 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
SAM Audio: Segment Anything in Audio
Dec 19, 2025



General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Feb 07, 2025



The quantification of audio aesthetics remains a complex challenge in audio processing, primarily due to its subjective nature, which is influenced by human perception and cultural context. Traditional methods often depend on human listeners for evaluation, leading to inconsistencies and high resource demands. This paper addresses the growing need for automated systems capable of predicting audio aesthetics without human intervention. Such systems are crucial for applications like data filtering, pseudo-labeling large datasets, and evaluating generative audio models, especially as these models become more sophisticated. In this work, we introduce a novel approach to audio aesthetic evaluation by proposing new annotation guidelines that decompose human listening perspectives into four distinct axes. We develop and train no-reference, per-item prediction models that offer a more nuanced assessment of audio quality. Our models are evaluated against human mean opinion scores (MOS) and existing methods, demonstrating comparable or superior performance. This research not only advances the field of audio aesthetics but also provides open-source models and datasets to facilitate future work and benchmarking. We release our code and pre-trained model at: https://github.com/facebookresearch/audiobox-aesthetics
Flow Matching Guide and Code
Dec 09, 2024Flow Matching (FM) is a recent framework for generative modeling that has achieved state-of-the-art performance across various domains, including image, video, audio, speech, and biological structures. This guide offers a comprehensive and self-contained review of FM, covering its mathematical foundations, design choices, and extensions. By also providing a PyTorch package featuring relevant examples (e.g., image and text generation), this work aims to serve as a resource for both novice and experienced researchers interested in understanding, applying and further developing FM.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Learning Fine-Grained Controllability on Speech Generation via Efficient Fine-Tuning
Jun 10, 2024



As the scale of generative models continues to grow, efficient reuse and adaptation of pre-trained models have become crucial considerations. In this work, we propose Voicebox Adapter, a novel approach that integrates fine-grained conditions into a pre-trained Voicebox speech generation model using a cross-attention module. To ensure a smooth integration of newly added modules with pre-trained ones, we explore various efficient fine-tuning approaches. Our experiment shows that the LoRA with bias-tuning configuration yields the best performance, enhancing controllability without compromising speech quality. Across three fine-grained conditional generation tasks, we demonstrate the effectiveness and resource efficiency of Voicebox Adapter. Follow-up experiments further highlight the robustness of Voicebox Adapter across diverse data setups.
Guided Flows for Generative Modeling and Decision Making
Dec 07, 2023Classifier-free guidance is a key component for enhancing the performance of conditional generative models across diverse tasks. While it has previously demonstrated remarkable improvements for the sample quality, it has only been exclusively employed for diffusion models. In this paper, we integrate classifier-free guidance into Flow Matching (FM) models, an alternative simulation-free approach that trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. We explore the usage of \emph{Guided Flows} for a variety of downstream applications. We show that Guided Flows significantly improves the sample quality in conditional image generation and zero-shot text-to-speech synthesis, boasting state-of-the-art performance. Notably, we are the first to apply flow models for plan generation in the offline reinforcement learning setting, showcasing a 10x speedup in computation compared to diffusion models while maintaining comparable performance.
Generative Pre-training for Speech with Flow Matching
Oct 25, 2023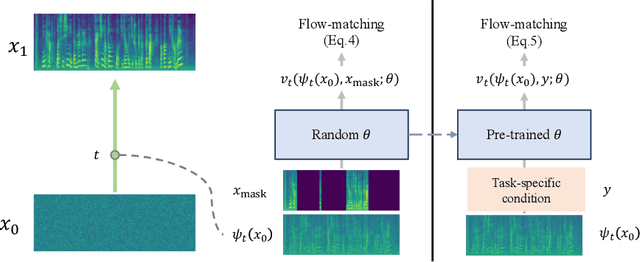
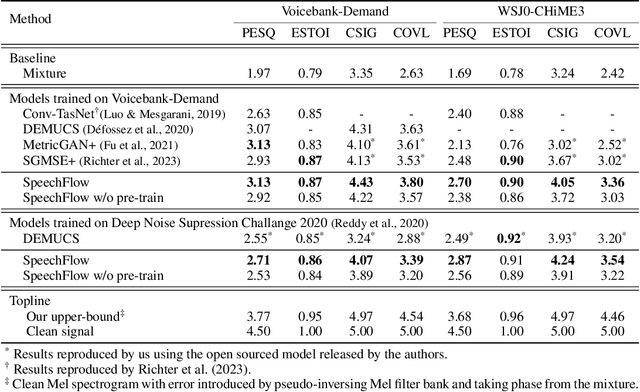
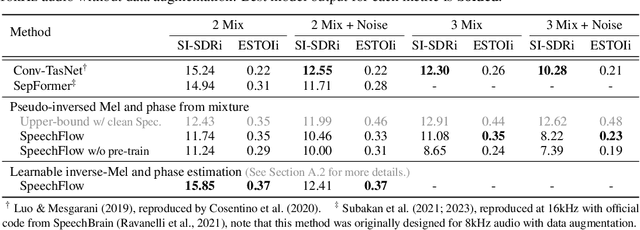
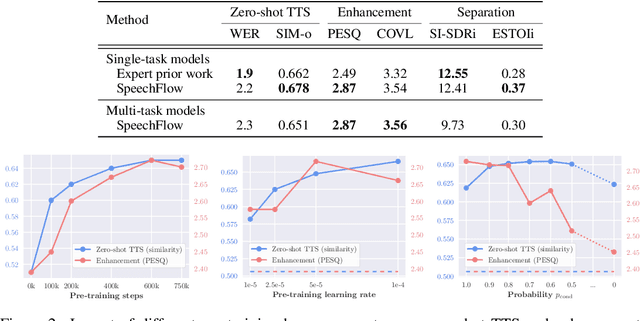
Generative models have gained more and more attention in recent years for their remarkable success in tasks that required estimating and sampling data distribution to generate high-fidelity synthetic data. In speech, text-to-speech synthesis and neural vocoder are good examples where generative models have shined. While generative models have been applied to different applications in speech, there exists no general-purpose generative model that models speech directly. In this work, we take a step toward this direction by showing a single pre-trained generative model can be adapted to different downstream tasks with strong performance. Specifically, we pre-trained a generative model, named SpeechFlow, on 60k hours of untranscribed speech with Flow Matching and masked conditions. Experiment results show the pre-trained generative model can be fine-tuned with task-specific data to match or surpass existing expert models on speech enhancement, separation, and synthesis. Our work suggested a foundational model for generation tasks in speech can be built with generative pre-training.
On Kinetic Optimal Probability Paths for Generative Models
Jun 11, 2023Recent successful generative models are trained by fitting a neural network to an a-priori defined tractable probability density path taking noise to training examples. In this paper we investigate the space of Gaussian probability paths, which includes diffusion paths as an instance, and look for an optimal member in some useful sense. In particular, minimizing the Kinetic Energy (KE) of a path is known to make particles' trajectories simple, hence easier to sample, and empirically improve performance in terms of likelihood of unseen data and sample generation quality. We investigate Kinetic Optimal (KO) Gaussian paths and offer the following observations: (i) We show the KE takes a simplified form on the space of Gaussian paths, where the data is incorporated only through a single, one dimensional scalar function, called the \emph{data separation function}. (ii) We characterize the KO solutions with a one dimensional ODE. (iii) We approximate data-dependent KO paths by approximating the data separation function and minimizing the KE. (iv) We prove that the data separation function converges to $1$ in the general case of arbitrary normalized dataset consisting of $n$ samples in $d$ dimension as $n/\sqrt{d}\rightarrow 0$. A consequence of this result is that the Conditional Optimal Transport (Cond-OT) path becomes \emph{kinetic optimal} as $n/\sqrt{d}\rightarrow 0$. We further support this theory with empirical experiments on ImageNet.
Flow Matching for Generative Modeling
Oct 06, 2022
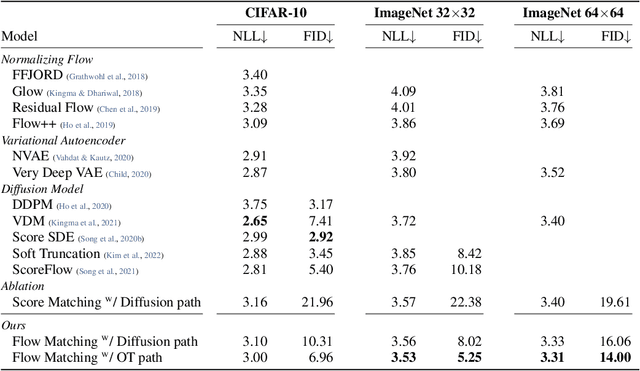

We introduce a new paradigm for generative modeling built on Continuous Normalizing Flows (CNFs), allowing us to train CNFs at unprecedented scale. Specifically, we present the notion of Flow Matching (FM), a simulation-free approach for training CNFs based on regressing vector fields of fixed conditional probability paths. Flow Matching is compatible with a general family of Gaussian probability paths for transforming between noise and data samples -- which subsumes existing diffusion paths as specific instances. Interestingly, we find that employing FM with diffusion paths results in a more robust and stable alternative for training diffusion models. Furthermore, Flow Matching opens the door to training CNFs with other, non-diffusion probability paths. An instance of particular interest is using Optimal Transport (OT) displacement interpolation to define the conditional probability paths. These paths are more efficient than diffusion paths, provide faster training and sampling, and result in better generalization. Training CNFs using Flow Matching on ImageNet leads to state-of-the-art performance in terms of both likelihood and sample quality, and allows fast and reliable sample generation using off-the-shelf numerical ODE solvers.