 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels Don't Lie (But Your Detector Might): Bootstrapping MLLM-as-a-Judge for Trustworthy Deepfake Detection and Reasoning Supervision
Feb 23, 2026Deepfake detection models often generate natural-language explanations, yet their reasoning is frequently ungrounded in visual evidence, limiting reliability. Existing evaluations measure classification accuracy but overlook reasoning fidelity. We propose DeepfakeJudge, a framework for scalable reasoning supervision and evaluation, that integrates an out-of-distribution benchmark containing recent generative and editing forgeries, a human-annotated subset with visual reasoning labels, and a suite of evaluation models, that specialize in evaluating reasoning rationales without the need for explicit ground truth reasoning rationales. The Judge is optimized through a bootstrapped generator-evaluator process that scales human feedback into structured reasoning supervision and supports both pointwise and pairwise evaluation. On the proposed meta-evaluation benchmark, our reasoning-bootstrapped model achieves an accuracy of 96.2\%, outperforming \texttt{30x} larger baselines. The reasoning judge attains very high correlation with human ratings and 98.9\% percent pairwise agreement on the human-annotated meta-evaluation subset. These results establish reasoning fidelity as a quantifiable dimension of deepfake detection and demonstrate scalable supervision for interpretable deepfake reasoning. Our user study shows that participants preferred the reasonings generated by our framework 70\% of the time, in terms of faithfulness, groundedness, and usefulness, compared to those produced by other models and datasets. All of our datasets, models, and codebase are \href{https://github.com/KjAeRsTuIsK/DeepfakeJudge}{open-sourced}.
VFace: A Training-Free Approach for Diffusion-Based Video Face Swapping
Feb 08, 2026We present a training-free, plug-and-play method, namely VFace, for high-quality face swapping in videos. It can be seamlessly integrated with image-based face swapping approaches built on diffusion models. First, we introduce a Frequency Spectrum Attention Interpolation technique to facilitate generation and intact key identity characteristics. Second, we achieve Target Structure Guidance via plug-and-play attention injection to better align the structural features from the target frame to the generation. Third, we present a Flow-Guided Attention Temporal Smoothening mechanism that enforces spatiotemporal coherence without modifying the underlying diffusion model to reduce temporal inconsistencies typically encountered in frame-wise generation. Our method requires no additional training or video-specific fine-tuning. Extensive experiments show that our method significantly enhances temporal consistency and visual fidelity, offering a practical and modular solution for video-based face swapping. Our code is available at https://github.com/Sanoojan/VFace.
Investigating the Viability of Employing Multi-modal Large Language Models in the Context of Audio Deepfake Detection
Jan 02, 2026While Vision-Language Models (VLMs) and Multimodal Large Language Models (MLLMs) have shown strong generalisation in detecting image and video deepfakes, their use for audio deepfake detection remains largely unexplored. In this work, we aim to explore the potential of MLLMs for audio deepfake detection. Combining audio inputs with a range of text prompts as queries to find out the viability of MLLMs to learn robust representations across modalities for audio deepfake detection. Therefore, we attempt to explore text-aware and context-rich, question-answer based prompts with binary decisions. We hypothesise that such a feature-guided reasoning will help in facilitating deeper multimodal understanding and enable robust feature learning for audio deepfake detection. We evaluate the performance of two MLLMs, Qwen2-Audio-7B-Instruct and SALMONN, in two evaluation modes: (a) zero-shot and (b) fine-tuned. Our experiments demonstrate that combining audio with a multi-prompt approach could be a viable way forward for audio deepfake detection. Our experiments show that the models perform poorly without task-specific training and struggle to generalise to out-of-domain data. However, they achieve good performance on in-domain data with minimal supervision, indicating promising potential for audio deepfake detection.
A Survey of Body and Face Motion: Datasets, Performance Evaluation Metrics and Generative Techniques
Dec 09, 2025



Body and face motion play an integral role in communication. They convey crucial information on the participants. Advances in generative modeling and multi-modal learning have enabled motion generation from signals such as speech, conversational context and visual cues. However, generating expressive and coherent face and body dynamics remains challenging due to the complex interplay of verbal / non-verbal cues and individual personality traits. This survey reviews body and face motion generation, covering core concepts, representations techniques, generative approaches, datasets and evaluation metrics. We highlight future directions to enhance the realism, coherence and expressiveness of avatars in dyadic settings. To the best of our knowledge, this work is the first comprehensive review to cover both body and face motion. Detailed resources are listed on https://lownish23csz0010.github.io/mogen/.
CSGaze: Context-aware Social Gaze Prediction
Nov 14, 2025A person's gaze offers valuable insights into their focus of attention, level of social engagement, and confidence. In this work, we investigate how contextual cues combined with visual scene and facial information can be effectively utilized to predict and interpret social gaze patterns during conversational interactions. We introduce CSGaze, a context aware multimodal approach that leverages facial, scene information as complementary inputs to enhance social gaze pattern prediction from multi-person images. The model also incorporates a fine-grained attention mechanism centered on the principal speaker, which helps in better modeling social gaze dynamics. Experimental results show that CSGaze performs competitively with state-of-the-art methods on GP-Static, UCO-LAEO and AVA-LAEO. Our findings highlight the role of contextual cues in improving social gaze prediction. Additionally, we provide initial explainability through generated attention scores, offering insights into the model's decision-making process. We also demonstrate our model's generalizability by testing our model on open set datasets that demonstrating its robustness across diverse scenarios.
A Multi-Modal Neuro-Symbolic Approach for Spatial Reasoning-Based Visual Grounding in Robotics
Oct 30, 2025
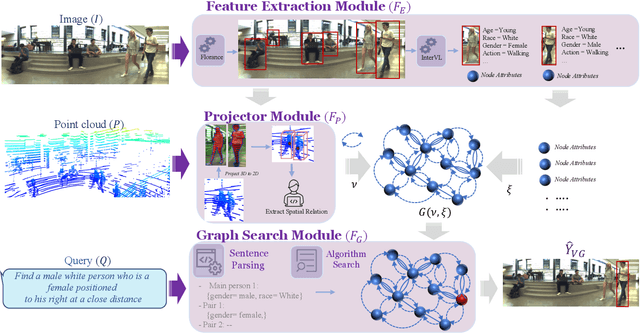


Visual reasoning, particularly spatial reasoning, is a challenging cognitive task that requires understanding object relationships and their interactions within complex environments, especially in robotics domain. Existing vision_language models (VLMs) excel at perception tasks but struggle with fine-grained spatial reasoning due to their implicit, correlation-driven reasoning and reliance solely on images. We propose a novel neuro_symbolic framework that integrates both panoramic-image and 3D point cloud information, combining neural perception with symbolic reasoning to explicitly model spatial and logical relationships. Our framework consists of a perception module for detecting entities and extracting attributes, and a reasoning module that constructs a structured scene graph to support precise, interpretable queries. Evaluated on the JRDB-Reasoning dataset, our approach demonstrates superior performance and reliability in crowded, human_built environments while maintaining a lightweight design suitable for robotics and embodied AI applications.
Gems: Group Emotion Profiling Through Multimodal Situational Understanding
Jul 30, 2025Understanding individual, group and event level emotions along with contextual information is crucial for analyzing a multi-person social situation. To achieve this, we frame emotion comprehension as the task of predicting fine-grained individual emotion to coarse grained group and event level emotion. We introduce GEMS that leverages a multimodal swin-transformer and S3Attention based architecture, which processes an input scene, group members, and context information to generate joint predictions. Existing multi-person emotion related benchmarks mainly focus on atomic interactions primarily based on emotion perception over time and group level. To this end, we extend and propose VGAF-GEMS to provide more fine grained and holistic analysis on top of existing group level annotation of VGAF dataset. GEMS aims to predict basic discrete and continuous emotions (including valence and arousal) as well as individual, group and event level perceived emotions. Our benchmarking effort links individual, group and situational emotional responses holistically. The quantitative and qualitative comparisons with adapted state-of-the-art models demonstrate the effectiveness of GEMS framework on VGAF-GEMS benchmarking. We believe that it will pave the way of further research. The code and data is available at: https://github.com/katariaak579/GEMS
AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Jul 28, 2025



The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
Tell me Habibi, is it Real or Fake?
May 28, 2025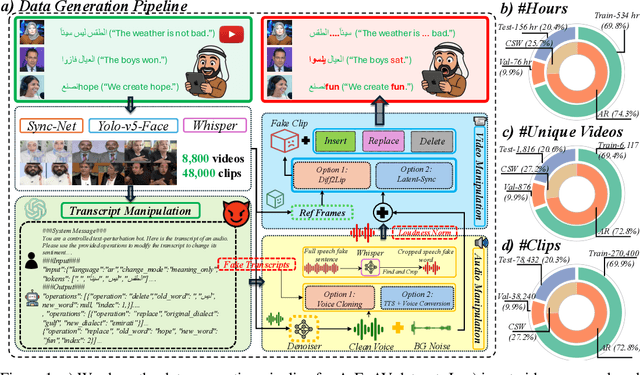
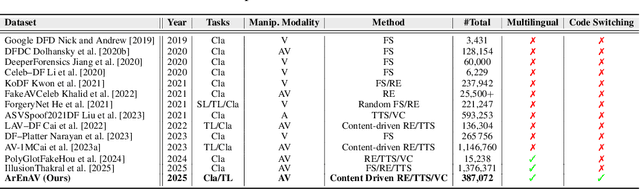
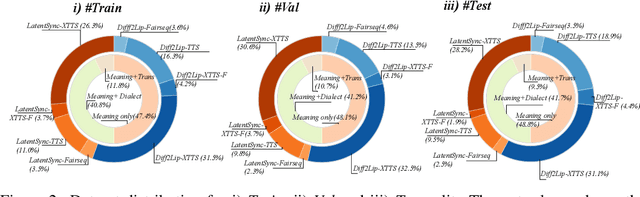

Deepfake generation methods are evolving fast, making fake media harder to detect and raising serious societal concerns. Most deepfake detection and dataset creation research focuses on monolingual content, often overlooking the challenges of multilingual and code-switched speech, where multiple languages are mixed within the same discourse. Code-switching, especially between Arabic and English, is common in the Arab world and is widely used in digital communication. This linguistic mixing poses extra challenges for deepfake detection, as it can confuse models trained mostly on monolingual data. To address this, we introduce \textbf{ArEnAV}, the first large-scale Arabic-English audio-visual deepfake dataset featuring intra-utterance code-switching, dialectal variation, and monolingual Arabic content. It \textbf{contains 387k videos and over 765 hours of real and fake videos}. Our dataset is generated using a novel pipeline integrating four Text-To-Speech and two lip-sync models, enabling comprehensive analysis of multilingual multimodal deepfake detection. We benchmark our dataset against existing monolingual and multilingual datasets, state-of-the-art deepfake detection models, and a human evaluation, highlighting its potential to advance deepfake research. The dataset can be accessed \href{https://huggingface.co/datasets/kartik060702/ArEnAV-Full}{here}.
MAVEN: Multi-modal Attention for Valence-Arousal Emotion Network
Mar 16, 2025This paper introduces MAVEN (Multi-modal Attention for Valence-Arousal Emotion Network), a novel architecture for dynamic emotion recognition through dimensional modeling of affect. The model uniquely integrates visual, audio, and textual modalities via a bi-directional cross-modal attention mechanism with six distinct attention pathways, enabling comprehensive interactions between all modality pairs. Our proposed approach employs modality-specific encoders to extract rich feature representations from synchronized video frames, audio segments, and transcripts. The architecture's novelty lies in its cross-modal enhancement strategy, where each modality representation is refined through weighted attention from other modalities, followed by self-attention refinement through modality-specific encoders. Rather than directly predicting valence-arousal values, MAVEN predicts emotions in a polar coordinate form, aligning with psychological models of the emotion circumplex. Experimental evaluation on the Aff-Wild2 dataset demonstrates the effectiveness of our approach, with performance measured using Concordance Correlation Coefficient (CCC). The multi-stage architecture demonstrates superior ability to capture the complex, nuanced nature of emotional expressions in conversational videos, advancing the state-of-the-art (SOTA) in continuous emotion recognition in-the-wild. Code can be found at: https://github.com/Vrushank-Ahire/MAVEN_8th_ABAW.