 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Relationship Detection Dataset
Papers and Code
Toward Autonomous Laboratory Safety Monitoring with Vision Language Models: Learning to See Hazards Through Scene Structure
Jan 31, 2026Laboratories are prone to severe injuries from minor unsafe actions, yet continuous safety monitoring -- beyond mandatory pre-lab safety training -- is limited by human availability. Vision language models (VLMs) offer promise for autonomous laboratory safety monitoring, but their effectiveness in realistic settings is unclear due to the lack of visual evaluation data, as most safety incidents are documented primarily as unstructured text. To address this gap, we first introduce a structured data generation pipeline that converts textual laboratory scenarios into aligned triples of (image, scene graph, ground truth), using large language models as scene graph architects and image generation models as renderers. Our experiments on the synthetic dataset of 1,207 samples across 362 unique scenarios and seven open- and closed-source models show that VLMs perform effectively given textual scene graph, but degrade substantially in visual-only settings indicating difficulty in extracting structured object relationships directly from pixels. To overcome this, we propose a post-training context-engineering approach, scene-graph-guided alignment, to bridge perceptual gaps in VLMs by translating visual inputs into structured scene graphs better aligned with VLM reasoning, improving hazard detection performance in visual only settings.
When Anomalies Depend on Context: Learning Conditional Compatibility for Anomaly Detection
Jan 30, 2026Anomaly detection is often formulated under the assumption that abnormality is an intrinsic property of an observation, independent of context. This assumption breaks down in many real-world settings, where the same object or action may be normal or anomalous depending on latent contextual factors (e.g., running on a track versus on a highway). We revisit \emph{contextual anomaly detection}, classically defined as context-dependent abnormality, and operationalize it in the visual domain, where anomaly labels depend on subject--context compatibility rather than intrinsic appearance. To enable systematic study of this setting, we introduce CAAD-3K, a benchmark that isolates contextual anomalies by controlling subject identity while varying context. We further propose a conditional compatibility learning framework that leverages vision--language representations to model subject--context relationships under limited supervision. Our method substantially outperforms existing approaches on CAAD-3K and achieves state-of-the-art performance on MVTec-AD and VisA, demonstrating that modeling context dependence complements traditional structural anomaly detection. Our code and dataset will be publicly released.
4D-CAAL: 4D Radar-Camera Calibration and Auto-Labeling for Autonomous Driving
Jan 29, 20264D radar has emerged as a critical sensor for autonomous driving, primarily due to its enhanced capabilities in elevation measurement and higher resolution compared to traditional 3D radar. Effective integration of 4D radar with cameras requires accurate extrinsic calibration, and the development of radar-based perception algorithms demands large-scale annotated datasets. However, existing calibration methods often employ separate targets optimized for either visual or radar modalities, complicating correspondence establishment. Furthermore, manually labeling sparse radar data is labor-intensive and unreliable. To address these challenges, we propose 4D-CAAL, a unified framework for 4D radar-camera calibration and auto-labeling. Our approach introduces a novel dual-purpose calibration target design, integrating a checkerboard pattern on the front surface for camera detection and a corner reflector at the center of the back surface for radar detection. We develop a robust correspondence matching algorithm that aligns the checkerboard center with the strongest radar reflection point, enabling accurate extrinsic calibration. Subsequently, we present an auto-labeling pipeline that leverages the calibrated sensor relationship to transfer annotations from camera-based segmentations to radar point clouds through geometric projection and multi-feature optimization. Extensive experiments demonstrate that our method achieves high calibration accuracy while significantly reducing manual annotation effort, thereby accelerating the development of robust multi-modal perception systems for autonomous driving.
LogicLens: Visual-Logical Co-Reasoning for Text-Centric Forgery Analysis
Dec 25, 2025Sophisticated text-centric forgeries, fueled by rapid AIGC advancements, pose a significant threat to societal security and information authenticity. Current methods for text-centric forgery analysis are often limited to coarse-grained visual analysis and lack the capacity for sophisticated reasoning. Moreover, they typically treat detection, grounding, and explanation as discrete sub-tasks, overlooking their intrinsic relationships for holistic performance enhancement. To address these challenges, we introduce LogicLens, a unified framework for Visual-Textual Co-reasoning that reformulates these objectives into a joint task. The deep reasoning of LogicLens is powered by our novel Cross-Cues-aware Chain of Thought (CCT) mechanism, which iteratively cross-validates visual cues against textual logic. To ensure robust alignment across all tasks, we further propose a weighted multi-task reward function for GRPO-based optimization. Complementing this framework, we first designed the PR$^2$ (Perceiver, Reasoner, Reviewer) pipeline, a hierarchical and iterative multi-agent system that generates high-quality, cognitively-aligned annotations. Then, we constructed RealText, a diverse dataset comprising 5,397 images with fine-grained annotations, including textual explanations, pixel-level segmentation, and authenticity labels for model training. Extensive experiments demonstrate the superiority of LogicLens across multiple benchmarks. In a zero-shot evaluation on T-IC13, it surpasses the specialized framework by 41.4% and GPT-4o by 23.4% in macro-average F1 score. Moreover, on the challenging dense-text T-SROIE dataset, it establishes a significant lead over other MLLM-based methods in mF1, CSS, and the macro-average F1. Our dataset, model, and code will be made publicly available.
Self-organizing maps for water quality assessment in reservoirs and lakes: A systematic literature review
Dec 20, 2025Sustainable water quality underpins ecological balance and water security. Assessing and managing lakes and reservoirs is difficult due to data sparsity, heterogeneity, and nonlinear relationships among parameters. This review examines how Self-Organizing Map (SOM), an unsupervised AI technique, is applied to water quality assessment. It synthesizes research on parameter selection, spatial and temporal sampling strategies, and clustering approaches. Emphasis is placed on how SOM handles multidimensional data and uncovers hidden patterns to support effective water management. The growing availability of environmental data from in-situ sensors, remote sensing imagery, IoT technologies, and historical records has significantly expanded analytical opportunities in environmental monitoring. SOM has proven effective in analysing complex datasets, particularly when labelled data are limited or unavailable. It enables high-dimensional data visualization, facilitates the detection of hidden ecological patterns, and identifies critical correlations among diverse water quality indicators. This review highlights SOMs versatility in ecological assessments, trophic state classification, algal bloom monitoring, and catchment area impact evaluations. The findings offer comprehensive insights into existing methodologies, supporting future research and practical applications aimed at improving the monitoring and sustainable management of lake and reservoir ecosystems.
Improving Pattern Recognition of Scheduling Anomalies through Structure-Aware and Semantically-Enhanced Graphs
Dec 21, 2025This paper proposes a structure-aware driven scheduling graph modeling method to improve the accuracy and representation capability of anomaly identification in scheduling behaviors of complex systems. The method first designs a structure-guided scheduling graph construction mechanism that integrates task execution stages, resource node states, and scheduling path information to build dynamically evolving scheduling behavior graphs, enhancing the model's ability to capture global scheduling relationships. On this basis, a multi-scale graph semantic aggregation module is introduced to achieve semantic consistency modeling of scheduling features through local adjacency semantic integration and global topology alignment, thereby strengthening the model's capability to capture abnormal features in complex scenarios such as multi-task concurrency, resource competition, and stage transitions. Experiments are conducted on a real scheduling dataset with multiple scheduling disturbance paths set to simulate different types of anomalies, including structural shifts, resource changes, and task delays. The proposed model demonstrates significant performance advantages across multiple metrics, showing a sensitive response to structural disturbances and semantic shifts. Further visualization analysis reveals that, under the combined effect of structure guidance and semantic aggregation, the scheduling behavior graph exhibits stronger anomaly separability and pattern representation, validating the effectiveness and adaptability of the method in scheduling anomaly detection tasks.
N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models
Dec 18, 2025While current multimodal models can answer questions based on 2D images, they lack intrinsic 3D object perception, limiting their ability to comprehend spatial relationships and depth cues in 3D scenes. In this work, we propose N3D-VLM, a novel unified framework that seamlessly integrates native 3D object perception with 3D-aware visual reasoning, enabling both precise 3D grounding and interpretable spatial understanding. Unlike conventional end-to-end models that directly predict answers from RGB/RGB-D inputs, our approach equips the model with native 3D object perception capabilities, enabling it to directly localize objects in 3D space based on textual descriptions. Building upon accurate 3D object localization, the model further performs explicit reasoning in 3D, achieving more interpretable and structured spatial understanding. To support robust training for these capabilities, we develop a scalable data construction pipeline that leverages depth estimation to lift large-scale 2D annotations into 3D space, significantly increasing the diversity and coverage for 3D object grounding data, yielding over six times larger than the largest existing single-image 3D detection dataset. Moreover, the pipeline generates spatial question-answering datasets that target chain-of-thought (CoT) reasoning in 3D, facilitating joint training for both 3D object localization and 3D spatial reasoning. Experimental results demonstrate that our unified framework not only achieves state-of-the-art performance on 3D grounding tasks, but also consistently surpasses existing methods in 3D spatial reasoning in vision-language model.
Hands-on Evaluation of Visual Transformers for Object Recognition and Detection
Dec 10, 2025Convolutional Neural Networks (CNNs) for computer vision sometimes struggle with understanding images in a global context, as they mainly focus on local patterns. On the other hand, Vision Transformers (ViTs), inspired by models originally created for language processing, use self-attention mechanisms, which allow them to understand relationships across the entire image. In this paper, we compare different types of ViTs (pure, hierarchical, and hybrid) against traditional CNN models across various tasks, including object recognition, detection, and medical image classification. We conduct thorough tests on standard datasets like ImageNet for image classification and COCO for object detection. Additionally, we apply these models to medical imaging using the ChestX-ray14 dataset. We find that hybrid and hierarchical transformers, especially Swin and CvT, offer a strong balance between accuracy and computational resources. Furthermore, by experimenting with data augmentation techniques on medical images, we discover significant performance improvements, particularly with the Swin Transformer model. Overall, our results indicate that Vision Transformers are competitive and, in many cases, outperform traditional CNNs, especially in scenarios requiring the understanding of global visual contexts like medical imaging.
Scene Graph-Guided Generative AI Framework for Synthesizing and Evaluating Industrial Hazard Scenarios
Nov 17, 2025



Training vision models to detect workplace hazards accurately requires realistic images of unsafe conditions that could lead to accidents. However, acquiring such datasets is difficult because capturing accident-triggering scenarios as they occur is nearly impossible. To overcome this limitation, this study presents a novel scene graph-guided generative AI framework that synthesizes photorealistic images of hazardous scenarios grounded in historical Occupational Safety and Health Administration (OSHA) accident reports. OSHA narratives are analyzed using GPT-4o to extract structured hazard reasoning, which is converted into object-level scene graphs capturing spatial and contextual relationships essential for understanding risk. These graphs guide a text-to-image diffusion model to generate compositionally accurate hazard scenes. To evaluate the realism and semantic fidelity of the generated data, a visual question answering (VQA) framework is introduced. Across four state-of-the-art generative models, the proposed VQA Graph Score outperforms CLIP and BLIP metrics based on entropy-based validation, confirming its higher discriminative sensitivity.
A Multi-Modal Neuro-Symbolic Approach for Spatial Reasoning-Based Visual Grounding in Robotics
Oct 30, 2025
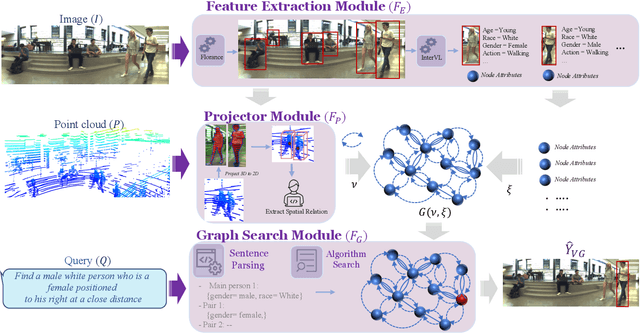


Visual reasoning, particularly spatial reasoning, is a challenging cognitive task that requires understanding object relationships and their interactions within complex environments, especially in robotics domain. Existing vision_language models (VLMs) excel at perception tasks but struggle with fine-grained spatial reasoning due to their implicit, correlation-driven reasoning and reliance solely on images. We propose a novel neuro_symbolic framework that integrates both panoramic-image and 3D point cloud information, combining neural perception with symbolic reasoning to explicitly model spatial and logical relationships. Our framework consists of a perception module for detecting entities and extracting attributes, and a reasoning module that constructs a structured scene graph to support precise, interpretable queries. Evaluated on the JRDB-Reasoning dataset, our approach demonstrates superior performance and reliability in crowded, human_built environments while maintaining a lightweight design suitable for robotics and embodied AI applications.