 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSA-TTS : Toward Zero-Shot Speech Synthesis based on Gradual Style Adaptor
May 26, 2025

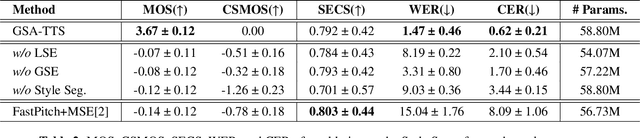

We present the gradual style adaptor TTS (GSA-TTS) with a novel style encoder that gradually encodes speaking styles from an acoustic reference for zero-shot speech synthesis. GSA first captures the local style of each semantic sound unit. Then the local styles are combined by self-attention to obtain a global style condition. This semantic and hierarchical encoding strategy provides a robust and rich style representation for an acoustic model. We test GSA-TTS on unseen speakers and obtain promising results regarding naturalness, speaker similarity, and intelligibility. Additionally, we explore the potential of GSA in terms of interpretability and controllability, which stems from its hierarchical structure.
Improving Robustness of Diffusion-Based Zero-Shot Speech Synthesis via Stable Formant Generation
Sep 14, 2024



Diffusion models have achieved remarkable success in text-to-speech (TTS), even in zero-shot scenarios. Recent efforts aim to address the trade-off between inference speed and sound quality, often considered the primary drawback of diffusion models. However, we find a critical mispronunciation issue is being overlooked. Our preliminary study reveals the unstable pronunciation resulting from the diffusion process. Based on this observation, we introduce StableForm-TTS, a novel zero-shot speech synthesis framework designed to produce robust pronunciation while maintaining the advantages of diffusion modeling. By pioneering the adoption of source-filter theory in diffusion TTS, we propose an elaborate architecture for stable formant generation. Experimental results on unseen speakers show that our model outperforms the state-of-the-art method in terms of pronunciation accuracy and naturalness, with comparable speaker similarity. Moreover, our model demonstrates effective scalability as both data and model sizes increase.