 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Oracle Feedback with Vision-Language Embeddings for Preference-Based RL
Mar 30, 2026Preference-based reinforcement learning can learn effective reward functions from comparisons, but its scalability is constrained by the high cost of oracle feedback. Lightweight vision-language embedding (VLE) models provide a cheaper alternative, but their noisy outputs limit their effectiveness as standalone reward generators. To address this challenge, we propose ROVED, a hybrid framework that combines VLE-based supervision with targeted oracle feedback. Our method uses the VLE to generate segment-level preferences and defers to an oracle only for samples with high uncertainty, identified through a filtering mechanism. In addition, we introduce a parameter-efficient fine-tuning method that adapts the VLE with the obtained oracle feedback in order to improve the model over time in a synergistic fashion. This ensures the retention of the scalability of embeddings and the accuracy of oracles, while avoiding their inefficiencies. Across multiple robotic manipulation tasks, ROVED matches or surpasses prior preference-based methods while reducing oracle queries by up to 80%. Remarkably, the adapted VLE generalizes across tasks, yielding cumulative annotation savings of up to 90%, highlighting the practicality of combining scalable embeddings with precise oracle supervision for preference-based RL.
Toward Autonomous Laboratory Safety Monitoring with Vision Language Models: Learning to See Hazards Through Scene Structure
Jan 31, 2026Laboratories are prone to severe injuries from minor unsafe actions, yet continuous safety monitoring -- beyond mandatory pre-lab safety training -- is limited by human availability. Vision language models (VLMs) offer promise for autonomous laboratory safety monitoring, but their effectiveness in realistic settings is unclear due to the lack of visual evaluation data, as most safety incidents are documented primarily as unstructured text. To address this gap, we first introduce a structured data generation pipeline that converts textual laboratory scenarios into aligned triples of (image, scene graph, ground truth), using large language models as scene graph architects and image generation models as renderers. Our experiments on the synthetic dataset of 1,207 samples across 362 unique scenarios and seven open- and closed-source models show that VLMs perform effectively given textual scene graph, but degrade substantially in visual-only settings indicating difficulty in extracting structured object relationships directly from pixels. To overcome this, we propose a post-training context-engineering approach, scene-graph-guided alignment, to bridge perceptual gaps in VLMs by translating visual inputs into structured scene graphs better aligned with VLM reasoning, improving hazard detection performance in visual only settings.
HEAL: An Empirical Study on Hallucinations in Embodied Agents Driven by Large Language Models
Jun 18, 2025



Large language models (LLMs) are increasingly being adopted as the cognitive core of embodied agents. However, inherited hallucinations, which stem from failures to ground user instructions in the observed physical environment, can lead to navigation errors, such as searching for a refrigerator that does not exist. In this paper, we present the first systematic study of hallucinations in LLM-based embodied agents performing long-horizon tasks under scene-task inconsistencies. Our goal is to understand to what extent hallucinations occur, what types of inconsistencies trigger them, and how current models respond. To achieve these goals, we construct a hallucination probing set by building on an existing benchmark, capable of inducing hallucination rates up to 40x higher than base prompts. Evaluating 12 models across two simulation environments, we find that while models exhibit reasoning, they fail to resolve scene-task inconsistencies-highlighting fundamental limitations in handling infeasible tasks. We also provide actionable insights on ideal model behavior for each scenario, offering guidance for developing more robust and reliable planning strategies.
Conformal Prediction and MLLM aided Uncertainty Quantification in Scene Graph Generation
Mar 18, 2025Scene Graph Generation (SGG) aims to represent visual scenes by identifying objects and their pairwise relationships, providing a structured understanding of image content. However, inherent challenges like long-tailed class distributions and prediction variability necessitate uncertainty quantification in SGG for its practical viability. In this paper, we introduce a novel Conformal Prediction (CP) based framework, adaptive to any existing SGG method, for quantifying their predictive uncertainty by constructing well-calibrated prediction sets over their generated scene graphs. These scene graph prediction sets are designed to achieve statistically rigorous coverage guarantees. Additionally, to ensure these prediction sets contain the most practically interpretable scene graphs, we design an effective MLLM-based post-processing strategy for selecting the most visually and semantically plausible scene graphs within these prediction sets. We show that our proposed approach can produce diverse possible scene graphs from an image, assess the reliability of SGG methods, and improve overall SGG performance.
Preference VLM: Leveraging VLMs for Scalable Preference-Based Reinforcement Learning
Feb 03, 2025



Preference-based reinforcement learning (RL) offers a promising approach for aligning policies with human intent but is often constrained by the high cost of human feedback. In this work, we introduce PrefVLM, a framework that integrates Vision-Language Models (VLMs) with selective human feedback to significantly reduce annotation requirements while maintaining performance. Our method leverages VLMs to generate initial preference labels, which are then filtered to identify uncertain cases for targeted human annotation. Additionally, we adapt VLMs using a self-supervised inverse dynamics loss to improve alignment with evolving policies. Experiments on Meta-World manipulation tasks demonstrate that PrefVLM achieves comparable or superior success rates to state-of-the-art methods while using up to 2 x fewer human annotations. Furthermore, we show that adapted VLMs enable efficient knowledge transfer across tasks, further minimizing feedback needs. Our results highlight the potential of combining VLMs with selective human supervision to make preference-based RL more scalable and practical.
Robust Offline Imitation Learning from Diverse Auxiliary Data
Oct 04, 2024



Offline imitation learning enables learning a policy solely from a set of expert demonstrations, without any environment interaction. To alleviate the issue of distribution shift arising due to the small amount of expert data, recent works incorporate large numbers of auxiliary demonstrations alongside the expert data. However, the performance of these approaches rely on assumptions about the quality and composition of the auxiliary data. However, they are rarely successful when those assumptions do not hold. To address this limitation, we propose Robust Offline Imitation from Diverse Auxiliary Data (ROIDA). ROIDA first identifies high-quality transitions from the entire auxiliary dataset using a learned reward function. These high-reward samples are combined with the expert demonstrations for weighted behavioral cloning. For lower-quality samples, ROIDA applies temporal difference learning to steer the policy towards high-reward states, improving long-term returns. This two-pronged approach enables our framework to effectively leverage both high and low-quality data without any assumptions. Extensive experiments validate that ROIDA achieves robust and consistent performance across multiple auxiliary datasets with diverse ratios of expert and non-expert demonstrations. ROIDA effectively leverages unlabeled auxiliary data, outperforming prior methods reliant on specific data assumptions.
A data balancing approach towards design of an expert system for Heart Disease Prediction
Jul 29, 2024



Heart disease is a serious global health issue that claims millions of lives every year. Early detection and precise prediction are critical to the prevention and successful treatment of heart related issues. A lot of research utilizes machine learning (ML) models to forecast cardiac disease and obtain early detection. In order to do predictive analysis on "Heart disease health indicators " dataset. We employed five machine learning methods in this paper: Decision Tree (DT), Random Forest (RF), Linear Discriminant Analysis, Extra Tree Classifier, and AdaBoost. The model is further examined using various feature selection (FS) techniques. To enhance the baseline model, we have separately applied four FS techniques: Sequential Forward FS, Sequential Backward FS, Correlation Matrix, and Chi2. Lastly, K means SMOTE oversampling is applied to the models to enable additional analysis. The findings show that when it came to predicting heart disease, ensemble approaches in particular, random forests performed better than individual classifiers. The presence of smoking, blood pressure, cholesterol, and physical inactivity were among the major predictors that were found. The accuracy of the Random Forest and Decision Tree model was 99.83%. This paper demonstrates how machine learning models can improve the accuracy of heart disease prediction, especially when using ensemble methodologies. The models provide a more accurate risk assessment than traditional methods since they incorporate a large number of factors and complex algorithms.
Deciphering Environmental Air Pollution with Large Scale City Data
Sep 09, 2021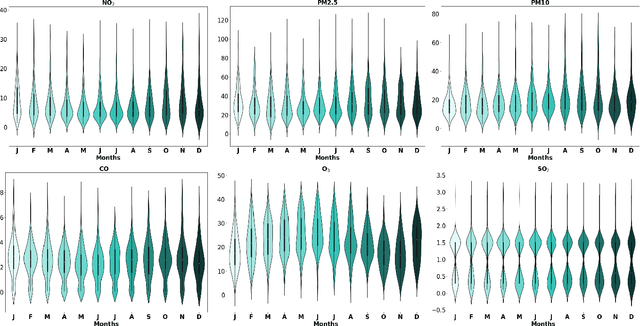
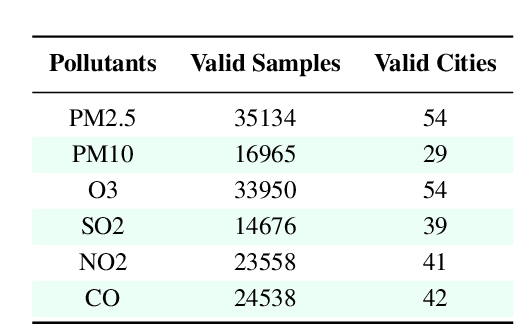
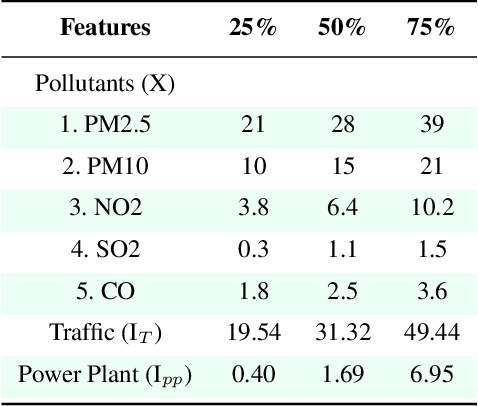
Out of the numerous hazards posing a threat to sustainable environmental conditions in the 21st century, only a few have a graver impact than air pollution. Its importance in determining the health and living standards in urban settings is only expected to increase with time. Various factors ranging from emissions from traffic and power plants, household emissions, natural causes are known to be primary causal agents or influencers behind rising air pollution levels. However, the lack of large scale data involving the major factors has hindered the research on the causes and relations governing the variability of the different air pollutants. Through this work, we introduce a large scale city-wise dataset for exploring the relationships among these agents over a long period of time. We analyze and explore the dataset to bring out inferences which we can derive by modeling the data. Also, we provide a set of benchmarks for the problem of estimating or forecasting pollutant levels with a set of diverse models and methodologies. Through our paper, we seek to provide a ground base for further research into this domain that will demand critical attention of ours in the near future.