple images. In this study, we propose a new multi-image document VQA dataset, SlideVQA, containing 2.6k+ slide decks composed of 52k+ slide images and 14.5k questions about a slide deck. SlideVQA requires complex reasoning, including single-hop, multi-hop, and numerical reasoning, and also provides annotated arithmetic expressions of numerical answers for enhancing the ability of numerical reasoning. Moreover, we developed a new end-to-end document VQA model that treats evidence selection and question answering in a unified sequence-to-sequence format. Experiments on SlideVQA show that our model outperformed existing state-of-the-art QA models, but that it still has a large gap behind human performance. We believe that our dataset will facilitate research on document VQA.
SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation
Feb 04, 2023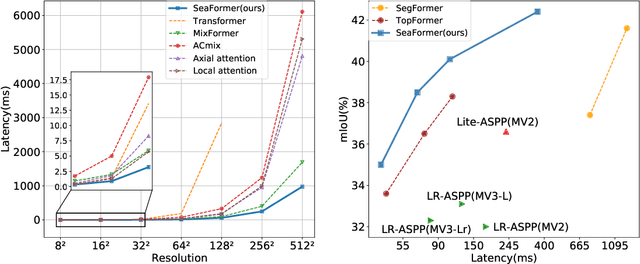
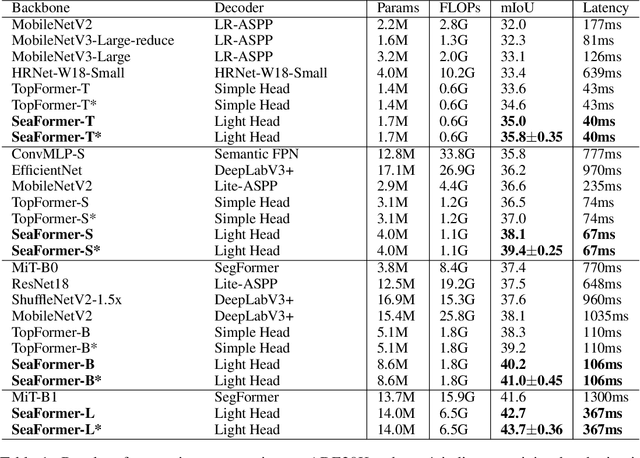
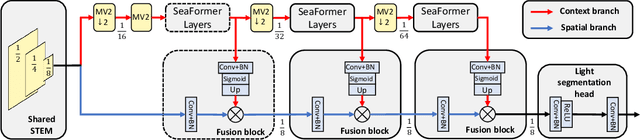
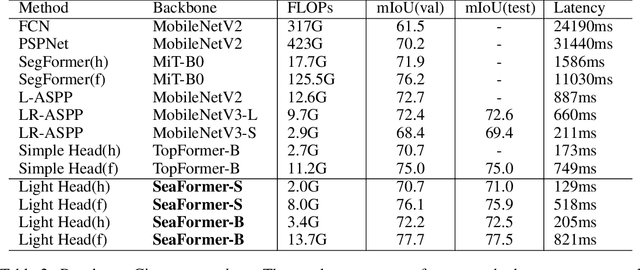
Since the introduction of Vision Transformers, the landscape of many computer vision tasks (e.g., semantic segmentation), which has been overwhelmingly dominated by CNNs, recently has significantly revolutionized. However, the computational cost and memory requirement render these methods unsuitable on the mobile device, especially for the high-resolution per-pixel semantic segmentation task. In this paper, we introduce a new method squeeze-enhanced Axial TransFormer (SeaFormer) for mobile semantic segmentation. Specifically, we design a generic attention block characterized by the formulation of squeeze Axial and detail enhancement. It can be further used to create a family of backbone architectures with superior cost-effectiveness. Coupled with a light segmentation head, we achieve the best trade-off between segmentation accuracy and latency on the ARM-based mobile devices on the ADE20K and Cityscapes datasets. Critically, we beat both the mobile-friendly rivals and Transformer-based counterparts with better performance and lower latency without bells and whistles. Beyond semantic segmentation, we further apply the proposed SeaFormer architecture to image classification problem, demonstrating the potentials of serving as a versatile mobile-friendly backbone.
When are Lemons Purple? The Concept Association Bias of CLIP
Dec 22, 2022



Large-scale vision-language models such as CLIP have shown impressive performance on zero-shot image classification and image-to-text retrieval. However, such zero-shot performance of CLIP-based models does not realize in tasks that require a finer-grained correspondence between vision and language, such as Visual Question Answering (VQA). We investigate why this is the case, and report an interesting phenomenon of CLIP, which we call the Concept Association Bias (CAB), as a potential cause of the difficulty of applying CLIP to VQA and similar tasks. CAB is especially apparent when two concepts are present in the given image while a text prompt only contains a single concept. In such a case, we find that CLIP tends to treat input as a bag of concepts and attempts to fill in the other missing concept crossmodally, leading to an unexpected zero-shot prediction. For example, when asked for the color of a lemon in an image, CLIP predicts ``purple'' if the image contains a lemon and an eggplant. We demonstrate the Concept Association Bias of CLIP by showing that CLIP's zero-shot classification performance greatly suffers when there is a strong concept association between an object (e.g. lemon) and an attribute (e.g. its color). On the other hand, when the association between object and attribute is weak, we do not see this phenomenon. Furthermore, we show that CAB is significantly mitigated when we enable CLIP to learn deeper structure across image and text embeddings by adding an additional Transformer on top of CLIP and fine-tuning it on VQA. We find that across such fine-tuned variants of CLIP, the strength of CAB in a model predicts how well it performs on VQA.
Restoring Vision in Hazy Weather with Hierarchical Contrastive Learning
Dec 22, 2022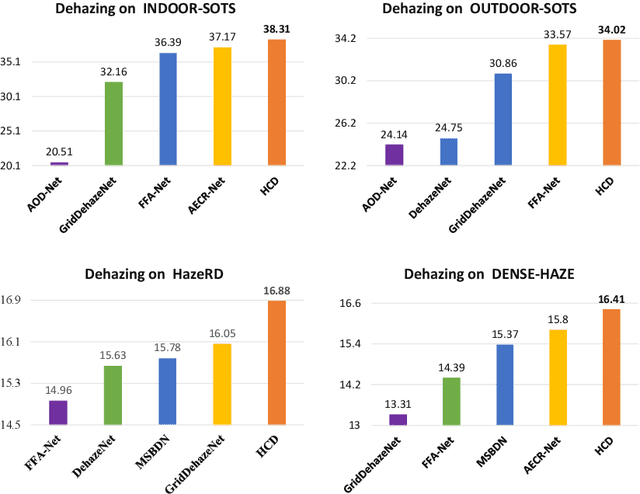
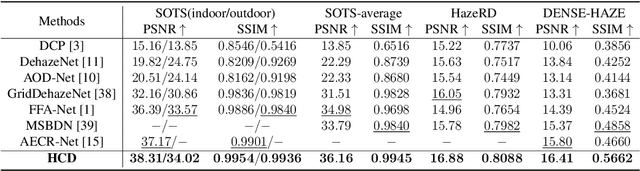
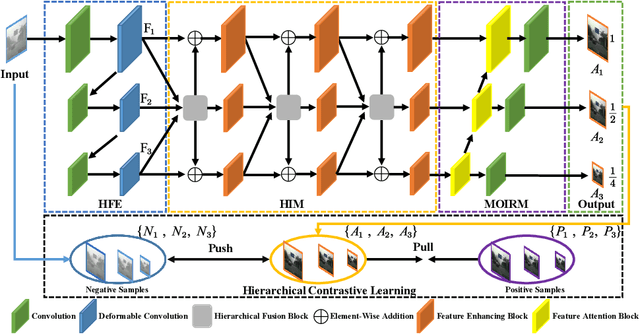
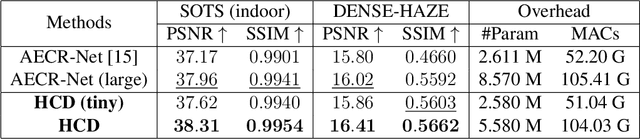
Image restoration under hazy weather condition, which is called single image dehazing, has been of significant interest for various computer vision applications. In recent years, deep learning-based methods have achieved success. However, existing image dehazing methods typically neglect the hierarchy of features in the neural network and fail to exploit their relationships fully. To this end, we propose an effective image dehazing method named Hierarchical Contrastive Dehazing (HCD), which is based on feature fusion and contrastive learning strategies. HCD consists of a hierarchical dehazing network (HDN) and a novel hierarchical contrastive loss (HCL). Specifically, the core design in the HDN is a Hierarchical Interaction Module, which utilizes multi-scale activation to revise the feature responses hierarchically. To cooperate with the training of HDN, we propose HCL which performs contrastive learning on hierarchically paired exemplars, facilitating haze removal. Extensive experiments on public datasets, RESIDE, HazeRD, and DENSE-HAZE, demonstrate that HCD quantitatively outperforms the state-of-the-art methods in terms of PSNR, SSIM and achieves better visual quality.
Q-Diffusion: Quantizing Diffusion Models
Feb 08, 2023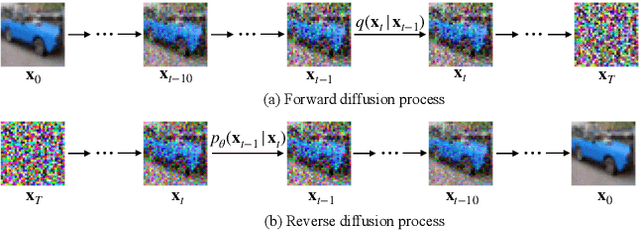

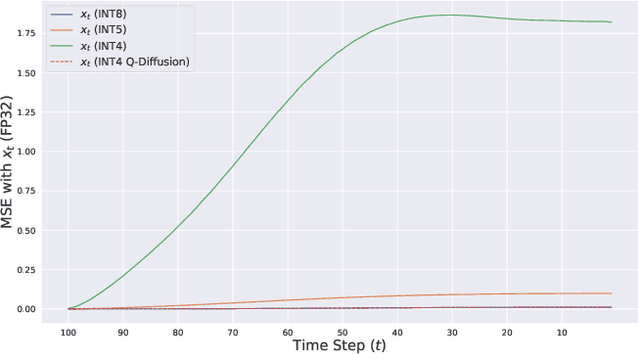
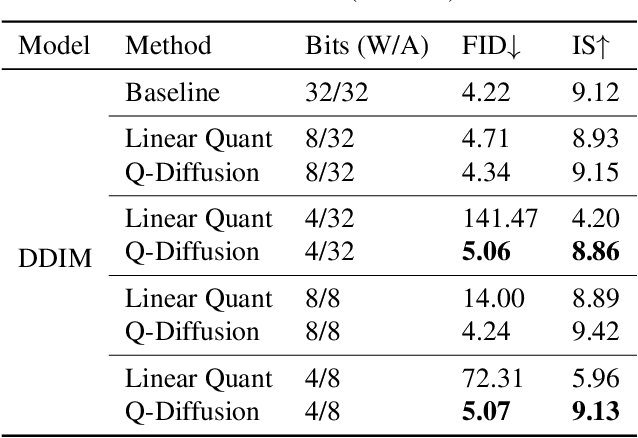
Diffusion models have recently achieved great success in synthesizing diverse and high-fidelity images. However, sampling speed and memory constraints remain a major barrier to the practical adoption of diffusion models as the generation process for these models can be slow due to the need for iterative noise estimation using complex neural networks. We propose a solution to this problem by compressing the noise estimation network to accelerate the generation process using post-training quantization (PTQ). While existing PTQ approaches have not been able to effectively deal with the changing output distributions of noise estimation networks in diffusion models over multiple time steps, we are able to formulate a PTQ method that is specifically designed to handle the unique multi-timestep structure of diffusion models with a data calibration scheme using data sampled from different time steps. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a FID change of at most 1.88. Our approach can also be applied to text-guided image generation, and for the first time we can run stable diffusion in 4-bit weights without losing much perceptual quality, as shown in Figure 5 and Figure 9.
TetCNN: Convolutional Neural Networks on Tetrahedral Meshes
Feb 08, 2023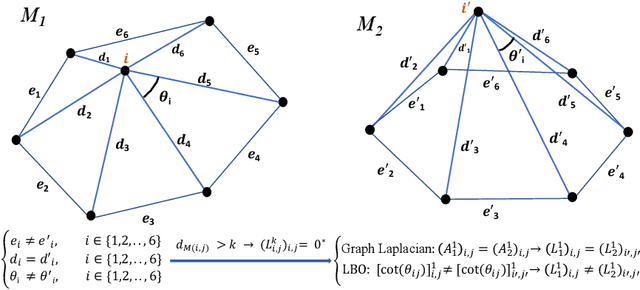
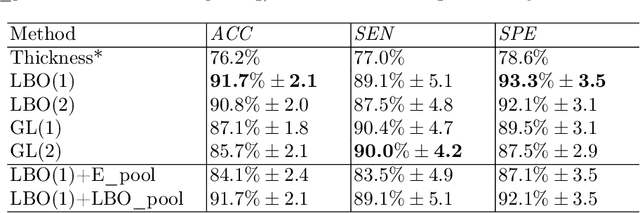
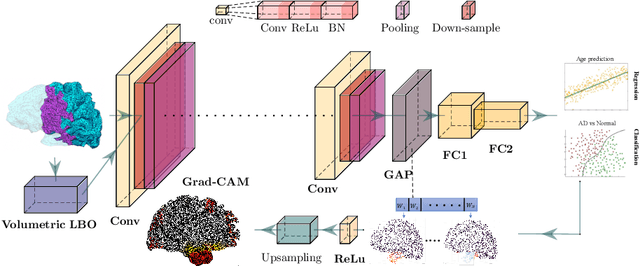
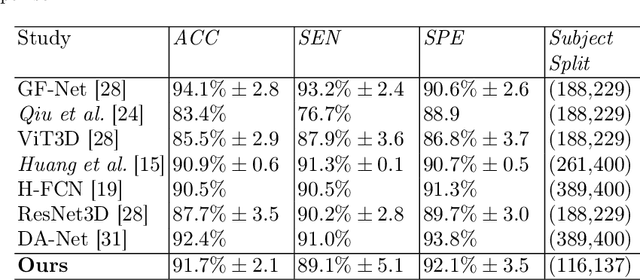
Convolutional neural networks (CNN) have been broadly studied on images, videos, graphs, and triangular meshes. However, it has seldom been studied on tetrahedral meshes. Given the merits of using volumetric meshes in applications like brain image analysis, we introduce a novel interpretable graph CNN framework for the tetrahedral mesh structure. Inspired by ChebyNet, our model exploits the volumetric Laplace-Beltrami Operator (LBO) to define filters over commonly used graph Laplacian which lacks the Riemannian metric information of 3D manifolds. For pooling adaptation, we introduce new objective functions for localized minimum cuts in the Graclus algorithm based on the LBO. We employ a piece-wise constant approximation scheme that uses the clustering assignment matrix to estimate the LBO on sampled meshes after each pooling. Finally, adapting the Gradient-weighted Class Activation Mapping algorithm for tetrahedral meshes, we use the obtained heatmaps to visualize discovered regions-of-interest as biomarkers. We demonstrate the effectiveness of our model on cortical tetrahedral meshes from patients with Alzheimer's disease, as there is scientific evidence showing the correlation of cortical thickness to neurodegenerative disease progression. Our results show the superiority of our LBO-based convolution layer and adapted pooling over the conventionally used unitary cortical thickness, graph Laplacian, and point cloud representation.