 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixIE: Prompted Pixel-Space Low-Light Image Enhancement
May 27, 2026Low-light images suffer from severe noise, contrast loss, and semantic ambiguity, making enhancement a joint problem of denoising and detail recovery. We propose PixIE, a feed-forward pixel-space LLIE framework semantically prompted by a vision foundation model. PixIE first performs cross-scale denoising to suppress noise and preserve structure, then refines details using DINO-Prompted Pixel Blocks (DPPBs), which inject intermediate DINOv3 features through patch-conditioned, spatially continuous per-pixel modulation. To make pixel-space attention efficient across scales, we introduce Spatial-Channel Compaction (SCC), which jointly reduces the spatial token grid and channel dimension. We further propose Multi-Receptive-Field Pixel Embedding (MRPE) to provide neighborhood-aware pixel representations before semantic prompting, improving robustness to signal-dependent noise beyond point-wise embeddings. Experiments on LLIE benchmarks show that PixIE improves average PSNR by 1.9-15.0% over recent state-of-the-art methods and reduces LPIPS by 8.5-44.4%. Qualitative comparisons further show sharper details and more stable textures, improving both reconstruction fidelity and perceptual quality.
BVI-Mamba: Video Enhancement Using a Visual State-Space Model for Low-Light and Underwater Environments
Apr 26, 2026Videos captured in low-light and underwater conditions often suffer from distortions such as noise, low contrast, color imbalance, and blur. These issues not only limit visibility but also degrade automatic tasks like detection. Post-processing is typically required but can be time-consuming. AI-based tools for video enhancement also demand significantly more computational resources compared to image-based methods. This paper introduces a novel framework, Visual Mamba, designed to reduce memory usage and computational time by leveraging the Visual State Space (VSS) model. The framework consists of two modules: (i) a feature alignment module, where spatio-temporal displacement between input frames is registered in the feature space, and (ii) an enhancement module, where noise removal and brightness adjustment are performed using a UNet-like architecture, with all convolutional layers replaced by VSS blocks. Experimental results show that the Visual Mamba technique outperforms Transformer and convolution-based models in both low-light and underwater video enhancement tasks. Code is available on line at https://github.com/russellllaputa/BVI-Mamba.
Dynamic Weight-based Temporal Aggregation for Low-light Video Enhancement
Oct 10, 2025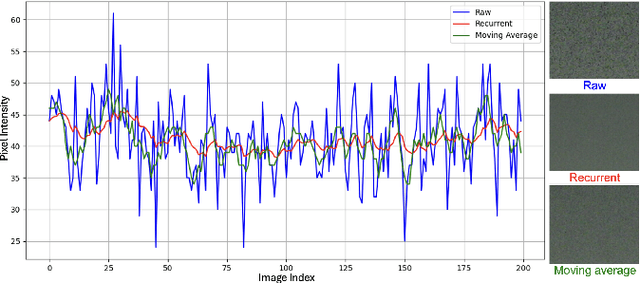
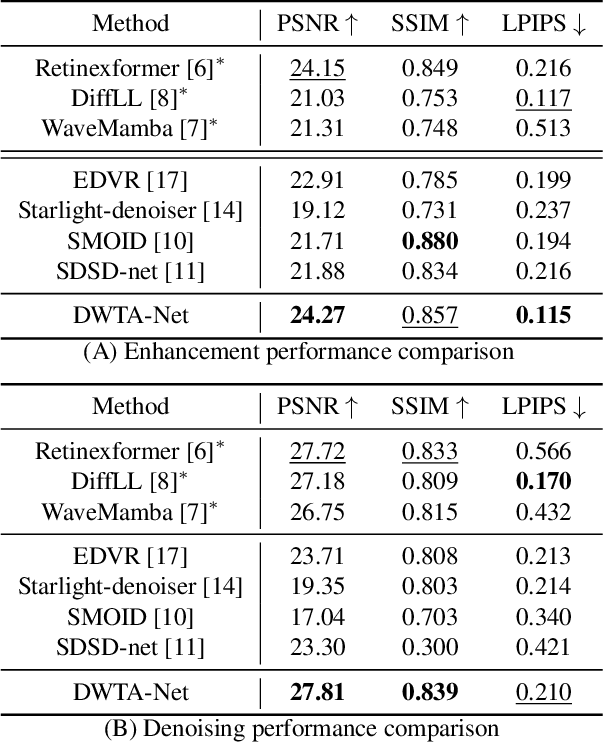


Low-light video enhancement (LLVE) is challenging due to noise, low contrast, and color degradations. Learning-based approaches offer fast inference but still struggle with heavy noise in real low-light scenes, primarily due to limitations in effectively leveraging temporal information. In this paper, we address this issue with DWTA-Net, a novel two-stage framework that jointly exploits short- and long-term temporal cues. Stage I employs Visual State-Space blocks for multi-frame alignment, recovering brightness, color, and structure with local consistency. Stage II introduces a recurrent refinement module with dynamic weight-based temporal aggregation guided by optical flow, adaptively balancing static and dynamic regions. A texture-adaptive loss further preserves fine details while promoting smoothness in flat areas. Experiments on real-world low-light videos show that DWTA-Net effectively suppresses noise and artifacts, delivering superior visual quality compared with state-of-the-art methods.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Towards a General-Purpose Zero-Shot Synthetic Low-Light Image and Video Pipeline
Apr 16, 2025



Low-light conditions pose significant challenges for both human and machine annotation. This in turn has led to a lack of research into machine understanding for low-light images and (in particular) videos. A common approach is to apply annotations obtained from high quality datasets to synthetically created low light versions. In addition, these approaches are often limited through the use of unrealistic noise models. In this paper, we propose a new Degradation Estimation Network (DEN), which synthetically generates realistic standard RGB (sRGB) noise without the requirement for camera metadata. This is achieved by estimating the parameters of physics-informed noise distributions, trained in a self-supervised manner. This zero-shot approach allows our method to generate synthetic noisy content with a diverse range of realistic noise characteristics, unlike other methods which focus on recreating the noise characteristics of the training data. We evaluate our proposed synthetic pipeline using various methods trained on its synthetic data for typical low-light tasks including synthetic noise replication, video enhancement, and object detection, showing improvements of up to 24\% KLD, 21\% LPIPS, and 62\% AP$_{50-95}$, respectively.
BVI-RLV: A Fully Registered Dataset and Benchmarks for Low-Light Video Enhancement
Jul 03, 2024



Low-light videos often exhibit spatiotemporal incoherent noise, compromising visibility and performance in computer vision applications. One significant challenge in enhancing such content using deep learning is the scarcity of training data. This paper introduces a novel low-light video dataset, consisting of 40 scenes with various motion scenarios under two distinct low-lighting conditions, incorporating genuine noise and temporal artifacts. We provide fully registered ground truth data captured in normal light using a programmable motorized dolly and refine it via an image-based approach for pixel-wise frame alignment across different light levels. We provide benchmarks based on four different technologies: convolutional neural networks, transformers, diffusion models, and state space models (mamba). Our experimental results demonstrate the significance of fully registered video pairs for low-light video enhancement (LLVE) and the comprehensive evaluation shows that the models trained with our dataset outperform those trained with the existing datasets. Our dataset and links to benchmarks are publicly available at https://doi.org/10.21227/mzny-8c77.
A Spatio-temporal Aligned SUNet Model for Low-light Video Enhancement
Mar 04, 2024



Distortions caused by low-light conditions are not only visually unpleasant but also degrade the performance of computer vision tasks. The restoration and enhancement have proven to be highly beneficial. However, there are only a limited number of enhancement methods explicitly designed for videos acquired in low-light conditions. We propose a Spatio-Temporal Aligned SUNet (STA-SUNet) model using a Swin Transformer as a backbone to capture low light video features and exploit their spatio-temporal correlations. The STA-SUNet model is trained on a novel, fully registered dataset (BVI), which comprises dynamic scenes captured under varying light conditions. It is further analysed comparatively against various other models over three test datasets. The model demonstrates superior adaptivity across all datasets, obtaining the highest PSNR and SSIM values. It is particularly effective in extreme low-light conditions, yielding fairly good visualisation results.
BVI-Lowlight: Fully Registered Benchmark Dataset for Low-Light Video Enhancement
Feb 03, 2024



Low-light videos often exhibit spatiotemporal incoherent noise, leading to poor visibility and compromised performance across various computer vision applications. One significant challenge in enhancing such content using modern technologies is the scarcity of training data. This paper introduces a novel low-light video dataset, consisting of 40 scenes captured in various motion scenarios under two distinct low-lighting conditions, incorporating genuine noise and temporal artifacts. We provide fully registered ground truth data captured in normal light using a programmable motorized dolly, and subsequently, refine them via image-based post-processing to ensure the pixel-wise alignment of frames in different light levels. This paper also presents an exhaustive analysis of the low-light dataset, and demonstrates the extensive and representative nature of our dataset in the context of supervised learning. Our experimental results demonstrate the significance of fully registered video pairs in the development of low-light video enhancement methods and the need for comprehensive evaluation. Our dataset is available at DOI:10.21227/mzny-8c77.