Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSA-TTS : Toward Zero-Shot Speech Synthesis based on Gradual Style Adaptor
Paper and Code


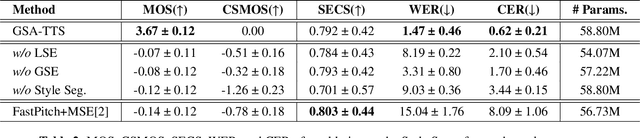

We present the gradual style adaptor TTS (GSA-TTS) with a novel style encoder that gradually encodes speaking styles from an acoustic reference for zero-shot speech synthesis. GSA first captures the local style of each semantic sound unit. Then the local styles are combined by self-attention to obtain a global style condition. This semantic and hierarchical encoding strategy provides a robust and rich style representation for an acoustic model. We test GSA-TTS on unseen speakers and obtain promising results regarding naturalness, speaker similarity, and intelligibility. Additionally, we explore the potential of GSA in terms of interpretability and controllability, which stems from its hierarchical structure.
* 7 pages, 3 figures
View paper on