 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition In Videos
Action recognition in videos is the process of identifying and categorizing human actions or activities in video sequences.
Papers and Code
STSBench: A Spatio-temporal Scenario Benchmark for Multi-modal Large Language Models in Autonomous Driving
Jun 06, 2025



We introduce STSBench, a scenario-based framework to benchmark the holistic understanding of vision-language models (VLMs) for autonomous driving. The framework automatically mines pre-defined traffic scenarios from any dataset using ground-truth annotations, provides an intuitive user interface for efficient human verification, and generates multiple-choice questions for model evaluation. Applied to the NuScenes dataset, we present STSnu, the first benchmark that evaluates the spatio-temporal reasoning capabilities of VLMs based on comprehensive 3D perception. Existing benchmarks typically target off-the-shelf or fine-tuned VLMs for images or videos from a single viewpoint and focus on semantic tasks such as object recognition, dense captioning, risk assessment, or scene understanding. In contrast, STSnu evaluates driving expert VLMs for end-to-end driving, operating on videos from multi-view cameras or LiDAR. It specifically assesses their ability to reason about both ego-vehicle actions and complex interactions among traffic participants, a crucial capability for autonomous vehicles. The benchmark features 43 diverse scenarios spanning multiple views and frames, resulting in 971 human-verified multiple-choice questions. A thorough evaluation uncovers critical shortcomings in existing models' ability to reason about fundamental traffic dynamics in complex environments. These findings highlight the urgent need for architectural advances that explicitly model spatio-temporal reasoning. By addressing a core gap in spatio-temporal evaluation, STSBench enables the development of more robust and explainable VLMs for autonomous driving.
BEAR: A Video Dataset For Fine-grained Behaviors Recognition Oriented with Action and Environment Factors
Mar 26, 2025Behavior recognition is an important task in video representation learning. An essential aspect pertains to effective feature learning conducive to behavior recognition. Recently, researchers have started to study fine-grained behavior recognition, which provides similar behaviors and encourages the model to concern with more details of behaviors with effective features for distinction. However, previous fine-grained behaviors limited themselves to controlling partial information to be similar, leading to an unfair and not comprehensive evaluation of existing works. In this work, we develop a new video fine-grained behavior dataset, named BEAR, which provides fine-grained (i.e. similar) behaviors that uniquely focus on two primary factors defining behavior: Environment and Action. It includes two fine-grained behavior protocols including Fine-grained Behavior with Similar Environments and Fine-grained Behavior with Similar Actions as well as multiple sub-protocols as different scenarios. Furthermore, with this new dataset, we conduct multiple experiments with different behavior recognition models. Our research primarily explores the impact of input modality, a critical element in studying the environmental and action-based aspects of behavior recognition. Our experimental results yield intriguing insights that have substantial implications for further research endeavors.
3DPyranet Features Fusion for Spatio-temporal Feature Learning
Apr 26, 2025Convolutional neural network (CNN) slides a kernel over the whole image to produce an output map. This kernel scheme reduces the number of parameters with respect to a fully connected neural network (NN). While CNN has proven to be an effective model in recognition of handwritten characters and traffic signal sign boards, etc. recently, its deep variants have proven to be effective in similar as well as more challenging applications like object, scene and action recognition. Deep CNN add more layers and kernels to the classical CNN, increasing the number of parameters, and partly reducing the main advantage of CNN which is less parameters. In this paper, a 3D pyramidal neural network called 3DPyraNet and a discriminative approach for spatio-temporal feature learning based on it, called 3DPyraNet-F, are proposed. 3DPyraNet introduces a new weighting scheme which learns features from both spatial and temporal dimensions analyzing multiple adjacent frames and keeping a biological plausible structure. It keeps the spatial topology of the input image and presents fewer parameters and lower computational and memory costs compared to both fully connected NNs and recent deep CNNs. 3DPyraNet-F extract the features maps of the highest layer of the learned network, fuse them in a single vector, and provide it as input in such a way to a linear-SVM classifier that enhances the recognition of human actions and dynamic scenes from the videos. Encouraging results are reported with 3DPyraNet in real-world environments, especially in the presence of camera induced motion. Further, 3DPyraNet-F clearly outperforms the state-of-the-art on three benchmark datasets and shows comparable result for the fourth.
Temporal Consistency Constrained Transferable Adversarial Attacks with Background Mixup for Action Recognition
May 23, 2025Action recognition models using deep learning are vulnerable to adversarial examples, which are transferable across other models trained on the same data modality. Existing transferable attack methods face two major challenges: 1) they heavily rely on the assumption that the decision boundaries of the surrogate (a.k.a., source) model and the target model are similar, which limits the adversarial transferability; and 2) their decision boundary difference makes the attack direction uncertain, which may result in the gradient oscillation, weakening the adversarial attack. This motivates us to propose a Background Mixup-induced Temporal Consistency (BMTC) attack method for action recognition. From the input transformation perspective, we design a model-agnostic background adversarial mixup module to reduce the surrogate-target model dependency. In particular, we randomly sample one video from each category and make its background frame, while selecting the background frame with the top attack ability for mixup with the clean frame by reinforcement learning. Moreover, to ensure an explicit attack direction, we leverage the background category as guidance for updating the gradient of adversarial example, and design a temporal gradient consistency loss, which strengthens the stability of the attack direction on subsequent frames. Empirical studies on two video datasets, i.e., UCF101 and Kinetics-400, and one image dataset, i.e., ImageNet, demonstrate that our method significantly boosts the transferability of adversarial examples across several action/image recognition models. Our code is available at https://github.com/mlvccn/BMTC_TransferAttackVid.
Knowledge Distillation for Multimodal Egocentric Action Recognition Robust to Missing Modalities
Apr 11, 2025Action recognition is an essential task in egocentric vision due to its wide range of applications across many fields. While deep learning methods have been proposed to address this task, most rely on a single modality, typically video. However, including additional modalities may improve the robustness of the approaches to common issues in egocentric videos, such as blurriness and occlusions. Recent efforts in multimodal egocentric action recognition often assume the availability of all modalities, leading to failures or performance drops when any modality is missing. To address this, we introduce an efficient multimodal knowledge distillation approach for egocentric action recognition that is robust to missing modalities (KARMMA) while still benefiting when multiple modalities are available. Our method focuses on resource-efficient development by leveraging pre-trained models as unimodal feature extractors in our teacher model, which distills knowledge into a much smaller and faster student model. Experiments on the Epic-Kitchens and Something-Something datasets demonstrate that our student model effectively handles missing modalities while reducing its accuracy drop in this scenario.
DPFlow: Adaptive Optical Flow Estimation with a Dual-Pyramid Framework
Mar 19, 2025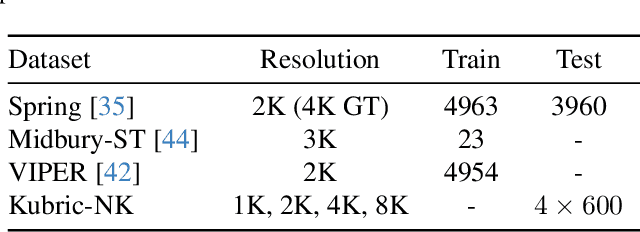
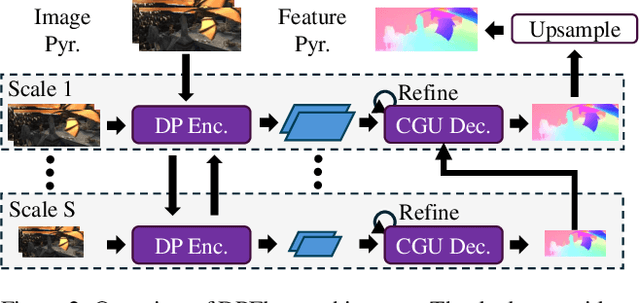
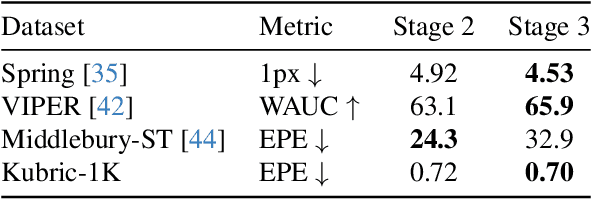
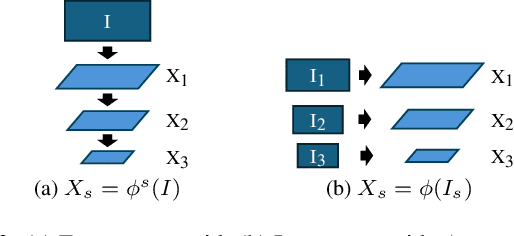
Optical flow estimation is essential for video processing tasks, such as restoration and action recognition. The quality of videos is constantly increasing, with current standards reaching 8K resolution. However, optical flow methods are usually designed for low resolution and do not generalize to large inputs due to their rigid architectures. They adopt downscaling or input tiling to reduce the input size, causing a loss of details and global information. There is also a lack of optical flow benchmarks to judge the actual performance of existing methods on high-resolution samples. Previous works only conducted qualitative high-resolution evaluations on hand-picked samples. This paper fills this gap in optical flow estimation in two ways. We propose DPFlow, an adaptive optical flow architecture capable of generalizing up to 8K resolution inputs while trained with only low-resolution samples. We also introduce Kubric-NK, a new benchmark for evaluating optical flow methods with input resolutions ranging from 1K to 8K. Our high-resolution evaluation pushes the boundaries of existing methods and reveals new insights about their generalization capabilities. Extensive experimental results show that DPFlow achieves state-of-the-art results on the MPI-Sintel, KITTI 2015, Spring, and other high-resolution benchmarks.
Balancing Privacy and Action Performance: A Penalty-Driven Approach to Image Anonymization
Apr 19, 2025



The rapid development of video surveillance systems for object detection, tracking, activity recognition, and anomaly detection has revolutionized our day-to-day lives while setting alarms for privacy concerns. It isn't easy to strike a balance between visual privacy and action recognition performance in most computer vision models. Is it possible to safeguard privacy without sacrificing performance? It poses a formidable challenge, as even minor privacy enhancements can lead to substantial performance degradation. To address this challenge, we propose a privacy-preserving image anonymization technique that optimizes the anonymizer using penalties from the utility branch, ensuring improved action recognition performance while minimally affecting privacy leakage. This approach addresses the trade-off between minimizing privacy leakage and maintaining high action performance. The proposed approach is primarily designed to align with the regulatory standards of the EU AI Act and GDPR, ensuring the protection of personally identifiable information while maintaining action performance. To the best of our knowledge, we are the first to introduce a feature-based penalty scheme that exclusively controls the action features, allowing freedom to anonymize private attributes. Extensive experiments were conducted to validate the effectiveness of the proposed method. The results demonstrate that applying a penalty to anonymizer from utility branch enhances action performance while maintaining nearly consistent privacy leakage across different penalty settings.
MultiTSF: Transformer-based Sensor Fusion for Human-Centric Multi-view and Multi-modal Action Recognition
Apr 03, 2025



Action recognition from multi-modal and multi-view observations holds significant potential for applications in surveillance, robotics, and smart environments. However, existing methods often fall short of addressing real-world challenges such as diverse environmental conditions, strict sensor synchronization, and the need for fine-grained annotations. In this study, we propose the Multi-modal Multi-view Transformer-based Sensor Fusion (MultiTSF). The proposed method leverages a Transformer-based to dynamically model inter-view relationships and capture temporal dependencies across multiple views. Additionally, we introduce a Human Detection Module to generate pseudo-ground-truth labels, enabling the model to prioritize frames containing human activity and enhance spatial feature learning. Comprehensive experiments conducted on our in-house MultiSensor-Home dataset and the existing MM-Office dataset demonstrate that MultiTSF outperforms state-of-the-art methods in both video sequence-level and frame-level action recognition settings.
POET: Prompt Offset Tuning for Continual Human Action Adaptation
Apr 25, 2025As extended reality (XR) is redefining how users interact with computing devices, research in human action recognition is gaining prominence. Typically, models deployed on immersive computing devices are static and limited to their default set of classes. The goal of our research is to provide users and developers with the capability to personalize their experience by adding new action classes to their device models continually. Importantly, a user should be able to add new classes in a low-shot and efficient manner, while this process should not require storing or replaying any of user's sensitive training data. We formalize this problem as privacy-aware few-shot continual action recognition. Towards this end, we propose POET: Prompt-Offset Tuning. While existing prompt tuning approaches have shown great promise for continual learning of image, text, and video modalities; they demand access to extensively pretrained transformers. Breaking away from this assumption, POET demonstrates the efficacy of prompt tuning a significantly lightweight backbone, pretrained exclusively on the base class data. We propose a novel spatio-temporal learnable prompt offset tuning approach, and are the first to apply such prompt tuning to Graph Neural Networks. We contribute two new benchmarks for our new problem setting in human action recognition: (i) NTU RGB+D dataset for activity recognition, and (ii) SHREC-2017 dataset for hand gesture recognition. We find that POET consistently outperforms comprehensive benchmarks. Source code at https://github.com/humansensinglab/POET-continual-action-recognition.
* ECCV 2024 (Oral), webpage https://humansensinglab.github.io/POET-continual-action-recognition/
MD-BERT: Action Recognition in Dark Videos via Dynamic Multi-Stream Fusion and Temporal Modeling
Feb 06, 2025



Action recognition in dark, low-light (under-exposed) or noisy videos is a challenging task due to visibility degradation, which can hinder critical spatiotemporal details. This paper proposes MD-BERT, a novel multi-stream approach that integrates complementary pre-processing techniques such as gamma correction and histogram equalization alongside raw dark frames to address these challenges. We introduce the Dynamic Feature Fusion (DFF) module, extending existing attentional fusion methods to a three-stream setting, thereby capturing fine-grained and global contextual information across different brightness and contrast enhancements. The fused spatiotemporal features are then processed by a BERT-based temporal model, which leverages its bidirectional self-attention to effectively capture long-range dependencies and contextual relationships across frames. Extensive experiments on the ARID V1.0 and ARID V1.5 dark video datasets show that MD-BERT outperforms existing methods, establishing a new state-of-the-art performance. Ablation studies further highlight the individual contributions of each input stream and the effectiveness of the proposed DFF and BERT modules. The official website of this work is available at: https://github.com/HrishavBakulBarua/DarkBERT