 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePytorch Kaldi
PyTorch Kaldi is a toolkit for speech recognition that integrates PyTorch and Kaldi for building end-to-end speech recognition systems.
Papers and Code
ESPnet-EZ: Python-only ESPnet for Easy Fine-tuning and Integration
Sep 14, 2024We introduce ESPnet-EZ, an extension of the open-source speech processing toolkit ESPnet, aimed at quick and easy development of speech models. ESPnet-EZ focuses on two major aspects: (i) easy fine-tuning and inference of existing ESPnet models on various tasks and (ii) easy integration with popular deep neural network frameworks such as PyTorch-Lightning, Hugging Face transformers and datasets, and Lhotse. By replacing ESPnet design choices inherited from Kaldi with a Python-only, Bash-free interface, we dramatically reduce the effort required to build, debug, and use a new model. For example, to fine-tune a speech foundation model, ESPnet-EZ, compared to ESPnet, reduces the number of newly written code by 2.7x and the amount of dependent code by 6.7x while dramatically reducing the Bash script dependencies. The codebase of ESPnet-EZ is publicly available.
Normalizing Flow based Hidden Markov Models for Classification of Speech Phones with Explainability
Jul 01, 2021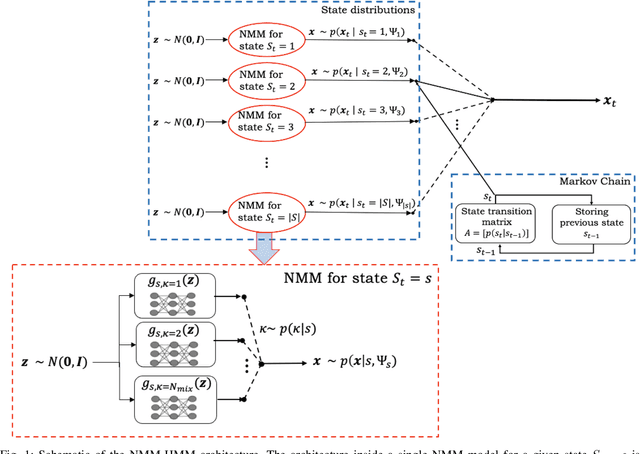
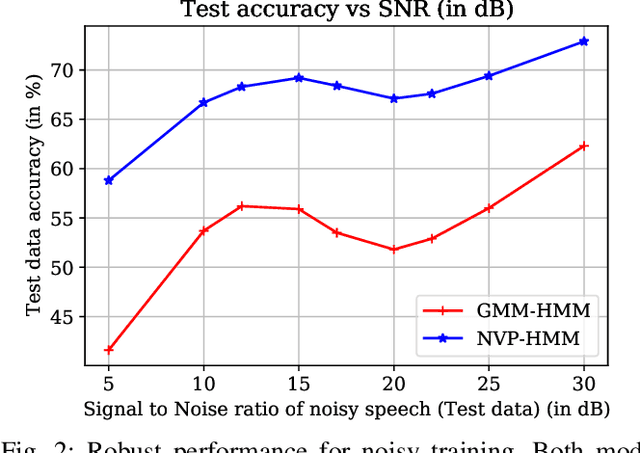
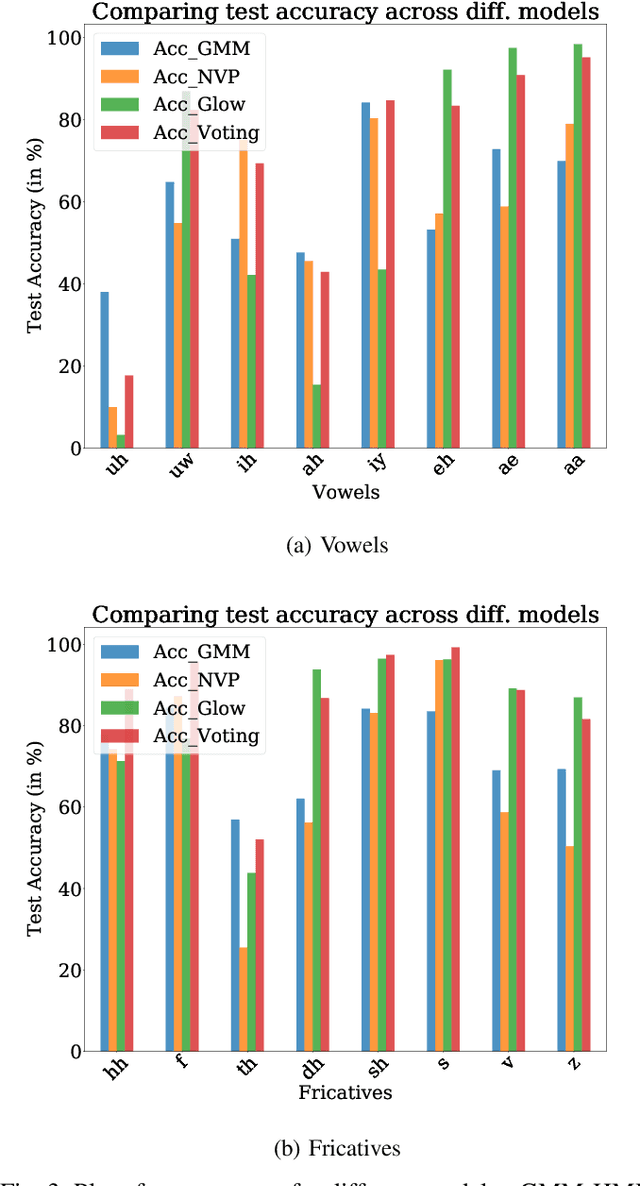

In pursuit of explainability, we develop generative models for sequential data. The proposed models provide state-of-the-art classification results and robust performance for speech phone classification. We combine modern neural networks (normalizing flows) and traditional generative models (hidden Markov models - HMMs). Normalizing flow-based mixture models (NMMs) are used to model the conditional probability distribution given the hidden state in the HMMs. Model parameters are learned through judicious combinations of time-tested Bayesian learning methods and contemporary neural network learning methods. We mainly combine expectation-maximization (EM) and mini-batch gradient descent. The proposed generative models can compute likelihood of a data and hence directly suitable for maximum-likelihood (ML) classification approach. Due to structural flexibility of HMMs, we can use different normalizing flow models. This leads to different types of HMMs providing diversity in data modeling capacity. The diversity provides an opportunity for easy decision fusion from different models. For a standard speech phone classification setup involving 39 phones (classes) and the TIMIT dataset, we show that the use of standard features called mel-frequency-cepstral-coeffcients (MFCCs), the proposed generative models, and the decision fusion together can achieve $86.6\%$ accuracy by generative training only. This result is close to state-of-the-art results, for examples, $86.2\%$ accuracy of PyTorch-Kaldi toolkit [1], and $85.1\%$ accuracy using light gated recurrent units [2]. We do not use any discriminative learning approach and related sophisticated features in this article.
A Parallelizable Lattice Rescoring Strategy with Neural Language Models
Mar 08, 2021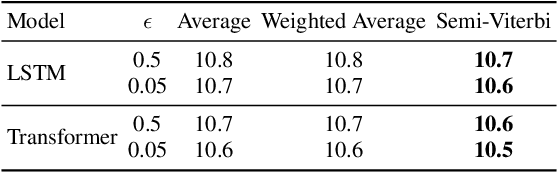
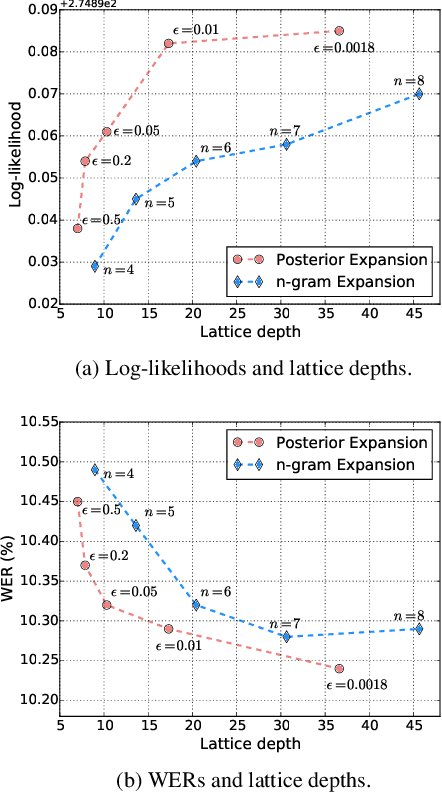

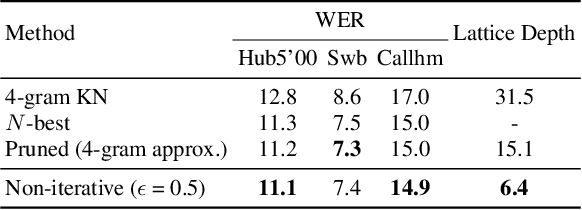
This paper proposes a parallel computation strategy and a posterior-based lattice expansion algorithm for efficient lattice rescoring with neural language models (LMs) for automatic speech recognition. First, lattices from first-pass decoding are expanded by the proposed posterior-based lattice expansion algorithm. Second, each expanded lattice is converted into a minimal list of hypotheses that covers every arc. Each hypothesis is constrained to be the best path for at least one arc it includes. For each lattice, the neural LM scores of the minimal list are computed in parallel and are then integrated back to the lattice in the rescoring stage. Experiments on the Switchboard dataset show that the proposed rescoring strategy obtains comparable recognition performance and generates more compact lattices than a competitive baseline method. Furthermore, the parallel rescoring method offers more flexibility by simplifying the integration of PyTorch-trained neural LMs for lattice rescoring with Kaldi.
PyChain: A Fully Parallelized PyTorch Implementation of LF-MMI for End-to-End ASR
May 20, 2020
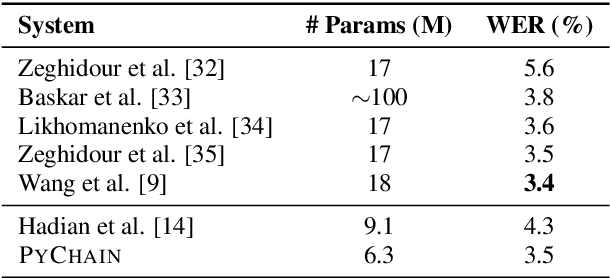

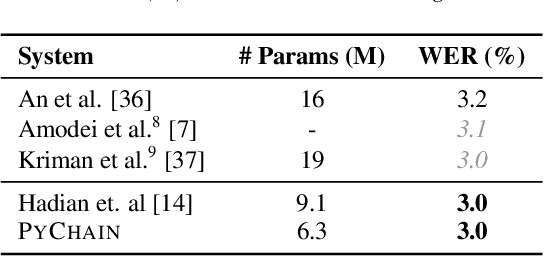
We present PyChain, a fully parallelized PyTorch implementation of end-to-end lattice-free maximum mutual information (LF-MMI) training for the so-called \emph{chain models} in the Kaldi automatic speech recognition (ASR) toolkit. Unlike other PyTorch and Kaldi based ASR toolkits, PyChain is designed to be as flexible and light-weight as possible so that it can be easily plugged into new ASR projects, or other existing PyTorch-based ASR tools, as exemplified respectively by a new project PyChain-example, and Espresso, an existing end-to-end ASR toolkit. PyChain's efficiency and flexibility is demonstrated through such novel features as full GPU training on numerator/denominator graphs, and support for unequal length sequences. Experiments on the WSJ dataset show that with simple neural networks and commonly used machine learning techniques, PyChain can achieve competitive results that are comparable to Kaldi and better than other end-to-end ASR systems.
Lhotse: a speech data representation library for the modern deep learning ecosystem
Oct 25, 2021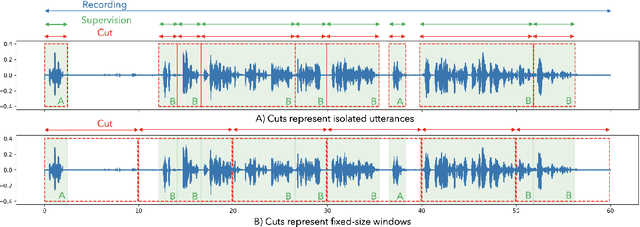
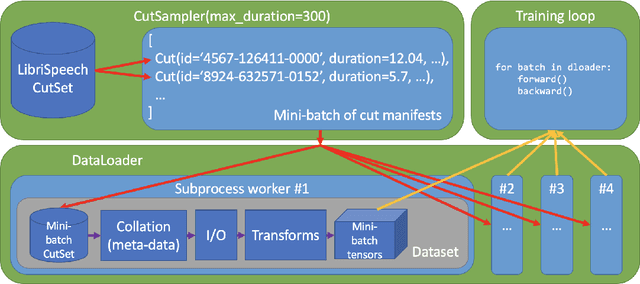
Speech data is notoriously difficult to work with due to a variety of codecs, lengths of recordings, and meta-data formats. We present Lhotse, a speech data representation library that draws upon lessons learned from Kaldi speech recognition toolkit and brings its concepts into the modern deep learning ecosystem. Lhotse provides a common JSON description format with corresponding Python classes and data preparation recipes for over 30 popular speech corpora. Various datasets can be easily combined together and re-purposed for different tasks. The library handles multi-channel recordings, long recordings, local and cloud storage, lazy and on-the-fly operations amongst other features. We introduce Cut and CutSet concepts, which simplify common data wrangling tasks for audio and help incorporate acoustic context of speech utterances. Finally, we show how Lhotse leverages PyTorch data API abstractions and adopts them to handle speech data for deep learning.
AP20-OLR Challenge: Three Tasks and Their Baselines
Jun 04, 2020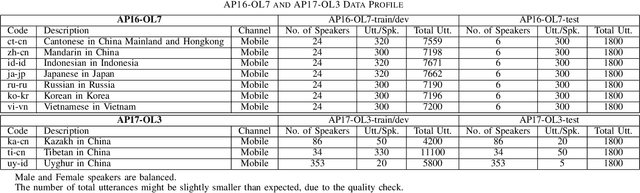
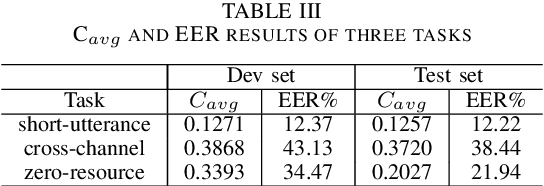
This paper introduces the fifth oriental language recognition (OLR) challenge AP20-OLR, which intends to improve the performance of language recognition systems, along with APSIPA Annual Summit and Conference (APSIPA ASC). The data profile, three tasks, the corresponding baselines, and the evaluation principles are introduced in this paper. The AP20-OLR challenge includes more languages, dialects and real-life data provided by Speechocean and the NSFC M2ASR project, and all the data is free for participants. The challenge this year still focuses on practical and challenging problems, with three tasks: (1) cross-channel LID, (2) dialect identification and (3) noisy LID. Based on Kaldi and Pytorch, recipes for i-vector and x-vector systems are also conducted as baselines for the three tasks. These recipes will be online-published, and available for participants to configure LID systems. The baseline results on the three tasks demonstrate that those tasks in this challenge are worth paying more efforts to achieve better performance.
PyKaldi2: Yet another speech toolkit based on Kaldi and PyTorch
Jul 30, 2019


We introduce PyKaldi2 speech recognition toolkit implemented based on Kaldi and PyTorch. While similar toolkits are available built on top of the two, a key feature of PyKaldi2 is sequence training with criteria such as MMI, sMBR and MPE. In particular, we implemented the sequence training module with on-the-fly lattice generation during model training in order to simplify the training pipeline. To address the challenging acoustic environments in real applications, PyKaldi2 also supports on-the-fly noise and reverberation simulation to improve the model robustness. With this feature, it is possible to backpropogate the gradients from the sequence-level loss to the front-end feature extraction module, which, hopefully, can foster more research in the direction of joint front-end and backend learning. We performed benchmark experiments on Librispeech, and show that PyKaldi2 can achieve reasonable recognition accuracy. The toolkit is released under the MIT license.
The PyTorch-Kaldi Speech Recognition Toolkit
Nov 19, 2018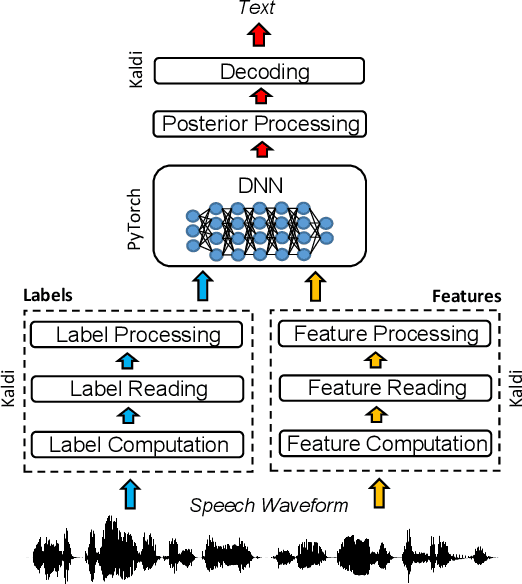
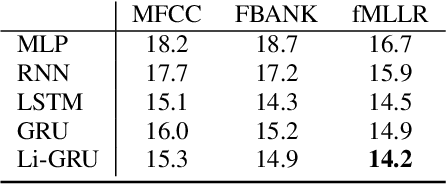

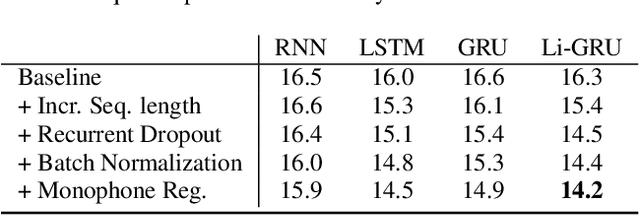
The availability of open-source software is playing a remarkable role in the popularization of speech recognition and deep learning. Kaldi, for instance, is nowadays an established framework used to develop state-of-the-art speech recognizers. PyTorch is used to build neural networks with the Python language and has recently spawn tremendous interest within the machine learning community thanks to its simplicity and flexibility. The PyTorch-Kaldi project aims to bridge the gap between these popular toolkits, trying to inherit the efficiency of Kaldi and the flexibility of PyTorch. PyTorch-Kaldi is not only a simple interface between these software, but it embeds several useful features for developing modern speech recognizers. For instance, the code is specifically designed to naturally plug-in user-defined acoustic models. As an alternative, users can exploit several pre-implemented neural networks that can be customized using intuitive configuration files. PyTorch-Kaldi supports multiple feature and label streams as well as combinations of neural networks, enabling the use of complex neural architectures. The toolkit is publicly-released along with a rich documentation and is designed to properly work locally or on HPC clusters. Experiments, that are conducted on several datasets and tasks, show that PyTorch-Kaldi can effectively be used to develop modern state-of-the-art speech recognizers.
ESPnet: End-to-End Speech Processing Toolkit
Mar 30, 2018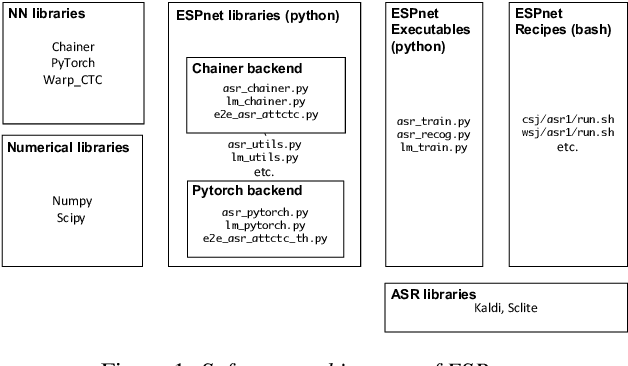
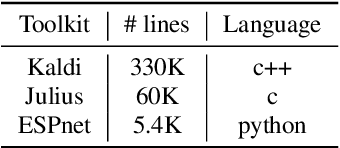
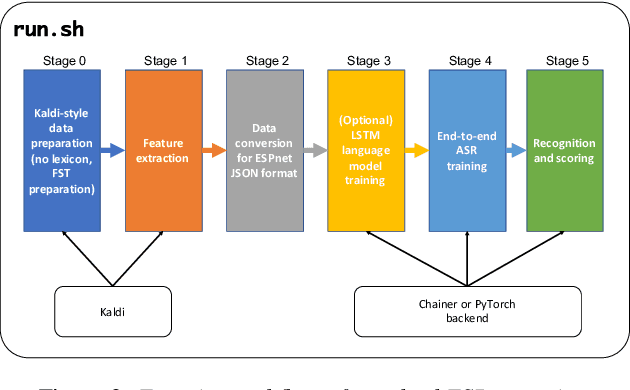
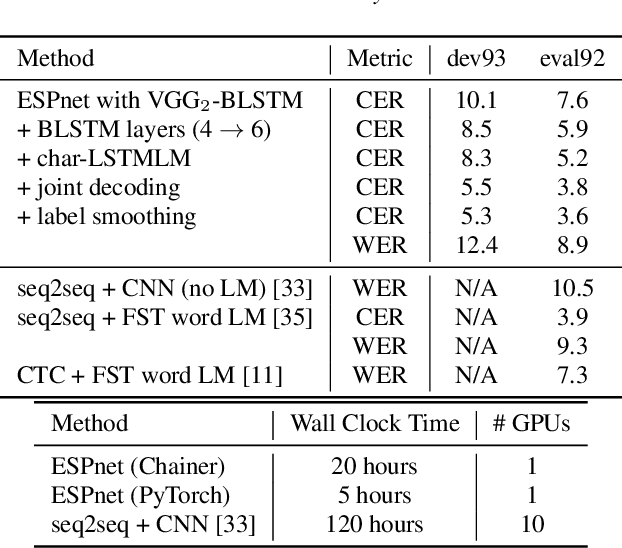
This paper introduces a new open source platform for end-to-end speech processing named ESPnet. ESPnet mainly focuses on end-to-end automatic speech recognition (ASR), and adopts widely-used dynamic neural network toolkits, Chainer and PyTorch, as a main deep learning engine. ESPnet also follows the Kaldi ASR toolkit style for data processing, feature extraction/format, and recipes to provide a complete setup for speech recognition and other speech processing experiments. This paper explains a major architecture of this software platform, several important functionalities, which differentiate ESPnet from other open source ASR toolkits, and experimental results with major ASR benchmarks.