 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeniOmni: A Structured Multimodal Benchmark for Holistic Meniscus Injury Assessment
May 27, 2026Clinical diagnosis of meniscus injuries requires radiologists to integrate volumetric MRI evidence with patient context (e.g., sex, age, BMI) and to produce structured diagnostic reports. Existing knee MRI benchmarks are typically unimodal and rely on coarse labels, limiting their ability to evaluate holistic clinical reasoning. We introduce MeniOmni, a structured multimodal benchmark for meniscus injury assessment, consisting of 746 multi-center MRI studies with tri-planar volumetric inputs, Clinical Priors, and expert-annotated clinical text. MeniOmni supports two tasks: (1) fine-grained Stoller severity grading and (2) diagnostic report generation. We further propose risk-aware ordinal evaluation and a semantic consistency metric (Meni-Score) to better reflect clinical relevance. Baseline experiments show that incorporating Clinical Priors improves grading performance and reduces severe errors, highlighting the value of multimodal context for safer assessment. Code and data are available at https://github.com/ShuruiXu/MeniOmni.
SVGS: Single-View to 3D Object Editing via Gaussian Splatting
Mar 30, 2026Text-driven 3D scene editing has attracted considerable interest due to its convenience and user-friendliness. However, methods that rely on implicit 3D representations, such as Neural Radiance Fields (NeRF), while effective in rendering complex scenes, are hindered by slow processing speeds and limited control over specific regions of the scene. Moreover, existing approaches, including Instruct-NeRF2NeRF and GaussianEditor, which utilize multi-view editing strategies, frequently produce inconsistent results across different views when executing text instructions. This inconsistency can adversely affect the overall performance of the model, complicating the task of balancing the consistency of editing results with editing efficiency. To address these challenges, we propose a novel method termed Single-View to 3D Object Editing via Gaussian Splatting (SVGS), which is a single-view text-driven editing technique based on 3D Gaussian Splatting (3DGS). Specifically, in response to text instructions, we introduce a single-view editing strategy grounded in multi-view diffusion models, which reconstructs 3D scenes by leveraging only those views that yield consistent editing results. Additionally, we employ sparse 3D Gaussian Splatting as the 3D representation, which significantly enhances editing efficiency. We conducted a comparative analysis of SVGS against existing baseline methods across various scene settings, and the results indicate that SVGS outperforms its counterparts in both editing capability and processing speed, representing a significant advancement in 3D editing technology. For further details, please visit our project page at: https://amateurc.github.io/svgs.github.io.
DM-CFO: A Diffusion Model for Compositional 3D Tooth Generation with Collision-Free Optimization
Mar 04, 2026The automatic design of a 3D tooth model plays a crucial role in dental digitization. However, current approaches face challenges in compositional 3D tooth generation because both the layouts and shapes of missing teeth need to be optimized.In addition, collision conflicts are often omitted in 3D Gaussian-based compositional 3D generation, where objects may intersect with each other due to the absence of explicit geometric information on the object surfaces. Motivated by graph generation through diffusion models and collision detection using 3D Gaussians, we propose an approach named DM-CFO for compositional tooth generation, where the layout of missing teeth is progressively restored during the denoising phase under both text and graph constraints. Then, the Gaussian parameters of each layout-guided tooth and the entire jaw are alternately updated using score distillation sampling (SDS). Furthermore, a regularization term based on the distances between the 3D Gaussians of neighboring teeth and the anchor tooth is introduced to penalize tooth intersections. Experimental results on three tooth-design datasets demonstrate that our approach significantly improves the multiview consistency and realism of the generated teeth compared with existing methods. Project page: https://amateurc.github.io/CF-3DTeeth/.
SEHFS: Structural Entropy-Guided High-Order Correlation Learning for Multi-View Multi-Label Feature Selection
Mar 03, 2026In recent years, multi-view multi-label learning (MVML) has attracted extensive attention due to its close alignment to real-world scenarios. Information-theoretic methods have gained prominence for learning nonlinear correlations. However, two key challenges persist: first, features in real-world data commonly exhibit high-order structural correlations, but existing information-theoretic methods struggle to learn such correlations; second, commonly relying on heuristic optimization, information-theoretic methods are prone to converging to local optima. To address these two challenges, we propose a novel method called Structural Entropy Guided High-Order Correlation Learning for Multi-View Multi-Label Feature Selection (SEHFS). The core idea of SEHFS is to convert the feature graph into a structural-entropy-minimizing encoding tree, quantifying the information cost of high-order dependencies and thus learning high-order feature correlations beyond pairwise correlations. Specifically, features exhibiting strong high-order redundancy are grouped into a single cluster within the encoding tree, while inter-cluster feaeture correlations are minimized, thereby eliminating redundancy both within and across clusters. Furthermore, a new framework based on the fusion of information theory and matrix methods is adopted, which learns a shared semantic matrix and view-specific contribution matrices to reconstruct a global view matrix, thereby enhancing the information-theoretic method and balancing the global and local optimization. The ability of structural entropy to learn high-order correlations is theoretically established, and and both experiments on eight datasets from various domains and ablation studies demonstrate that SEHFS achieves superior performance in feature selection.
4D-CAAL: 4D Radar-Camera Calibration and Auto-Labeling for Autonomous Driving
Jan 29, 20264D radar has emerged as a critical sensor for autonomous driving, primarily due to its enhanced capabilities in elevation measurement and higher resolution compared to traditional 3D radar. Effective integration of 4D radar with cameras requires accurate extrinsic calibration, and the development of radar-based perception algorithms demands large-scale annotated datasets. However, existing calibration methods often employ separate targets optimized for either visual or radar modalities, complicating correspondence establishment. Furthermore, manually labeling sparse radar data is labor-intensive and unreliable. To address these challenges, we propose 4D-CAAL, a unified framework for 4D radar-camera calibration and auto-labeling. Our approach introduces a novel dual-purpose calibration target design, integrating a checkerboard pattern on the front surface for camera detection and a corner reflector at the center of the back surface for radar detection. We develop a robust correspondence matching algorithm that aligns the checkerboard center with the strongest radar reflection point, enabling accurate extrinsic calibration. Subsequently, we present an auto-labeling pipeline that leverages the calibrated sensor relationship to transfer annotations from camera-based segmentations to radar point clouds through geometric projection and multi-feature optimization. Extensive experiments demonstrate that our method achieves high calibration accuracy while significantly reducing manual annotation effort, thereby accelerating the development of robust multi-modal perception systems for autonomous driving.
MMDrive: Interactive Scene Understanding Beyond Vision with Multi-representational Fusion
Dec 16, 2025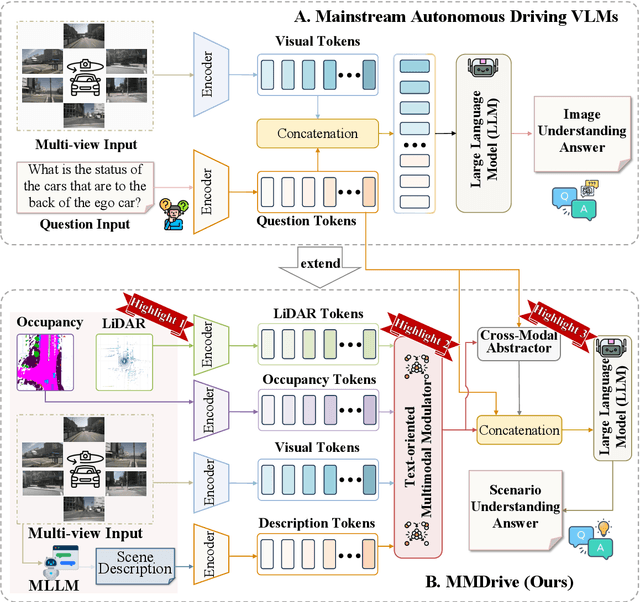
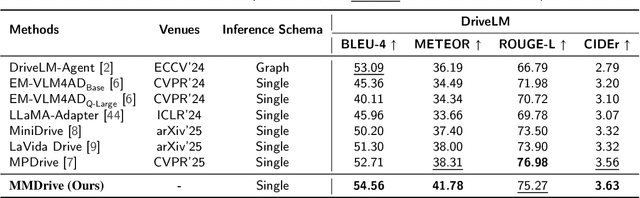


Vision-language models enable the understanding and reasoning of complex traffic scenarios through multi-source information fusion, establishing it as a core technology for autonomous driving. However, existing vision-language models are constrained by the image understanding paradigm in 2D plane, which restricts their capability to perceive 3D spatial information and perform deep semantic fusion, resulting in suboptimal performance in complex autonomous driving environments. This study proposes MMDrive, an multimodal vision-language model framework that extends traditional image understanding to a generalized 3D scene understanding framework. MMDrive incorporates three complementary modalities, including occupancy maps, LiDAR point clouds, and textual scene descriptions. To this end, it introduces two novel components for adaptive cross-modal fusion and key information extraction. Specifically, the Text-oriented Multimodal Modulator dynamically weights the contributions of each modality based on the semantic cues in the question, guiding context-aware feature integration. The Cross-Modal Abstractor employs learnable abstract tokens to generate compact, cross-modal summaries that highlight key regions and essential semantics. Comprehensive evaluations on the DriveLM and NuScenes-QA benchmarks demonstrate that MMDrive achieves significant performance gains over existing vision-language models for autonomous driving, with a BLEU-4 score of 54.56 and METEOR of 41.78 on DriveLM, and an accuracy score of 62.7% on NuScenes-QA. MMDrive effectively breaks the traditional image-only understanding barrier, enabling robust multimodal reasoning in complex driving environments and providing a new foundation for interpretable autonomous driving scene understanding.
GuardFed: A Trustworthy Federated Learning Framework Against Dual-Facet Attacks
Nov 12, 2025Federated learning (FL) enables privacy-preserving collaborative model training but remains vulnerable to adversarial behaviors that compromise model utility or fairness across sensitive groups. While extensive studies have examined attacks targeting either objective, strategies that simultaneously degrade both utility and fairness remain largely unexplored. To bridge this gap, we introduce the Dual-Facet Attack (DFA), a novel threat model that concurrently undermines predictive accuracy and group fairness. Two variants, Synchronous DFA (S-DFA) and Split DFA (Sp-DFA), are further proposed to capture distinct real-world collusion scenarios. Experimental results show that existing robust FL defenses, including hybrid aggregation schemes, fail to resist DFAs effectively. To counter these threats, we propose GuardFed, a self-adaptive defense framework that maintains a fairness-aware reference model using a small amount of clean server data augmented with synthetic samples. In each training round, GuardFed computes a dual-perspective trust score for every client by jointly evaluating its utility deviation and fairness degradation, thereby enabling selective aggregation of trustworthy updates. Extensive experiments on real-world datasets demonstrate that GuardFed consistently preserves both accuracy and fairness under diverse non-IID and adversarial conditions, achieving state-of-the-art performance compared with existing robust FL methods.
An Integrated Fusion Framework for Ensemble Learning Leveraging Gradient Boosting and Fuzzy Rule-Based Models
Nov 11, 2025The integration of different learning paradigms has long been a focus of machine learning research, aimed at overcoming the inherent limitations of individual methods. Fuzzy rule-based models excel in interpretability and have seen widespread application across diverse fields. However, they face challenges such as complex design specifications and scalability issues with large datasets. The fusion of different techniques and strategies, particularly Gradient Boosting, with Fuzzy Rule-Based Models offers a robust solution to these challenges. This paper proposes an Integrated Fusion Framework that merges the strengths of both paradigms to enhance model performance and interpretability. At each iteration, a Fuzzy Rule-Based Model is constructed and controlled by a dynamic factor to optimize its contribution to the overall ensemble. This control factor serves multiple purposes: it prevents model dominance, encourages diversity, acts as a regularization parameter, and provides a mechanism for dynamic tuning based on model performance, thus mitigating the risk of overfitting. Additionally, the framework incorporates a sample-based correction mechanism that allows for adaptive adjustments based on feedback from a validation set. Experimental results substantiate the efficacy of the presented gradient boosting framework for fuzzy rule-based models, demonstrating performance enhancement, especially in terms of mitigating overfitting and complexity typically associated with many rules. By leveraging an optimal factor to govern the contribution of each model, the framework improves performance, maintains interpretability, and simplifies the maintenance and update of the models.
Affine Modulation-based Audiogram Fusion Network for Joint Noise Reduction and Hearing Loss Compensation
Sep 09, 2025



Hearing aids (HAs) are widely used to provide personalized speech enhancement (PSE) services, improving the quality of life for individuals with hearing loss. However, HA performance significantly declines in noisy environments as it treats noise reduction (NR) and hearing loss compensation (HLC) as separate tasks. This separation leads to a lack of systematic optimization, overlooking the interactions between these two critical tasks, and increases the system complexity. To address these challenges, we propose a novel audiogram fusion network, named AFN-HearNet, which simultaneously tackles the NR and HLC tasks by fusing cross-domain audiogram and spectrum features. We propose an audiogram-specific encoder that transforms the sparse audiogram profile into a deep representation, addressing the alignment problem of cross-domain features prior to fusion. To incorporate the interactions between NR and HLC tasks, we propose the affine modulation-based audiogram fusion frequency-temporal Conformer that adaptively fuses these two features into a unified deep representation for speech reconstruction. Furthermore, we introduce a voice activity detection auxiliary training task to embed speech and non-speech patterns into the unified deep representation implicitly. We conduct comprehensive experiments across multiple datasets to validate the effectiveness of each proposed module. The results indicate that the AFN-HearNet significantly outperforms state-of-the-art in-context fusion joint models regarding key metrics such as HASQI and PESQ, achieving a considerable trade-off between performance and efficiency. The source code and data will be released at https://github.com/deepnetni/AFN-HearNet.
MyGO: Make your Goals Obvious, Avoiding Semantic Confusion in Prostate Cancer Lesion Region Segmentation
Jul 23, 2025Early diagnosis and accurate identification of lesion location and progression in prostate cancer (PCa) are critical for assisting clinicians in formulating effective treatment strategies. However, due to the high semantic homogeneity between lesion and non-lesion areas, existing medical image segmentation methods often struggle to accurately comprehend lesion semantics, resulting in the problem of semantic confusion. To address this challenge, we propose a novel Pixel Anchor Module, which guides the model to discover a sparse set of feature anchors that serve to capture and interpret global contextual information. This mechanism enhances the model's nonlinear representation capacity and improves segmentation accuracy within lesion regions. Moreover, we design a self-attention-based Top_k selection strategy to further refine the identification of these feature anchors, and incorporate a focal loss function to mitigate class imbalance, thereby facilitating more precise semantic interpretation across diverse regions. Our method achieves state-of-the-art performance on the PI-CAI dataset, demonstrating 69.73% IoU and 74.32% Dice scores, and significantly improving prostate cancer lesion detection.