 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation of Task Goal States from Prior Knowledge
Feb 06, 2025This paper presents a framework to define a task with freedom and variability in its goal state. A robot could use this to observe the execution of a task and target a different goal from the observed one; a goal that is still compatible with the task description but would be easier for the robot to execute. We define the model of an environment state and an environment variation, and present experiments on how to interactively create the variation from a single task demonstration and how to use this variation to create an execution plan for bringing any environment into the goal state.
Understanding Spatio-Temporal Relations in Human-Object Interaction using Pyramid Graph Convolutional Network
Oct 10, 2024



Human activities recognition is an important task for an intelligent robot, especially in the field of human-robot collaboration, it requires not only the label of sub-activities but also the temporal structure of the activity. In order to automatically recognize both the label and the temporal structure in sequence of human-object interaction, we propose a novel Pyramid Graph Convolutional Network (PGCN), which employs a pyramidal encoder-decoder architecture consisting of an attention based graph convolution network and a temporal pyramid pooling module for downsampling and upsampling interaction sequence on the temporal axis, respectively. The system represents the 2D or 3D spatial relation of human and objects from the detection results in video data as a graph. To learn the human-object relations, a new attention graph convolutional network is trained to extract condensed information from the graph representation. To segment action into sub-actions, a novel temporal pyramid pooling module is proposed, which upsamples compressed features back to the original time scale and classifies actions per frame. We explore various attention layers, namely spatial attention, temporal attention and channel attention, and combine different upsampling decoders to test the performance on action recognition and segmentation. We evaluate our model on two challenging datasets in the field of human-object interaction recognition, i.e. Bimanual Actions and IKEA Assembly datasets. We demonstrate that our classifier significantly improves both framewise action recognition and segmentation, e.g., F1 micro and F1@50 scores on Bimanual Actions dataset are improved by $4.3\%$ and $8.5\%$ respectively.
Understanding Human Activity with Uncertainty Measure for Novelty in Graph Convolutional Networks
Oct 10, 2024



Understanding human activity is a crucial aspect of developing intelligent robots, particularly in the domain of human-robot collaboration. Nevertheless, existing systems encounter challenges such as over-segmentation, attributed to errors in the up-sampling process of the decoder. In response, we introduce a promising solution: the Temporal Fusion Graph Convolutional Network. This innovative approach aims to rectify the inadequate boundary estimation of individual actions within an activity stream and mitigate the issue of over-segmentation in the temporal dimension. Moreover, systems leveraging human activity recognition frameworks for decision-making necessitate more than just the identification of actions. They require a confidence value indicative of the certainty regarding the correspondence between observations and training examples. This is crucial to prevent overly confident responses to unforeseen scenarios that were not part of the training data and may have resulted in mismatches due to weak similarity measures within the system. To address this, we propose the incorporation of a Spectral Normalized Residual connection aimed at enhancing efficient estimation of novelty in observations. This innovative approach ensures the preservation of input distance within the feature space by imposing constraints on the maximum gradients of weight updates. By limiting these gradients, we promote a more robust handling of novel situations, thereby mitigating the risks associated with overconfidence. Our methodology involves the use of a Gaussian process to quantify the distance in feature space.
Using The Concept Hierarchy for Household Action Recognition
Sep 13, 2024

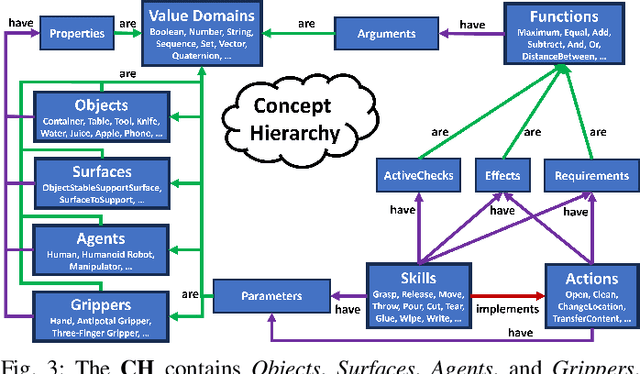

We propose a method to systematically represent both the static and the dynamic components of environments, i.e. objects and agents, as well as the changes that are happening in the environment, i.e. the actions and skills performed by agents. Our approach, the Concept Hierarchy, provides the necessary information for autonomous systems to represent environment states, perform action modeling and recognition, and plan the execution of tasks. Additionally, the hierarchical structure supports generalization and knowledge transfer to environments. We rigorously define tasks, actions, skills, and affordances that enable human-understandable action and skill recognition.
Learning a Shape-Conditioned Agent for Purely Tactile In-Hand Manipulation of Various Objects
Jul 26, 2024Reorienting diverse objects with a multi-fingered hand is a challenging task. Current methods in robotic in-hand manipulation are either object-specific or require permanent supervision of the object state from visual sensors. This is far from human capabilities and from what is needed in real-world applications. In this work, we address this gap by training shape-conditioned agents to reorient diverse objects in hand, relying purely on tactile feedback (via torque and position measurements of the fingers' joints). To achieve this, we propose a learning framework that exploits shape information in a reinforcement learning policy and a learned state estimator. We find that representing 3D shapes by vectors from a fixed set of basis points to the shape's surface, transformed by its predicted 3D pose, is especially helpful for learning dexterous in-hand manipulation. In simulation and real-world experiments, we show the reorientation of many objects with high success rates, on par with state-of-the-art results obtained with specialized single-object agents. Moreover, we show generalization to novel objects, achieving success rates of $\sim$90% even for non-convex shapes.
Speeding Up Optimization-based Motion Planning through Deep Learning
Nov 14, 2023



Planning collision-free motions for robots with many degrees of freedom is challenging in environments with complex obstacle geometries. Recent work introduced the idea of speeding up the planning by encoding prior experience of successful motion plans in a neural network. However, this "neural motion planning" did not scale to complex robots in unseen 3D environments as needed for real-world applications. Here, we introduce "basis point set", well-known in computer vision, to neural motion planning as a modern compact environment encoding enabling efficient supervised training networks that generalize well over diverse 3D worlds. Combined with a new elaborate training scheme, we reach a planning success rate of 100%. We use the network to predict an educated initial guess for an optimization-based planner (OMP), which quickly converges to a feasible solution, massively outperforming random multi-starts when tested on previously unseen environments. For the DLR humanoid Agile Justin with 19DoF and in challenging obstacle environments, optimal paths can be generated in 200ms using only a single CPU core. We also show a first successful real-world experiment based on a high-resolution world model from an integrated 3D sensor.
Self-Contained Calibration of an Elastic Humanoid Upper Body Using Only a Head-Mounted RGB Camera
Nov 14, 2023



When a humanoid robot performs a manipulation task, it first makes a model of the world using its visual sensors and then plans the motion of its body in this model. For this, precise calibration of the camera parameters and the kinematic tree is needed. Besides the accuracy of the calibrated model, the calibration process should be fast and self-contained, i.e., no external measurement equipment should be used. Therefore, we extend our prior work on calibrating the elastic upper body of DLR's Agile Justin by now using only its internal head-mounted RGB camera. We use simple visual markers at the ends of the kinematic chain and one in front of the robot, mounted on a pole, to get measurements for the whole kinematic tree. To ensure that the task-relevant cartesian error at the end-effectors is minimized, we introduce virtual noise to fit our imperfect robot model so that the pixel error has a higher weight if the marker is further away from the camera. This correction reduces the cartesian error by more than 20%, resulting in a final accuracy of 3.9mm on average and 9.1mm in the worst case. This way, we achieve the same precision as in our previous work, where an external cartesian tracking system was used.
Joint Prediction of Monocular Depth and Structure using Planar and Parallax Geometry
Jul 13, 2022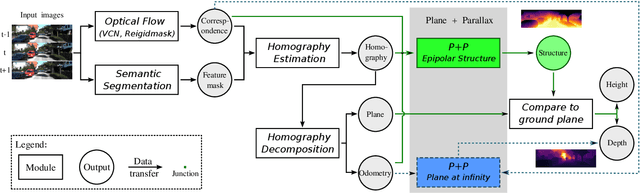
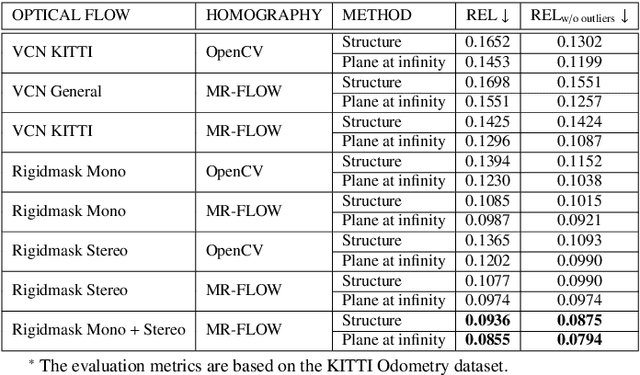
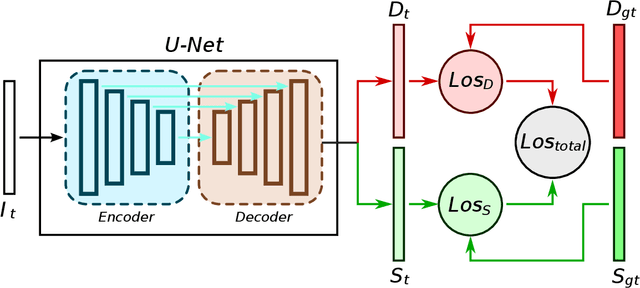
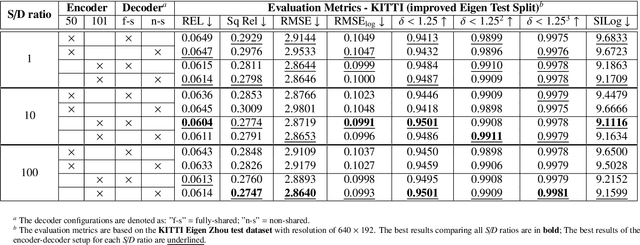
Supervised learning depth estimation methods can achieve good performance when trained on high-quality ground-truth, like LiDAR data. However, LiDAR can only generate sparse 3D maps which causes losing information. Obtaining high-quality ground-truth depth data per pixel is difficult to acquire. In order to overcome this limitation, we propose a novel approach combining structure information from a promising Plane and Parallax geometry pipeline with depth information into a U-Net supervised learning network, which results in quantitative and qualitative improvement compared to existing popular learning-based methods. In particular, the model is evaluated on two large-scale and challenging datasets: KITTI Vision Benchmark and Cityscapes dataset and achieve the best performance in terms of relative error. Compared with pure depth supervision models, our model has impressive performance on depth prediction of thin objects and edges, and compared to structure prediction baseline, our model performs more robustly.
Skeletal Human Action Recognition using Hybrid Attention based Graph Convolutional Network
Jul 12, 2022In skeleton-based action recognition, Graph Convolutional Networks model human skeletal joints as vertices and connect them through an adjacency matrix, which can be seen as a local attention mask. However, in most existing Graph Convolutional Networks, the local attention mask is defined based on natural connections of human skeleton joints and ignores the dynamic relations for example between head, hands and feet joints. In addition, the attention mechanism has been proven effective in Natural Language Processing and image description, which is rarely investigated in existing methods. In this work, we proposed a new adaptive spatial attention layer that extends local attention map to global based on relative distance and relative angle information. Moreover, we design a new initial graph adjacency matrix that connects head, hands and feet, which shows visible improvement in terms of action recognition accuracy. The proposed model is evaluated on two large-scale and challenging datasets in the field of human activities in daily life: NTU-RGB+D and Kinetics skeleton. The results demonstrate that our model has strong performance on both dataset.
Robust Event Detection based on Spatio-Temporal Latent Action Unit using Skeletal Information
Oct 01, 2021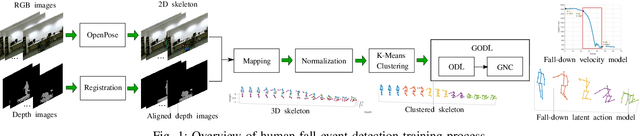
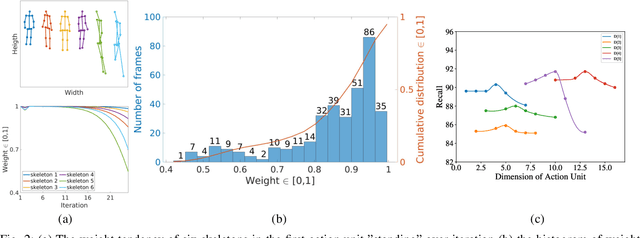
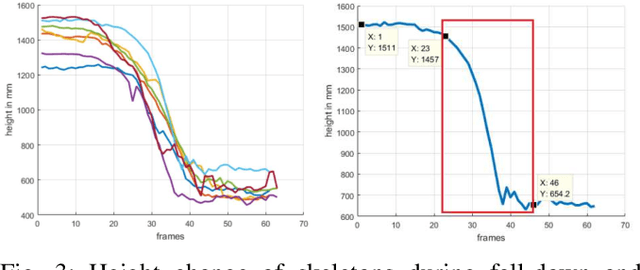
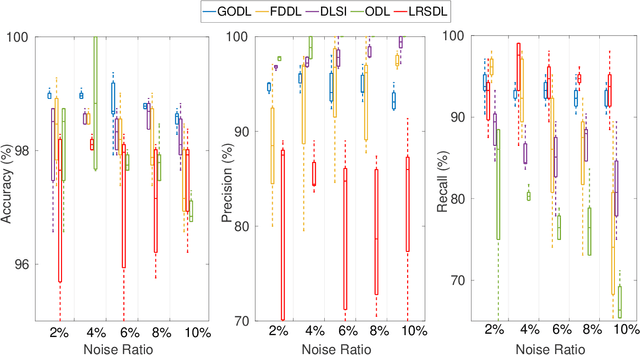
This paper propose a novel dictionary learning approach to detect event action using skeletal information extracted from RGBD video. The event action is represented as several latent atoms and composed of latent spatial and temporal attributes. We perform the method at the example of fall event detection. The skeleton frames are clustered by an initial K-means method. Each skeleton frame is assigned with a varying weight parameter and fed into our Gradual Online Dictionary Learning (GODL) algorithm. During the training process, outlier frames will be gradually filtered by reducing the weight that is inversely proportional to a cost. In order to strictly distinguish the event action from similar actions and robustly acquire its action unit, we build a latent unit temporal structure for each sub-action. We evaluate the proposed method on parts of the NTURGB+D dataset, which includes 209 fall videos, 405 ground-lift videos, 420 sit-down videos, and 280 videos of 46 otheractions. We present the experimental validation of the achieved accuracy, recall and precision. Our approach achieves the bestperformance on precision and accuracy of human fall event detection, compared with other existing dictionary learning methods. With increasing noise ratio, our method remains the highest accuracy and the lowest variance.