 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a General Intelligence and Interface for Wearable Health Data
May 21, 2026While ubiquitous wearable sensors capture a wealth of behavioral and physiological information, effectively transforming these signals into personalized health insights is challenging. Specifically, converting low-level sensor data into representations capable of characterizing higher-level states is difficult due to high phenotypic diversity and variation in individual baseline health, physiology, and lifestyle factors. Moreover, collecting wearable data paired with health outcome annotations is laborious and expensive, and retrospective annotation remains practically unfeasible, contributing to a scarcity of data with high-quality labels. To overcome these limitations, we propose a foundation model for wearable health that is pretrained on more than one trillion minutes of unlabeled sensor signals drawn from a large cohort of five million participants. We demonstrate that the joint scaling of model capacity and pretraining data volume leads to systematic improvements in performance, as evaluated on a diverse set of 35 health prediction tasks, spanning cardiovascular, metabolic, sleep, and mental health, as well as lifestyle choices and demographic factors. We find that this population scale representation unlocks label-efficient few-shot learning and generative capabilities for robust daily metric estimation. To further leverage this learned representation, we deploy a classroom of LLM agents to autonomously search the space of downstream predictive heads built on the model embeddings, showing broad performance improvements that increase with LLM model capacity. Finally, we show how integrating these downstream predictors into a Personal Health Agent can support model responses that are more relevant, contextually aware, and safe, and we validate this via 1,860 ratings from a cohort of clinicians.
SymptomAI: Towards a Conversational AI Agent for Everyday Symptom Assessment
May 05, 2026Language models excel at diagnostic assessments on currated medical case-studies and vignettes, performing on par with, or better than, clinical professionals. However, existing studies focus on complex scenarios with rich context making it difficult to draw conclusions about how these systems perform for patients reporting symptoms in everyday life. We deployed SymptomAI, a set of conversational AI agents for end-to-end patient interviewing and differential diagnosis (DDx), via the Fitbit app in a study that randomized participants (N=13,917) to interact with five AI agents. This corpus captures diverse communication and a realistic distribution of illnesses from a real world population. A subset of 1,228 participants reported a clinician-provided diagnosis, and 517 of these were further evaluated by a panel of clinicians during over 250 hours of annotation. SymptomAI DDx were significantly more accurate (OR = 2.47, p < 0.001) than those from independent clinicians given the same dialogue in a blinded randomized comparison. Moreover, agentic strategies which conduct a dedicated symptom interview that elicit additional symptom information before providing a diagnosis, perform substantially better than baseline, user-guided conversations (p < 0.001). An auxiliary analysis on 1,509 conversations from a general US population panel validated that these results generalize beyond wearable device users. We used SymptomAI diagnoses as labels for all 13,917 participants to analyze over 500,000 days of wearable metrics across nearly 400 unique conditions. We identified strong associations between acute infections and physiological shifts (e.g., OR > 7 for influenza). While limited by self-reported ground truth, these results demonstrate the benefits of a dedicated and complete symptom interview compared to a user-guided symptom discussion, which is the default of most consumer LLMs.
SnappyMeal: Design and Longitudinal Evaluation of a Multimodal AI Food Logging Application
Nov 05, 2025Food logging, both self-directed and prescribed, plays a critical role in uncovering correlations between diet, medical, fitness, and health outcomes. Through conversations with nutritional experts and individuals who practice dietary tracking, we find current logging methods, such as handwritten and app-based journaling, are inflexible and result in low adherence and potentially inaccurate nutritional summaries. These findings, corroborated by prior literature, emphasize the urgent need for improved food logging methods. In response, we propose SnappyMeal, an AI-powered dietary tracking system that leverages multimodal inputs to enable users to more flexibly log their food intake. SnappyMeal introduces goal-dependent follow-up questions to intelligently seek missing context from the user and information retrieval from user grocery receipts and nutritional databases to improve accuracy. We evaluate SnappyMeal through publicly available nutrition benchmarks and a multi-user, 3-week, in-the-wild deployment capturing over 500 logged food instances. Users strongly praised the multiple available input methods and reported a strong perceived accuracy. These insights suggest that multimodal AI systems can be leveraged to significantly improve dietary tracking flexibility and context-awareness, laying the groundwork for a new class of intelligent self-tracking applications.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025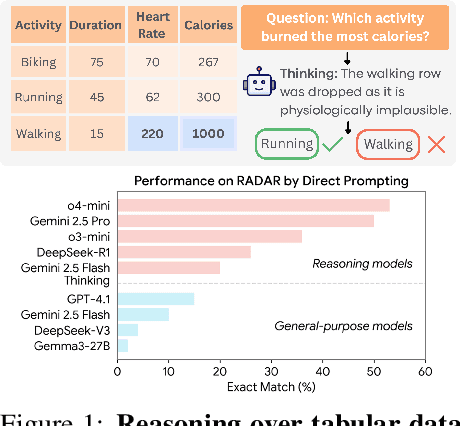
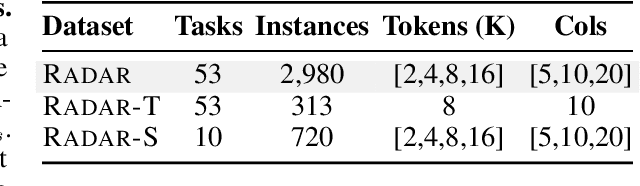
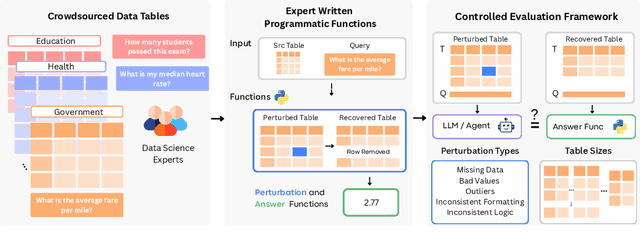
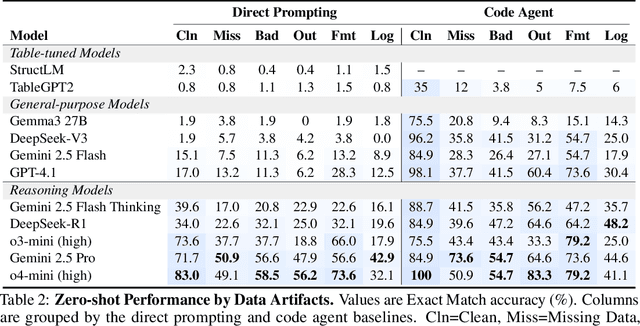
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025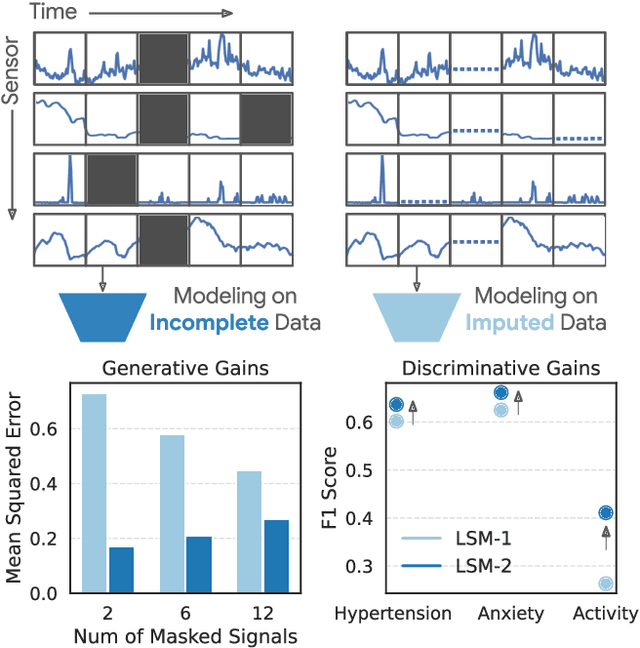
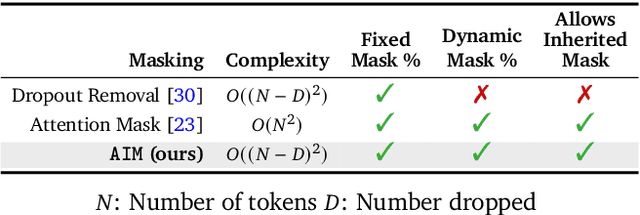
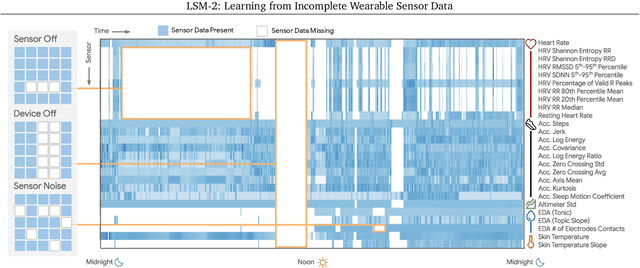
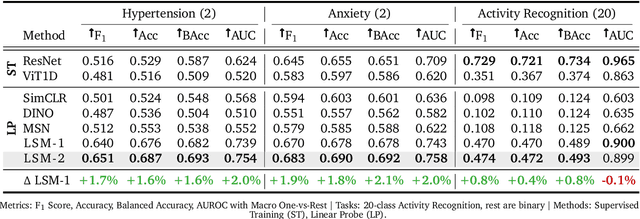
Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Scaling Wearable Foundation Models
Oct 17, 2024



Wearable sensors have become ubiquitous thanks to a variety of health tracking features. The resulting continuous and longitudinal measurements from everyday life generate large volumes of data; however, making sense of these observations for scientific and actionable insights is non-trivial. Inspired by the empirical success of generative modeling, where large neural networks learn powerful representations from vast amounts of text, image, video, or audio data, we investigate the scaling properties of sensor foundation models across compute, data, and model size. Using a dataset of up to 40 million hours of in-situ heart rate, heart rate variability, electrodermal activity, accelerometer, skin temperature, and altimeter per-minute data from over 165,000 people, we create LSM, a multimodal foundation model built on the largest wearable-signals dataset with the most extensive range of sensor modalities to date. Our results establish the scaling laws of LSM for tasks such as imputation, interpolation and extrapolation, both across time and sensor modalities. Moreover, we highlight how LSM enables sample-efficient downstream learning for tasks like exercise and activity recognition.
Exploring and Characterizing Large Language Models For Embedded System Development and Debugging
Jul 07, 2023Large language models (LLMs) have shown remarkable abilities to generate code, however their ability to develop software for embedded systems, which requires cross-domain knowledge of hardware and software has not been studied. In this paper we systematically evaluate leading LLMs (GPT-3.5, GPT-4, PaLM 2) to assess their performance for embedded system development, study how human programmers interact with these tools, and develop an AI-based software engineering workflow for building embedded systems. We develop an an end-to-end hardware-in-the-loop evaluation platform for verifying LLM generated programs using sensor actuator pairs. We compare all three models with N=450 experiments and find surprisingly that GPT-4 especially shows an exceptional level of cross-domain understanding and reasoning, in some cases generating fully correct programs from a single prompt. In N=50 trials, GPT-4 produces functional I2C interfaces 66% of the time. GPT-4 also produces register-level drivers, code for LoRa communication, and context-specific power optimizations for an nRF52 program resulting in over 740x current reduction to 12.2 uA. We also characterize the models' limitations to develop a generalizable workflow for using LLMs in embedded system development. We evaluate the workflow with 15 users including novice and expert programmers. We find that our workflow improves productivity for all users and increases the success rate for building a LoRa environmental sensor from 25% to 100%, including for users with zero hardware or C/C++ experience.
BigSmall: Efficient Multi-Task Learning for Disparate Spatial and Temporal Physiological Measurements
Mar 21, 2023Understanding of human visual perception has historically inspired the design of computer vision architectures. As an example, perception occurs at different scales both spatially and temporally, suggesting that the extraction of salient visual information may be made more effective by paying attention to specific features at varying scales. Visual changes in the body due to physiological processes also occur at different scales and with modality-specific characteristic properties. Inspired by this, we present BigSmall, an efficient architecture for physiological and behavioral measurement. We present the first joint camera-based facial action, cardiac, and pulmonary measurement model. We propose a multi-branch network with wrapping temporal shift modules that yields both accuracy and efficiency gains. We observe that fusing low-level features leads to suboptimal performance, but that fusing high level features enables efficiency gains with negligible loss in accuracy. Experimental results demonstrate that BigSmall significantly reduces the computational costs. Furthermore, compared to existing task-specific models, BigSmall achieves comparable or better results on multiple physiological measurement tasks simultaneously with a unified model.
Deep Physiological Sensing Toolbox
Oct 03, 2022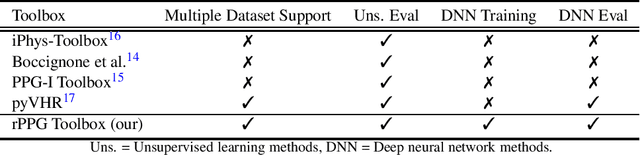
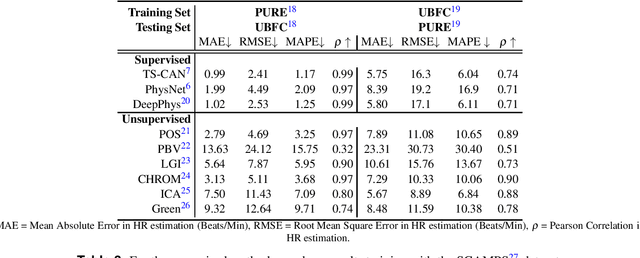
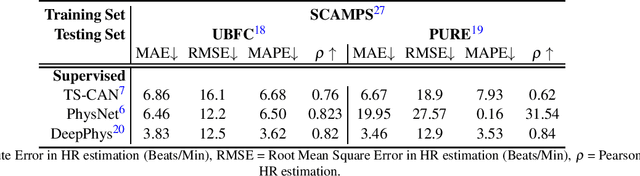
Camera physiological measurement is a fast growing field of computer vision. Remote photoplethysmography (rPPG) uses video cameras (imagers) to measure the peripheral blood volume pulse (BVP). Simply, this enables heart rate measurement via webcams, smartphone cameras and many other imaging devices. The current state-of-the-art methods are supervised deep neural architectures that have large numbers of parameters and a signal number of hyperparameters. Replication of results and benchmarking of new models is critical for scientific progress. However, as with many other applications of deep learning, reliable codebases are not easy to find. We present a comprehensive toolbox, rPPG-Toolbox, containing code for training and evaluating unsupervised and supervised rPPG models: https://github.com/ubicomplab/rPPG-Toolbox