 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgery
Forgery detection is the process of identifying and detecting forged or manipulated documents, images, or videos.
Papers and Code
Towards Responsible Evaluation for Text-to-Speech
Oct 08, 2025



Recent advances in text-to-speech (TTS) technology have enabled systems to produce human-indistinguishable speech, bringing benefits across accessibility, content creation, and human-computer interaction. However, current evaluation practices are increasingly inadequate for capturing the full range of capabilities, limitations, and societal implications. This position paper introduces the concept of Responsible Evaluation and argues that it is essential and urgent for the next phase of TTS development, structured through three progressive levels: (1) ensuring the faithful and accurate reflection of a model's true capabilities, with more robust, discriminative, and comprehensive objective and subjective scoring methodologies; (2) enabling comparability, standardization, and transferability through standardized benchmarks, transparent reporting, and transferable evaluation metrics; and (3) assessing and mitigating ethical risks associated with forgery, misuse, privacy violations, and security vulnerabilities. Through this concept, we critically examine current evaluation practices, identify systemic shortcomings, and propose actionable recommendations. We hope this concept of Responsible Evaluation will foster more trustworthy and reliable TTS technology and guide its development toward ethically sound and societally beneficial applications.
LAKAN: Landmark-assisted Adaptive Kolmogorov-Arnold Network for Face Forgery Detection
Oct 01, 2025The rapid development of deepfake generation techniques necessitates robust face forgery detection algorithms. While methods based on Convolutional Neural Networks (CNNs) and Transformers are effective, there is still room for improvement in modeling the highly complex and non-linear nature of forgery artifacts. To address this issue, we propose a novel detection method based on the Kolmogorov-Arnold Network (KAN). By replacing fixed activation functions with learnable splines, our KAN-based approach is better suited to this challenge. Furthermore, to guide the network's focus towards critical facial areas, we introduce a Landmark-assisted Adaptive Kolmogorov-Arnold Network (LAKAN) module. This module uses facial landmarks as a structural prior to dynamically generate the internal parameters of the KAN, creating an instance-specific signal that steers a general-purpose image encoder towards the most informative facial regions with artifacts. This core innovation creates a powerful combination between geometric priors and the network's learning process. Extensive experiments on multiple public datasets show that our proposed method achieves superior performance.
FreqDebias: Towards Generalizable Deepfake Detection via Consistency-Driven Frequency Debiasing
Sep 26, 2025Deepfake detectors often struggle to generalize to novel forgery types due to biases learned from limited training data. In this paper, we identify a new type of model bias in the frequency domain, termed spectral bias, where detectors overly rely on specific frequency bands, restricting their ability to generalize across unseen forgeries. To address this, we propose FreqDebias, a frequency debiasing framework that mitigates spectral bias through two complementary strategies. First, we introduce a novel Forgery Mixup (Fo-Mixup) augmentation, which dynamically diversifies frequency characteristics of training samples. Second, we incorporate a dual consistency regularization (CR), which enforces both local consistency using class activation maps (CAMs) and global consistency through a von Mises-Fisher (vMF) distribution on a hyperspherical embedding space. This dual CR mitigates over-reliance on certain frequency components by promoting consistent representation learning under both local and global supervision. Extensive experiments show that FreqDebias significantly enhances cross-domain generalization and outperforms state-of-the-art methods in both cross-domain and in-domain settings.
Toward Medical Deepfake Detection: A Comprehensive Dataset and Novel Method
Sep 19, 2025The rapid advancement of generative AI in medical imaging has introduced both significant opportunities and serious challenges, especially the risk that fake medical images could undermine healthcare systems. These synthetic images pose serious risks, such as diagnostic deception, financial fraud, and misinformation. However, research on medical forensics to counter these threats remains limited, and there is a critical lack of comprehensive datasets specifically tailored for this field. Additionally, existing media forensic methods, which are primarily designed for natural or facial images, are inadequate for capturing the distinct characteristics and subtle artifacts of AI-generated medical images. To tackle these challenges, we introduce \textbf{MedForensics}, a large-scale medical forensics dataset encompassing six medical modalities and twelve state-of-the-art medical generative models. We also propose \textbf{DSKI}, a novel \textbf{D}ual-\textbf{S}tage \textbf{K}nowledge \textbf{I}nfusing detector that constructs a vision-language feature space tailored for the detection of AI-generated medical images. DSKI comprises two core components: 1) a cross-domain fine-trace adapter (CDFA) for extracting subtle forgery clues from both spatial and noise domains during training, and 2) a medical forensic retrieval module (MFRM) that boosts detection accuracy through few-shot retrieval during testing. Experimental results demonstrate that DSKI significantly outperforms both existing methods and human experts, achieving superior accuracy across multiple medical modalities.
Towards Robust Defense against Customization via Protective Perturbation Resistant to Diffusion-based Purification
Sep 19, 2025Diffusion models like Stable Diffusion have become prominent in visual synthesis tasks due to their powerful customization capabilities, which also introduce significant security risks, including deepfakes and copyright infringement. In response, a class of methods known as protective perturbation emerged, which mitigates image misuse by injecting imperceptible adversarial noise. However, purification can remove protective perturbations, thereby exposing images again to the risk of malicious forgery. In this work, we formalize the anti-purification task, highlighting challenges that hinder existing approaches, and propose a simple diagnostic protective perturbation named AntiPure. AntiPure exposes vulnerabilities of purification within the "purification-customization" workflow, owing to two guidance mechanisms: 1) Patch-wise Frequency Guidance, which reduces the model's influence over high-frequency components in the purified image, and 2) Erroneous Timestep Guidance, which disrupts the model's denoising strategy across different timesteps. With additional guidance, AntiPure embeds imperceptible perturbations that persist under representative purification settings, achieving effective post-customization distortion. Experiments show that, as a stress test for purification, AntiPure achieves minimal perceptual discrepancy and maximal distortion, outperforming other protective perturbation methods within the purification-customization workflow.
TrueMoE: Dual-Routing Mixture of Discriminative Experts for Synthetic Image Detection
Sep 19, 2025



The rapid progress of generative models has made synthetic image detection an increasingly critical task. Most existing approaches attempt to construct a single, universal discriminative space to separate real from fake content. However, such unified spaces tend to be complex and brittle, often struggling to generalize to unseen generative patterns. In this work, we propose TrueMoE, a novel dual-routing Mixture-of-Discriminative-Experts framework that reformulates the detection task as a collaborative inference across multiple specialized and lightweight discriminative subspaces. At the core of TrueMoE is a Discriminative Expert Array (DEA) organized along complementary axes of manifold structure and perceptual granularity, enabling diverse forgery cues to be captured across subspaces. A dual-routing mechanism, comprising a granularity-aware sparse router and a manifold-aware dense router, adaptively assigns input images to the most relevant experts. Extensive experiments across a wide spectrum of generative models demonstrate that TrueMoE achieves superior generalization and robustness.
Causal Fingerprints of AI Generative Models
Sep 18, 2025AI generative models leave implicit traces in their generated images, which are commonly referred to as model fingerprints and are exploited for source attribution. Prior methods rely on model-specific cues or synthesis artifacts, yielding limited fingerprints that may generalize poorly across different generative models. We argue that a complete model fingerprint should reflect the causality between image provenance and model traces, a direction largely unexplored. To this end, we conceptualize the \emph{causal fingerprint} of generative models, and propose a causality-decoupling framework that disentangles it from image-specific content and style in a semantic-invariant latent space derived from pre-trained diffusion reconstruction residual. We further enhance fingerprint granularity with diverse feature representations. We validate causality by assessing attribution performance across representative GANs and diffusion models and by achieving source anonymization using counterfactual examples generated from causal fingerprints. Experiments show our approach outperforms existing methods in model attribution, indicating strong potential for forgery detection, model copyright tracing, and identity protection.
DF-LLaVA: Unlocking MLLM's potential for Synthetic Image Detection via Prompt-Guided Knowledge Injection
Sep 18, 2025With the increasing prevalence of synthetic images, evaluating image authenticity and locating forgeries accurately while maintaining human interpretability remains a challenging task. Existing detection models primarily focus on simple authenticity classification, ultimately providing only a forgery probability or binary judgment, which offers limited explanatory insights into image authenticity. Moreover, while MLLM-based detection methods can provide more interpretable results, they still lag behind expert models in terms of pure authenticity classification accuracy. To address this, we propose DF-LLaVA, a simple yet effective framework that unlocks the intrinsic discrimination potential of MLLMs. Our approach first extracts latent knowledge from MLLMs and then injects it into training via prompts. This framework allows LLaVA to achieve outstanding detection accuracy exceeding expert models while still maintaining the interpretability offered by MLLMs. Extensive experiments confirm the superiority of our DF-LLaVA, achieving both high accuracy and explainability in synthetic image detection. Code is available online at: https://github.com/Eliot-Shen/DF-LLaVA.
Brought a Gun to a Knife Fight: Modern VFM Baselines Outgun Specialized Detectors on In-the-Wild AI Image Detection
Sep 16, 2025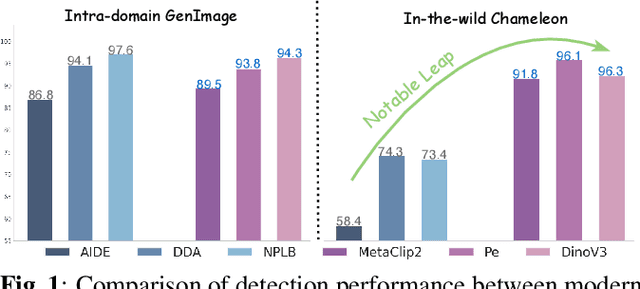
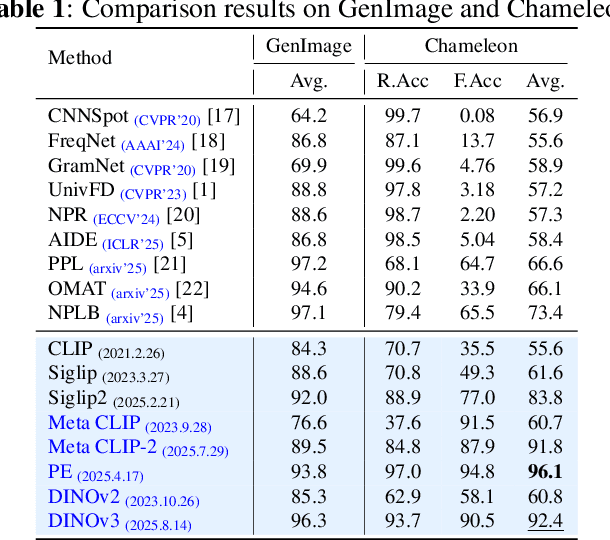
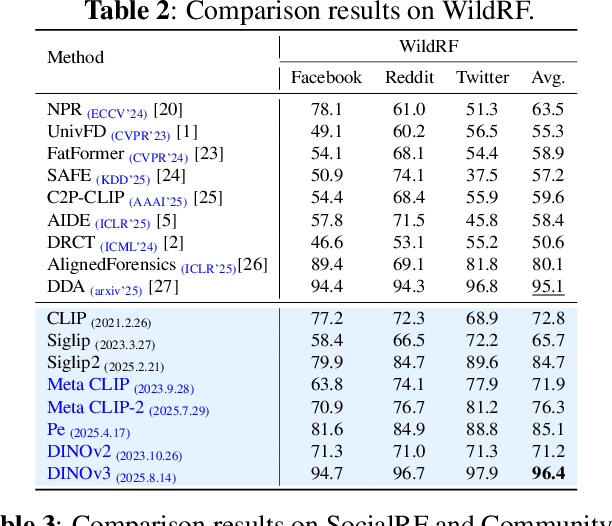
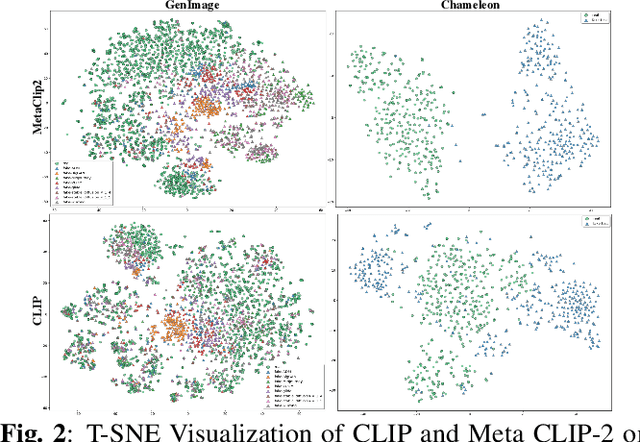
While specialized detectors for AI-generated images excel on curated benchmarks, they fail catastrophically in real-world scenarios, as evidenced by their critically high false-negative rates on `in-the-wild' benchmarks. Instead of crafting another specialized `knife' for this problem, we bring a `gun' to the fight: a simple linear classifier on a modern Vision Foundation Model (VFM). Trained on identical data, this baseline decisively `outguns' bespoke detectors, boosting in-the-wild accuracy by a striking margin of over 20\%. Our analysis pinpoints the source of the VFM's `firepower': First, by probing text-image similarities, we find that recent VLMs (e.g., Perception Encoder, Meta CLIP2) have learned to align synthetic images with forgery-related concepts (e.g., `AI-generated'), unlike previous versions. Second, we speculate that this is due to data exposure, as both this alignment and overall accuracy plummet on a novel dataset scraped after the VFM's pre-training cut-off date, ensuring it was unseen during pre-training. Our findings yield two critical conclusions: 1) For the real-world `gunfight' of AI-generated image detection, the raw `firepower' of an updated VFM is far more effective than the `craftsmanship' of a static detector. 2) True generalization evaluation requires test data to be independent of the model's entire training history, including pre-training.
Beyond Artificial Misalignment: Detecting and Grounding Semantic-Coordinated Multimodal Manipulations
Sep 16, 2025



The detection and grounding of manipulated content in multimodal data has emerged as a critical challenge in media forensics. While existing benchmarks demonstrate technical progress, they suffer from misalignment artifacts that poorly reflect real-world manipulation patterns: practical attacks typically maintain semantic consistency across modalities, whereas current datasets artificially disrupt cross-modal alignment, creating easily detectable anomalies. To bridge this gap, we pioneer the detection of semantically-coordinated manipulations where visual edits are systematically paired with semantically consistent textual descriptions. Our approach begins with constructing the first Semantic-Aligned Multimodal Manipulation (SAMM) dataset, generated through a two-stage pipeline: 1) applying state-of-the-art image manipulations, followed by 2) generation of contextually-plausible textual narratives that reinforce the visual deception. Building on this foundation, we propose a Retrieval-Augmented Manipulation Detection and Grounding (RamDG) framework. RamDG commences by harnessing external knowledge repositories to retrieve contextual evidence, which serves as the auxiliary texts and encoded together with the inputs through our image forgery grounding and deep manipulation detection modules to trace all manipulations. Extensive experiments demonstrate our framework significantly outperforms existing methods, achieving 2.06\% higher detection accuracy on SAMM compared to state-of-the-art approaches. The dataset and code are publicly available at https://github.com/shen8424/SAMM-RamDG-CAP.