 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMemory: Toward Consistent Video Generation via Memory Integration
Jan 07, 2026Maintaining consistent characters, props, and environments across multiple shots is a central challenge in narrative video generation. Existing models can produce high-quality short clips but often fail to preserve entity identity and appearance when scenes change or when entities reappear after long temporal gaps. We present VideoMemory, an entity-centric framework that integrates narrative planning with visual generation through a Dynamic Memory Bank. Given a structured script, a multi-agent system decomposes the narrative into shots, retrieves entity representations from memory, and synthesizes keyframes and videos conditioned on these retrieved states. The Dynamic Memory Bank stores explicit visual and semantic descriptors for characters, props, and backgrounds, and is updated after each shot to reflect story-driven changes while preserving identity. This retrieval-update mechanism enables consistent portrayal of entities across distant shots and supports coherent long-form generation. To evaluate this setting, we construct a 54-case multi-shot consistency benchmark covering character-, prop-, and background-persistent scenarios. Extensive experiments show that VideoMemory achieves strong entity-level coherence and high perceptual quality across diverse narrative sequences.
Multi-level Dynamic Style Transfer for NeRFs
Oct 01, 2025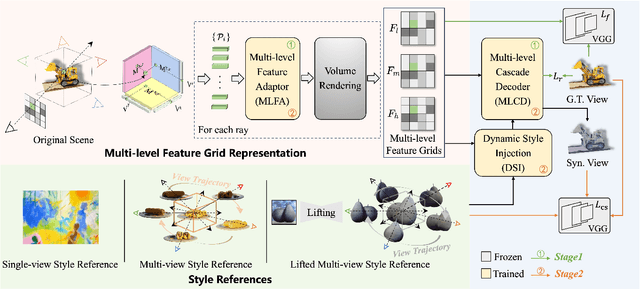
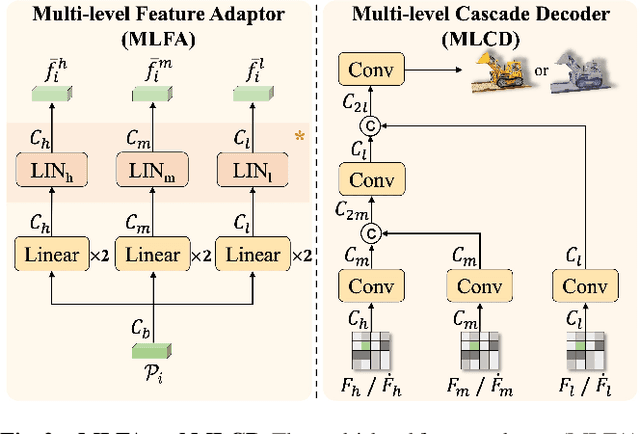

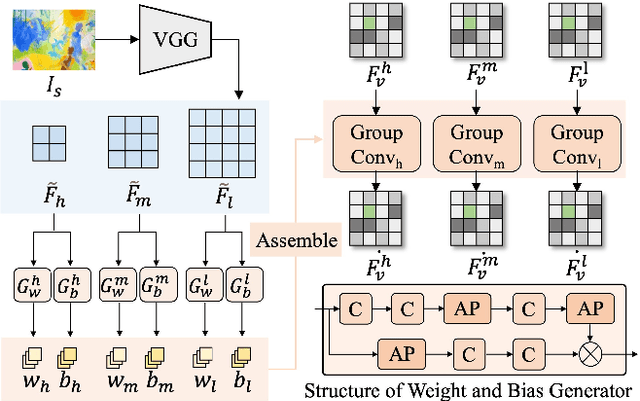
As the application of neural radiance fields (NeRFs) in various 3D vision tasks continues to expand, numerous NeRF-based style transfer techniques have been developed. However, existing methods typically integrate style statistics into the original NeRF pipeline, often leading to suboptimal results in both content preservation and artistic stylization. In this paper, we present multi-level dynamic style transfer for NeRFs (MDS-NeRF), a novel approach that reengineers the NeRF pipeline specifically for stylization and incorporates an innovative dynamic style injection module. Particularly, we propose a multi-level feature adaptor that helps generate a multi-level feature grid representation from the content radiance field, effectively capturing the multi-scale spatial structure of the scene. In addition, we present a dynamic style injection module that learns to extract relevant style features and adaptively integrates them into the content patterns. The stylized multi-level features are then transformed into the final stylized view through our proposed multi-level cascade decoder. Furthermore, we extend our 3D style transfer method to support omni-view style transfer using 3D style references. Extensive experiments demonstrate that MDS-NeRF achieves outstanding performance for 3D style transfer, preserving multi-scale spatial structures while effectively transferring stylistic characteristics.
Toward Medical Deepfake Detection: A Comprehensive Dataset and Novel Method
Sep 19, 2025The rapid advancement of generative AI in medical imaging has introduced both significant opportunities and serious challenges, especially the risk that fake medical images could undermine healthcare systems. These synthetic images pose serious risks, such as diagnostic deception, financial fraud, and misinformation. However, research on medical forensics to counter these threats remains limited, and there is a critical lack of comprehensive datasets specifically tailored for this field. Additionally, existing media forensic methods, which are primarily designed for natural or facial images, are inadequate for capturing the distinct characteristics and subtle artifacts of AI-generated medical images. To tackle these challenges, we introduce \textbf{MedForensics}, a large-scale medical forensics dataset encompassing six medical modalities and twelve state-of-the-art medical generative models. We also propose \textbf{DSKI}, a novel \textbf{D}ual-\textbf{S}tage \textbf{K}nowledge \textbf{I}nfusing detector that constructs a vision-language feature space tailored for the detection of AI-generated medical images. DSKI comprises two core components: 1) a cross-domain fine-trace adapter (CDFA) for extracting subtle forgery clues from both spatial and noise domains during training, and 2) a medical forensic retrieval module (MFRM) that boosts detection accuracy through few-shot retrieval during testing. Experimental results demonstrate that DSKI significantly outperforms both existing methods and human experts, achieving superior accuracy across multiple medical modalities.
TrueMoE: Dual-Routing Mixture of Discriminative Experts for Synthetic Image Detection
Sep 19, 2025



The rapid progress of generative models has made synthetic image detection an increasingly critical task. Most existing approaches attempt to construct a single, universal discriminative space to separate real from fake content. However, such unified spaces tend to be complex and brittle, often struggling to generalize to unseen generative patterns. In this work, we propose TrueMoE, a novel dual-routing Mixture-of-Discriminative-Experts framework that reformulates the detection task as a collaborative inference across multiple specialized and lightweight discriminative subspaces. At the core of TrueMoE is a Discriminative Expert Array (DEA) organized along complementary axes of manifold structure and perceptual granularity, enabling diverse forgery cues to be captured across subspaces. A dual-routing mechanism, comprising a granularity-aware sparse router and a manifold-aware dense router, adaptively assigns input images to the most relevant experts. Extensive experiments across a wide spectrum of generative models demonstrate that TrueMoE achieves superior generalization and robustness.
Surgery-R1: Advancing Surgical-VQLA with Reasoning Multimodal Large Language Model via Reinforcement Learning
Jun 24, 2025In recent years, significant progress has been made in the field of surgical scene understanding, particularly in the task of Visual Question Localized-Answering in robotic surgery (Surgical-VQLA). However, existing Surgical-VQLA models lack deep reasoning capabilities and interpretability in surgical scenes, which limits their reliability and potential for development in clinical applications. To address this issue, inspired by the development of Reasoning Multimodal Large Language Models (MLLMs), we first build the Surgery-R1-54k dataset, including paired data for Visual-QA, Grounding-QA, and Chain-of-Thought (CoT). Then, we propose the first Reasoning MLLM for Surgical-VQLA (Surgery-R1). In our Surgery-R1, we design a two-stage fine-tuning mechanism to enable the basic MLLM with complex reasoning abilities by utilizing supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). Furthermore, for an efficient and high-quality rule-based reward system in our RFT, we design a Multimodal Coherence reward mechanism to mitigate positional illusions that may arise in surgical scenarios. Experiment results demonstrate that Surgery-R1 outperforms other existing state-of-the-art (SOTA) models in the Surgical-VQLA task and widely-used MLLMs, while also validating its reasoning capabilities and the effectiveness of our approach. The code and dataset will be organized in https://github.com/FiFi-HAO467/Surgery-R1.