 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking Style Synthesis
Papers and Code
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
ReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesis
Jan 07, 2026Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
MemoryTalker: Personalized Speech-Driven 3D Facial Animation via Audio-Guided Stylization
Jul 28, 2025Speech-driven 3D facial animation aims to synthesize realistic facial motion sequences from given audio, matching the speaker's speaking style. However, previous works often require priors such as class labels of a speaker or additional 3D facial meshes at inference, which makes them fail to reflect the speaking style and limits their practical use. To address these issues, we propose MemoryTalker which enables realistic and accurate 3D facial motion synthesis by reflecting speaking style only with audio input to maximize usability in applications. Our framework consists of two training stages: 1-stage is storing and retrieving general motion (i.e., Memorizing), and 2-stage is to perform the personalized facial motion synthesis (i.e., Animating) with the motion memory stylized by the audio-driven speaking style feature. In this second stage, our model learns about which facial motion types should be emphasized for a particular piece of audio. As a result, our MemoryTalker can generate a reliable personalized facial animation without additional prior information. With quantitative and qualitative evaluations, as well as user study, we show the effectiveness of our model and its performance enhancement for personalized facial animation over state-of-the-art methods.
Voice Conversion for Likability Control via Automated Rating of Speech Synthesis Corpora
Jul 02, 2025Perceived voice likability plays a crucial role in various social interactions, such as partner selection and advertising. A system that provides reference likable voice samples tailored to target audiences would enable users to adjust their speaking style and voice quality, facilitating smoother communication. To this end, we propose a voice conversion method that controls the likability of input speech while preserving both speaker identity and linguistic content. To improve training data scalability, we train a likability predictor on an existing voice likability dataset and employ it to automatically annotate a large speech synthesis corpus with likability ratings. Experimental evaluations reveal a significant correlation between the predictor's outputs and human-provided likability ratings. Subjective and objective evaluations further demonstrate that the proposed approach effectively controls voice likability while preserving both speaker identity and linguistic content.
GSA-TTS : Toward Zero-Shot Speech Synthesis based on Gradual Style Adaptor
May 26, 2025We present the gradual style adaptor TTS (GSA-TTS) with a novel style encoder that gradually encodes speaking styles from an acoustic reference for zero-shot speech synthesis. GSA first captures the local style of each semantic sound unit. Then the local styles are combined by self-attention to obtain a global style condition. This semantic and hierarchical encoding strategy provides a robust and rich style representation for an acoustic model. We test GSA-TTS on unseen speakers and obtain promising results regarding naturalness, speaker similarity, and intelligibility. Additionally, we explore the potential of GSA in terms of interpretability and controllability, which stems from its hierarchical structure.
LLM-Synth4KWS: Scalable Automatic Generation and Synthesis of Confusable Data for Custom Keyword Spotting
May 29, 2025



Custom keyword spotting (KWS) allows detecting user-defined spoken keywords from streaming audio. This is achieved by comparing the embeddings from voice enrollments and input audio. State-of-the-art custom KWS models are typically trained contrastively using utterances whose keywords are randomly sampled from training dataset. These KWS models often struggle with confusing keywords, such as "blue" versus "glue". This paper introduces an effective way to augment the training with confusable utterances where keywords are generated and grouped from large language models (LLMs), and speech signals are synthesized with diverse speaking styles from text-to-speech (TTS) engines. To better measure user experience on confusable KWS, we define a new northstar metric using the average area under DET curve from confusable groups (c-AUC). Featuring high scalability and zero labor cost, the proposed method improves AUC by 3.7% and c-AUC by 11.3% on the Speech Commands testing set.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025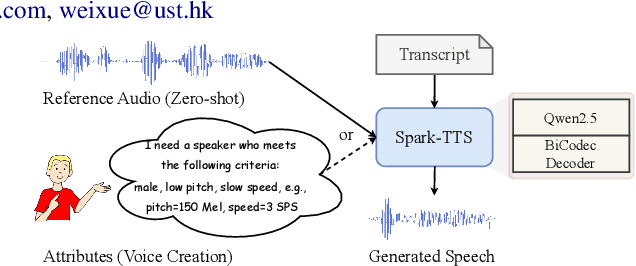



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
NeRF-3DTalker: Neural Radiance Field with 3D Prior Aided Audio Disentanglement for Talking Head Synthesis
Feb 20, 2025Talking head synthesis is to synthesize a lip-synchronized talking head video using audio. Recently, the capability of NeRF to enhance the realism and texture details of synthesized talking heads has attracted the attention of researchers. However, most current NeRF methods based on audio are exclusively concerned with the rendering of frontal faces. These methods are unable to generate clear talking heads in novel views. Another prevalent challenge in current 3D talking head synthesis is the difficulty in aligning acoustic and visual spaces, which often results in suboptimal lip-syncing of the generated talking heads. To address these issues, we propose Neural Radiance Field with 3D Prior Aided Audio Disentanglement for Talking Head Synthesis (NeRF-3DTalker). Specifically, the proposed method employs 3D prior information to synthesize clear talking heads with free views. Additionally, we propose a 3D Prior Aided Audio Disentanglement module, which is designed to disentangle the audio into two distinct categories: features related to 3D awarded speech movements and features related to speaking style. Moreover, to reposition the generated frames that are distant from the speaker's motion space in the real space, we have devised a local-global Standardized Space. This method normalizes the irregular positions in the generated frames from both global and local semantic perspectives. Through comprehensive qualitative and quantitative experiments, it has been demonstrated that our NeRF-3DTalker outperforms state-of-the-art in synthesizing realistic talking head videos, exhibiting superior image quality and lip synchronization. Project page: https://nerf-3dtalker.github.io/NeRF-3Dtalker.
Generative Expressive Conversational Speech Synthesis
Aug 01, 2024



Conversational Speech Synthesis (CSS) aims to express a target utterance with the proper speaking style in a user-agent conversation setting. Existing CSS methods employ effective multi-modal context modeling techniques to achieve empathy understanding and expression. However, they often need to design complex network architectures and meticulously optimize the modules within them. In addition, due to the limitations of small-scale datasets containing scripted recording styles, they often fail to simulate real natural conversational styles. To address the above issues, we propose a novel generative expressive CSS system, termed GPT-Talker.We transform the multimodal information of the multi-turn dialogue history into discrete token sequences and seamlessly integrate them to form a comprehensive user-agent dialogue context. Leveraging the power of GPT, we predict the token sequence, that includes both semantic and style knowledge, of response for the agent. After that, the expressive conversational speech is synthesized by the conversation-enriched VITS to deliver feedback to the user.Furthermore, we propose a large-scale Natural CSS Dataset called NCSSD, that includes both naturally recorded conversational speech in improvised styles and dialogues extracted from TV shows. It encompasses both Chinese and English languages, with a total duration of 236 hours.We conducted comprehensive experiments on the reliability of the NCSSD and the effectiveness of our GPT-Talker. Both subjective and objective evaluations demonstrate that our model outperforms other state-of-the-art CSS systems significantly in terms of naturalness and expressiveness. The Code, Dataset, and Pre-trained Model are available at: https://github.com/AI-S2-Lab/GPT-Talker.
Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
May 16, 2024



Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.