 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-CLIPSim: Multi-Layer CLIP Similarity for Machine-Oriented Image Quality
May 10, 2026We study full-reference image quality assessment from a machine-centric perspective, where images are evaluated by how well they preserve information for downstream models. We formulate machine-oriented quality as a latent machine utility and approximate it through pairwise predictive-consistency comparisons. To this end, we construct PCMP, a dataset of PSNR-matched distortion pairs labeled by consistency votes from multiple pretrained models. We further propose ML-CLIPSim, a differentiable quality metric built on a frozen CLIP visual encoder, which aggregates intermediate patch-token similarities and global image embeddings. Experiments on machine-preference benchmarks, human-IQA datasets, and learned image compression show that ML-CLIPSim better aligns with machine-oriented preferences than conventional fidelity and perceptual metrics, while remaining competitive for human quality prediction. Used as a compression distortion term, it improves rate--task trade-offs across multiple downstream tasks.
SCALE: Semantic- and Confidence-Aware Conditional Variational Autoencoder for Zero-shot Skeleton-based Action Recognition
Apr 02, 2026Zero-shot skeleton-based action recognition (ZSAR) aims to recognize action classes without any training skeletons from those classes, relying instead on auxiliary semantics from text. Existing approaches frequently depend on explicit skeleton-text alignment, which can be brittle when action names underspecify fine-grained dynamics and when unseen classes are semantically confusable. We propose SCALE, a lightweight and deterministic Semantic- and Confidence-Aware Listwise Energy-based framework that formulates ZSAR as class-conditional energy ranking. SCALE builds a text-conditioned Conditional Variational Autoencoder where frozen text representations parameterize both the latent prior and the decoder, enabling likelihood-based evaluation for unseen classes without generating samples at test time. To separate competing hypotheses, we introduce a semantic- and confidence-aware listwise energy loss that emphasizes semantically similar hard negatives and incorporates posterior uncertainty to adapt decision margins and reweight ambiguous training instances. Additionally, we utilize a latent prototype contrast objective to align posterior means with text-derived latent prototypes, improving semantic organization and class separability without direct feature matching. Experiments on NTU-60 and NTU-120 datasets show that SCALE consistently improves over prior VAE- and alignment-based baselines while remaining competitive with diffusion-based methods.
Simplicity Prevails: The Emergence of Generalizable AIGI Detection in Visual Foundation Models
Feb 02, 2026While specialized detectors for AI-Generated Images (AIGI) achieve near-perfect accuracy on curated benchmarks, they suffer from a dramatic performance collapse in realistic, in-the-wild scenarios. In this work, we demonstrate that simplicity prevails over complex architectural designs. A simple linear classifier trained on the frozen features of modern Vision Foundation Models , including Perception Encoder, MetaCLIP 2, and DINOv3, establishes a new state-of-the-art. Through a comprehensive evaluation spanning traditional benchmarks, unseen generators, and challenging in-the-wild distributions, we show that this baseline not only matches specialized detectors on standard benchmarks but also decisively outperforms them on in-the-wild datasets, boosting accuracy by striking margins of over 30\%. We posit that this superior capability is an emergent property driven by the massive scale of pre-training data containing synthetic content. We trace the source of this capability to two distinct manifestations of data exposure: Vision-Language Models internalize an explicit semantic concept of forgery, while Self-Supervised Learning models implicitly acquire discriminative forensic features from the pretraining data. However, we also reveal persistent limitations: these models suffer from performance degradation under recapture and transmission, remain blind to VAE reconstruction and localized editing. We conclude by advocating for a paradigm shift in AI forensics, moving from overfitting on static benchmarks to harnessing the evolving world knowledge of foundation models for real-world reliability.
MPF-Net: Exposing High-Fidelity AI-Generated Video Forgeries via Hierarchical Manifold Deviation and Micro-Temporal Fluctuations
Jan 29, 2026With the rapid advancement of video generation models such as Veo and Wan, the visual quality of synthetic content has reached a level where macro-level semantic errors and temporal inconsistencies are no longer prominent. However, this does not imply that the distinction between real and cutting-edge high-fidelity fake is untraceable. We argue that AI-generated videos are essentially products of a manifold-fitting process rather than a physical recording. Consequently, the pixel composition logic of consecutive adjacent frames residual in AI videos exhibits a structured and homogenous characteristic. We term this phenomenon `Manifold Projection Fluctuations' (MPF). Driven by this insight, we propose a hierarchical dual-path framework that operates as a sequential filtering process. The first, the Static Manifold Deviation Branch, leverages the refined perceptual boundaries of Large-Scale Vision Foundation Models (VFMs) to capture residual spatial anomalies or physical violations that deviate from the natural real-world manifold (off-manifold). For the remaining high-fidelity videos that successfully reside on-manifold and evade spatial detection, we introduce the Micro-Temporal Fluctuation Branch as a secondary, fine-grained filter. By analyzing the structured MPF that persists even in visually perfect sequences, our framework ensures that forgeries are exposed regardless of whether they manifest as global real-world manifold deviations or subtle computational fingerprints.
DiffFace-Edit: A Diffusion-Based Facial Dataset for Forgery-Semantic Driven Deepfake Detection Analysis
Jan 20, 2026Generative models now produce imperceptible, fine-grained manipulated faces, posing significant privacy risks. However, existing AI-generated face datasets generally lack focus on samples with fine-grained regional manipulations. Furthermore, no researchers have yet studied the real impact of splice attacks, which occur between real and manipulated samples, on detectors. We refer to these as detector-evasive samples. Based on this, we introduce the DiffFace-Edit dataset, which has the following advantages: 1) It contains over two million AI-generated fake images. 2) It features edits across eight facial regions (e.g., eyes, nose) and includes a richer variety of editing combinations, such as single-region and multi-region edits. Additionally, we specifically analyze the impact of detector-evasive samples on detection models. We conduct a comprehensive analysis of the dataset and propose a cross-domain evaluation that combines IMDL methods. Dataset will be available at https://github.com/ywh1093/DiffFace-Edit.
Artificial Intelligence-Enabled Holistic Design of Catalysts Tailored for Semiconducting Carbon Nanotube Growth
Dec 18, 2025



Catalyst design is crucial for materials synthesis, especially for complex reaction networks. Strategies like collaborative catalytic systems and multifunctional catalysts are effective but face challenges at the nanoscale. Carbon nanotube synthesis contains complicated nanoscale catalytic reactions, thus achieving high-density, high-quality semiconducting CNTs demands innovative catalyst design. In this work, we present a holistic framework integrating machine learning into traditional catalyst design for semiconducting CNT synthesis. It combines knowledge-based insights with data-driven techniques. Three key components, including open-access electronic structure databases for precise physicochemical descriptors, pre-trained natural language processing-based embedding model for higher-level abstractions, and physical - driven predictive models based on experiment data, are utilized. Through this framework, a new method for selective semiconducting CNT synthesis via catalyst - mediated electron injection, tuned by light during growth, is proposed. 54 candidate catalysts are screened, and three with high potential are identified. High-throughput experiments validate the predictions, with semiconducting selectivity exceeding 91% and the FeTiO3 catalyst reaching 98.6%. This approach not only addresses semiconducting CNT synthesis but also offers a generalizable methodology for global catalyst design and nanomaterials synthesis, advancing materials science in precise control.
Fairness-Aware Deepfake Detection: Leveraging Dual-Mechanism Optimization
Nov 19, 2025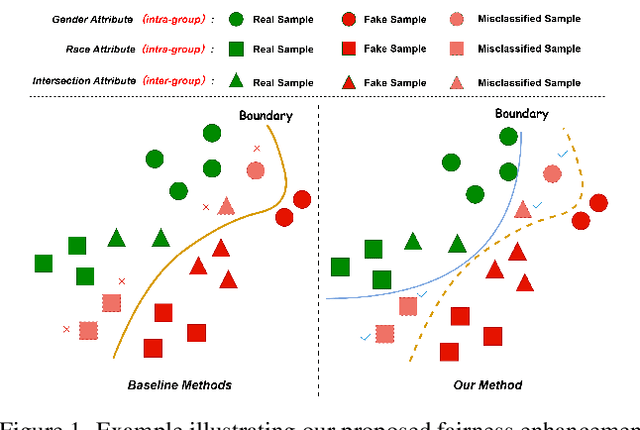
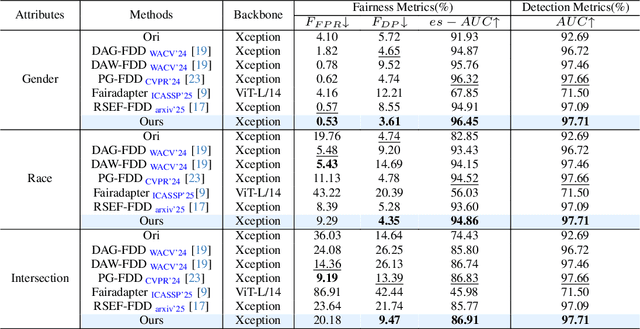
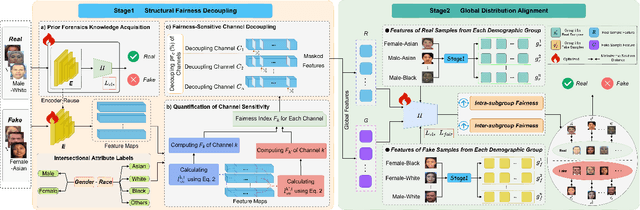
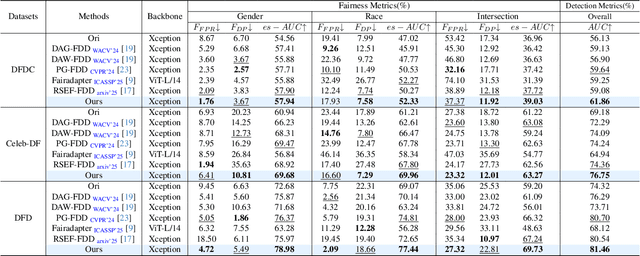
Fairness is a core element in the trustworthy deployment of deepfake detection models, especially in the field of digital identity security. Biases in detection models toward different demographic groups, such as gender and race, may lead to systemic misjudgments, exacerbating the digital divide and social inequities. However, current fairness-enhanced detectors often improve fairness at the cost of detection accuracy. To address this challenge, we propose a dual-mechanism collaborative optimization framework. Our proposed method innovatively integrates structural fairness decoupling and global distribution alignment: decoupling channels sensitive to demographic groups at the model architectural level, and subsequently reducing the distance between the overall sample distribution and the distributions corresponding to each demographic group at the feature level. Experimental results demonstrate that, compared with other methods, our framework improves both inter-group and intra-group fairness while maintaining overall detection accuracy across domains.
LSTC-MDA: A Unified Framework for Long-Short Term Temporal Convolution and Mixed Data Augmentation in Skeleton-Based Action Recognition
Sep 18, 2025Skeleton-based action recognition faces two longstanding challenges: the scarcity of labeled training samples and difficulty modeling short- and long-range temporal dependencies. To address these issues, we propose a unified framework, LSTC-MDA, which simultaneously improves temporal modeling and data diversity. We introduce a novel Long-Short Term Temporal Convolution (LSTC) module with parallel short- and long-term branches, these two feature branches are then aligned and fused adaptively using learned similarity weights to preserve critical long-range cues lost by conventional stride-2 temporal convolutions. We also extend Joint Mixing Data Augmentation (JMDA) with an Additive Mixup at the input level, diversifying training samples and restricting mixup operations to the same camera view to avoid distribution shifts. Ablation studies confirm each component contributes. LSTC-MDA achieves state-of-the-art results: 94.1% and 97.5% on NTU 60 (X-Sub and X-View), 90.4% and 92.0% on NTU 120 (X-Sub and X-Set),97.2% on NW-UCLA. Code: https://github.com/xiaobaoxia/LSTC-MDA.
Brought a Gun to a Knife Fight: Modern VFM Baselines Outgun Specialized Detectors on In-the-Wild AI Image Detection
Sep 16, 2025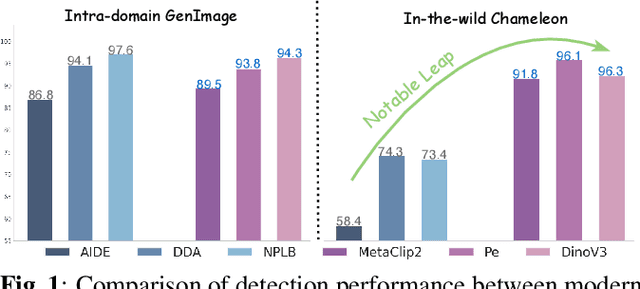
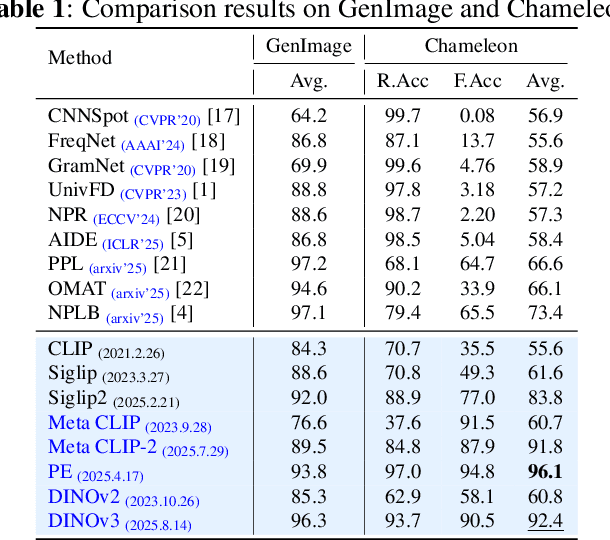
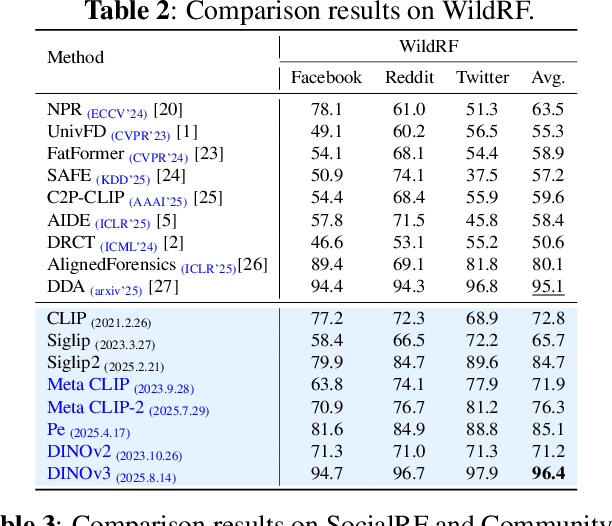
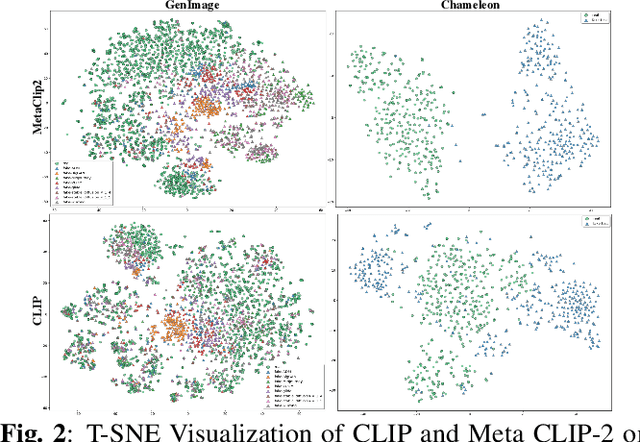
While specialized detectors for AI-generated images excel on curated benchmarks, they fail catastrophically in real-world scenarios, as evidenced by their critically high false-negative rates on `in-the-wild' benchmarks. Instead of crafting another specialized `knife' for this problem, we bring a `gun' to the fight: a simple linear classifier on a modern Vision Foundation Model (VFM). Trained on identical data, this baseline decisively `outguns' bespoke detectors, boosting in-the-wild accuracy by a striking margin of over 20\%. Our analysis pinpoints the source of the VFM's `firepower': First, by probing text-image similarities, we find that recent VLMs (e.g., Perception Encoder, Meta CLIP2) have learned to align synthetic images with forgery-related concepts (e.g., `AI-generated'), unlike previous versions. Second, we speculate that this is due to data exposure, as both this alignment and overall accuracy plummet on a novel dataset scraped after the VFM's pre-training cut-off date, ensuring it was unseen during pre-training. Our findings yield two critical conclusions: 1) For the real-world `gunfight' of AI-generated image detection, the raw `firepower' of an updated VFM is far more effective than the `craftsmanship' of a static detector. 2) True generalization evaluation requires test data to be independent of the model's entire training history, including pre-training.
HALO: Half Life-Based Outdated Fact Filtering in Temporal Knowledge Graphs
May 12, 2025Outdated facts in temporal knowledge graphs (TKGs) result from exceeding the expiration date of facts, which negatively impact reasoning performance on TKGs. However, existing reasoning methods primarily focus on positive importance of historical facts, neglecting adverse effects of outdated facts. Besides, training on these outdated facts yields extra computational cost. To address these challenges, we propose an outdated fact filtering framework named HALO, which quantifies the temporal validity of historical facts by exploring the half-life theory to filter outdated facts in TKGs. HALO consists of three modules: the temporal fact attention module, the dynamic relation-aware encoder module, and the outdated fact filtering module. Firstly, the temporal fact attention module captures the evolution of historical facts over time to identify relevant facts. Secondly, the dynamic relation-aware encoder module is designed for efficiently predicting the half life of each fact. Finally, we construct a time decay function based on the half-life theory to quantify the temporal validity of facts and filter outdated facts. Experimental results show that HALO outperforms the state-of-the-art TKG reasoning methods on three public datasets, demonstrating its effectiveness in detecting and filtering outdated facts (Codes are available at https://github.com/yushuowiki/K-Half/tree/main ).