 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Video Object Detection
Papers and Code
FMVP: Masked Flow Matching for Adversarial Video Purification
Jan 05, 2026Video recognition models remain vulnerable to adversarial attacks, while existing diffusion-based purification methods suffer from inefficient sampling and curved trajectories. Directly regressing clean videos from adversarial inputs often fails to recover faithful content due to the subtle nature of perturbations; this necessitates physically shattering the adversarial structure. Therefore, we propose Flow Matching for Adversarial Video Purification FMVP. FMVP physically shatters global adversarial structures via a masking strategy and reconstructs clean video dynamics using Conditional Flow Matching (CFM) with an inpainting objective. To further decouple semantic content from adversarial noise, we design a Frequency-Gated Loss (FGL) that explicitly suppresses high-frequency adversarial residuals while preserving low-frequency fidelity. We design Attack-Aware and Generalist training paradigms to handle known and unknown threats, respectively. Extensive experiments on UCF-101 and HMDB-51 demonstrate that FMVP outperforms state-of-the-art methods (DiffPure, Defense Patterns (DP), Temporal Shuffling (TS) and FlowPure), achieving robust accuracy exceeding 87% against PGD and 89% against CW attacks. Furthermore, FMVP demonstrates superior robustness against adaptive attacks (DiffHammer) and functions as a zero-shot adversarial detector, attaining detection accuracies of 98% for PGD and 79% for highly imperceptible CW attacks.
Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
EgoLoc: A Generalizable Solution for Temporal Interaction Localization in Egocentric Videos
Aug 17, 2025Analyzing hand-object interaction in egocentric vision facilitates VR/AR applications and human-robot policy transfer. Existing research has mostly focused on modeling the behavior paradigm of interactive actions (i.e., ``how to interact''). However, the more challenging and fine-grained problem of capturing the critical moments of contact and separation between the hand and the target object (i.e., ``when to interact'') is still underexplored, which is crucial for immersive interactive experiences in mixed reality and robotic motion planning. Therefore, we formulate this problem as temporal interaction localization (TIL). Some recent works extract semantic masks as TIL references, but suffer from inaccurate object grounding and cluttered scenarios. Although current temporal action localization (TAL) methods perform well in detecting verb-noun action segments, they rely on category annotations during training and exhibit limited precision in localizing hand-object contact/separation moments. To address these issues, we propose a novel zero-shot approach dubbed EgoLoc to localize hand-object contact and separation timestamps in egocentric videos. EgoLoc introduces hand-dynamics-guided sampling to generate high-quality visual prompts. It exploits the vision-language model to identify contact/separation attributes, localize specific timestamps, and provide closed-loop feedback for further refinement. EgoLoc eliminates the need for object masks and verb-noun taxonomies, leading to generalizable zero-shot implementation. Comprehensive experiments on the public dataset and our novel benchmarks demonstrate that EgoLoc achieves plausible TIL for egocentric videos. It is also validated to effectively facilitate multiple downstream applications in egocentric vision and robotic manipulation tasks. Code and relevant data will be released at https://github.com/IRMVLab/EgoLoc.
OpenNav: Open-World Navigation with Multimodal Large Language Models
Jul 24, 2025



Pre-trained large language models (LLMs) have demonstrated strong common-sense reasoning abilities, making them promising for robotic navigation and planning tasks. However, despite recent progress, bridging the gap between language descriptions and actual robot actions in the open-world, beyond merely invoking limited predefined motion primitives, remains an open challenge. In this work, we aim to enable robots to interpret and decompose complex language instructions, ultimately synthesizing a sequence of trajectory points to complete diverse navigation tasks given open-set instructions and open-set objects. We observe that multi-modal large language models (MLLMs) exhibit strong cross-modal understanding when processing free-form language instructions, demonstrating robust scene comprehension. More importantly, leveraging their code-generation capability, MLLMs can interact with vision-language perception models to generate compositional 2D bird-eye-view value maps, effectively integrating semantic knowledge from MLLMs with spatial information from maps to reinforce the robot's spatial understanding. To further validate our approach, we effectively leverage large-scale autonomous vehicle datasets (AVDs) to validate our proposed zero-shot vision-language navigation framework in outdoor navigation tasks, demonstrating its capability to execute a diverse range of free-form natural language navigation instructions while maintaining robustness against object detection errors and linguistic ambiguities. Furthermore, we validate our system on a Husky robot in both indoor and outdoor scenes, demonstrating its real-world robustness and applicability. Supplementary videos are available at https://trailab.github.io/OpenNav-website/
Towards a Multi-Agent Vision-Language System for Zero-Shot Novel Hazardous Object Detection for Autonomous Driving Safety
Apr 18, 2025Detecting anomalous hazards in visual data, particularly in video streams, is a critical challenge in autonomous driving. Existing models often struggle with unpredictable, out-of-label hazards due to their reliance on predefined object categories. In this paper, we propose a multimodal approach that integrates vision-language reasoning with zero-shot object detection to improve hazard identification and explanation. Our pipeline consists of a Vision-Language Model (VLM), a Large Language Model (LLM), in order to detect hazardous objects within a traffic scene. We refine object detection by incorporating OpenAI's CLIP model to match predicted hazards with bounding box annotations, improving localization accuracy. To assess model performance, we create a ground truth dataset by denoising and extending the foundational COOOL (Challenge-of-Out-of-Label) anomaly detection benchmark dataset with complete natural language descriptions for hazard annotations. We define a means of hazard detection and labeling evaluation on the extended dataset using cosine similarity. This evaluation considers the semantic similarity between the predicted hazard description and the annotated ground truth for each video. Additionally, we release a set of tools for structuring and managing large-scale hazard detection datasets. Our findings highlight the strengths and limitations of current vision-language-based approaches, offering insights into future improvements in autonomous hazard detection systems. Our models, scripts, and data can be found at https://github.com/mi3labucm/COOOLER.git
Context in object detection: a systematic literature review
Mar 29, 2025Context is an important factor in computer vision as it offers valuable information to clarify and analyze visual data. Utilizing the contextual information inherent in an image or a video can improve the precision and effectiveness of object detectors. For example, where recognizing an isolated object might be challenging, context information can improve comprehension of the scene. This study explores the impact of various context-based approaches to object detection. Initially, we investigate the role of context in object detection and survey it from several perspectives. We then review and discuss the most recent context-based object detection approaches and compare them. Finally, we conclude by addressing research questions and identifying gaps for further studies. More than 265 publications are included in this survey, covering different aspects of context in different categories of object detection, including general object detection, video object detection, small object detection, camouflaged object detection, zero-shot, one-shot, and few-shot object detection. This literature review presents a comprehensive overview of the latest advancements in context-based object detection, providing valuable contributions such as a thorough understanding of contextual information and effective methods for integrating various context types into object detection, thus benefiting researchers.
* Artificial Intelligence Review Journal
Augmented Reality for RObots (ARRO): Pointing Visuomotor Policies Towards Visual Robustness
May 13, 2025Visuomotor policies trained on human expert demonstrations have recently shown strong performance across a wide range of robotic manipulation tasks. However, these policies remain highly sensitive to domain shifts stemming from background or robot embodiment changes, which limits their generalization capabilities. In this paper, we present ARRO, a novel calibration-free visual representation that leverages zero-shot open-vocabulary segmentation and object detection models to efficiently mask out task-irrelevant regions of the scene without requiring additional training. By filtering visual distractors and overlaying virtual guides during both training and inference, ARRO improves robustness to scene variations and reduces the need for additional data collection. We extensively evaluate ARRO with Diffusion Policy on several tabletop manipulation tasks in both simulation and real-world environments, and further demonstrate its compatibility and effectiveness with generalist robot policies, such as Octo and OpenVLA. Across all settings in our evaluation, ARRO yields consistent performance gains, allows for selective masking to choose between different objects, and shows robustness even to challenging segmentation conditions. Videos showcasing our results are available at: augmented-reality-for-robots.github.io
Towards a General-Purpose Zero-Shot Synthetic Low-Light Image and Video Pipeline
Apr 16, 2025Low-light conditions pose significant challenges for both human and machine annotation. This in turn has led to a lack of research into machine understanding for low-light images and (in particular) videos. A common approach is to apply annotations obtained from high quality datasets to synthetically created low light versions. In addition, these approaches are often limited through the use of unrealistic noise models. In this paper, we propose a new Degradation Estimation Network (DEN), which synthetically generates realistic standard RGB (sRGB) noise without the requirement for camera metadata. This is achieved by estimating the parameters of physics-informed noise distributions, trained in a self-supervised manner. This zero-shot approach allows our method to generate synthetic noisy content with a diverse range of realistic noise characteristics, unlike other methods which focus on recreating the noise characteristics of the training data. We evaluate our proposed synthetic pipeline using various methods trained on its synthetic data for typical low-light tasks including synthetic noise replication, video enhancement, and object detection, showing improvements of up to 24\% KLD, 21\% LPIPS, and 62\% AP$_{50-95}$, respectively.
Perception Encoder: The best visual embeddings are not at the output of the network
Apr 17, 2025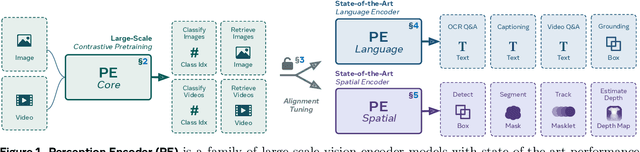

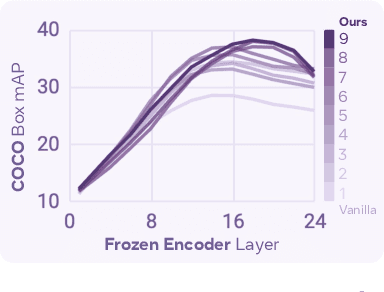
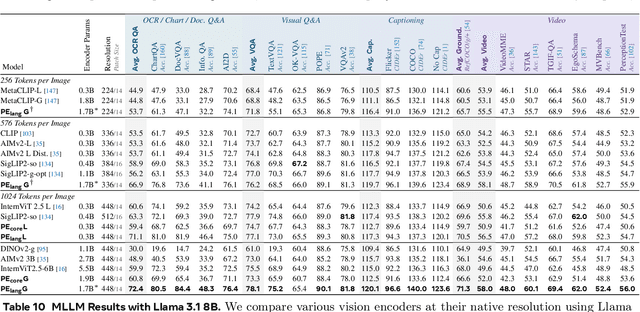
We introduce Perception Encoder (PE), a state-of-the-art encoder for image and video understanding trained via simple vision-language learning. Traditionally, vision encoders have relied on a variety of pretraining objectives, each tailored to specific downstream tasks such as classification, captioning, or localization. Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods, language alignment for multimodal language modeling, and spatial alignment for dense prediction. Together with the core contrastive checkpoint, our PE family of models achieves state-of-the-art performance on a wide variety of tasks, including zero-shot image and video classification and retrieval; document, image, and video Q&A; and spatial tasks such as detection, depth estimation, and tracking. To foster further research, we are releasing our models, code, and a novel dataset of synthetically and human-annotated videos.
IDMR: Towards Instance-Driven Precise Visual Correspondence in Multimodal Retrieval
Apr 01, 2025Multimodal retrieval systems are becoming increasingly vital for cutting-edge AI technologies, such as embodied AI and AI-driven digital content industries. However, current multimodal retrieval tasks lack sufficient complexity and demonstrate limited practical application value. It spires us to design Instance-Driven Multimodal Image Retrieval (IDMR), a novel task that requires models to retrieve images containing the same instance as a query image while matching a text-described scenario. Unlike existing retrieval tasks focused on global image similarity or category-level matching, IDMR demands fine-grained instance-level consistency across diverse contexts. To benchmark this capability, we develop IDMR-bench using real-world object tracking and first-person video data. Addressing the scarcity of training data, we propose a cross-domain synthesis method that creates 557K training samples by cropping objects from standard detection datasets. Our Multimodal Large Language Model (MLLM) based retrieval model, trained on 1.2M samples, outperforms state-of-the-art approaches on both traditional benchmarks and our zero-shot IDMR-bench. Experimental results demonstrate previous models' limitations in instance-aware retrieval and highlight the potential of MLLM for advanced retrieval applications. The whole training dataset, codes and models, with wide ranges of sizes, are available at https://github.com/BwLiu01/IDMR.