 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Frequency-Attention Alternative to CNN Frontends for Automatic Speech Recognition
Jun 12, 2023



Convolutional frontends are a typical choice for Transformer-based automatic speech recognition to preprocess the spectrogram, reduce its sequence length, and combine local information in time and frequency similarly. However, the width and height of an audio spectrogram denote different information, e.g., due to reverberation as well as the articulatory system, the time axis has a clear left-to-right dependency. On the contrary, vowels and consonants demonstrate very different patterns and occupy almost disjoint frequency ranges. Therefore, we hypothesize, global attention over frequencies is beneficial over local convolution. We obtain 2.4 % relative word error rate reduction (rWERR) on a production scale Conformer transducer replacing its convolutional neural network frontend by the proposed F-Attention module on Alexa traffic. To demonstrate generalizability, we validate this on public LibriSpeech data with a long short term memory-based listen attend and spell architecture obtaining 4.6 % rWERR and demonstrate robustness to (simulated) noisy conditions.
Multi-channel Opus compression for far-field automatic speech recognition with a fixed bitrate budget
Jun 15, 2021

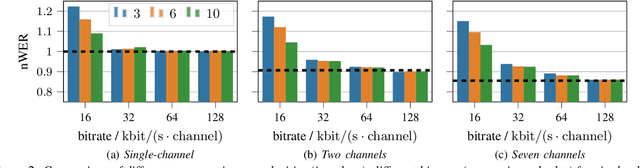
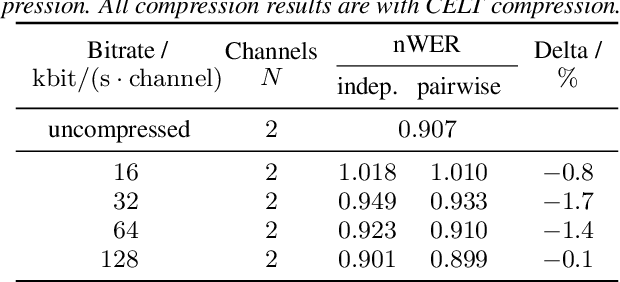
Automatic speech recognition (ASR) in the cloud allows the use of larger models and more powerful multi-channel signal processing front-ends compared to on-device processing. However, it also adds an inherent latency due to the transmission of the audio signal, especially when transmitting multiple channels of a microphone array. One way to reduce the network bandwidth requirements is client-side compression with a lossy codec such as Opus. However, this compression can have a detrimental effect especially on multi-channel ASR front-ends, due to the distortion and loss of spatial information introduced by the codec. In this publication, we propose an improved approach for the compression of microphone array signals based on Opus, using a modified joint channel coding approach and additionally introducing a multi-channel spatial decorrelating transform to reduce redundancy in the transmission. We illustrate the effect of the proposed approach on the spatial information retained in multi-channel signals after compression, and evaluate the performance on far-field ASR with a multi-channel beamforming front-end. We demonstrate that our approach can lead to a 37.5 % bitrate reduction or a 5.1 % relative word error rate reduction for a fixed bitrate budget in a seven channel setup.
Unsupervised training of neural mask-based beamforming
Apr 08, 2019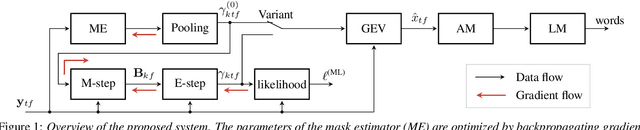
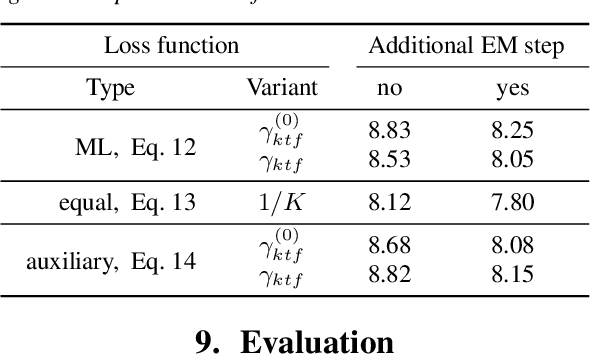
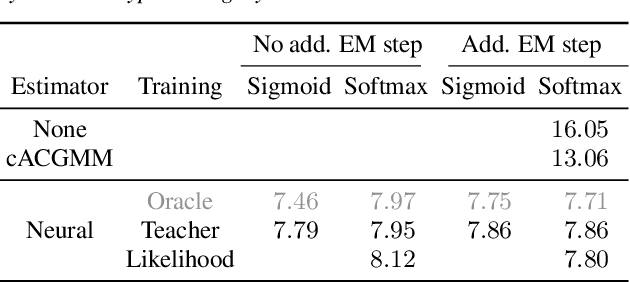
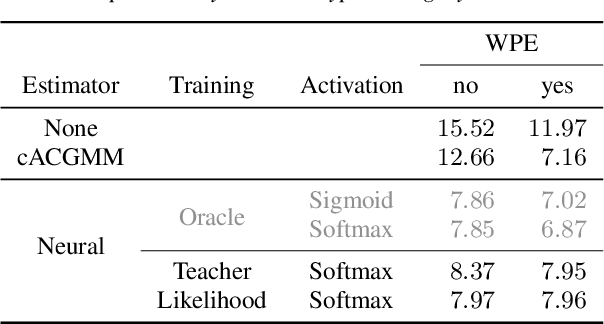
We present an unsupervised training approach for a neural network-based mask estimator in an acoustic beamforming application. The network is trained to maximize a likelihood criterion derived from a spatial mixture model of the observations. It is trained from scratch without requiring any parallel data consisting of degraded input and clean training targets. Thus, training can be carried out on real recordings of noisy speech rather than simulated ones. In contrast to previous work on unsupervised training of neural mask estimators, our approach avoids the need for a possibly pre-trained teacher model entirely. We demonstrate the effectiveness of our approach by speech recognition experiments on two different datasets: one mainly deteriorated by noise (CHiME 4) and one by reverberation (REVERB). The results show that the performance of the proposed system is on par with a supervised system using oracle target masks for training and with a system trained using a model-based teacher.
ESPnet: End-to-End Speech Processing Toolkit
Mar 30, 2018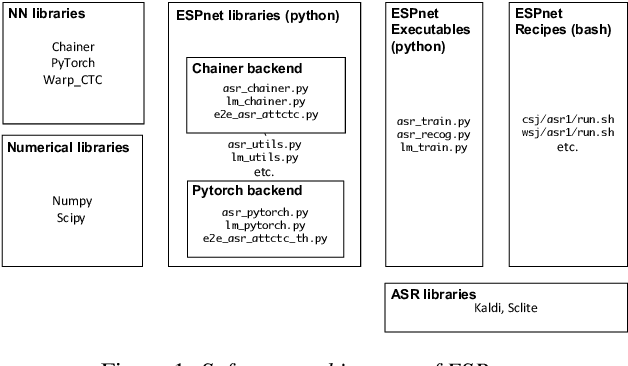
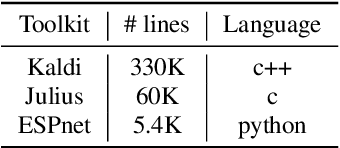
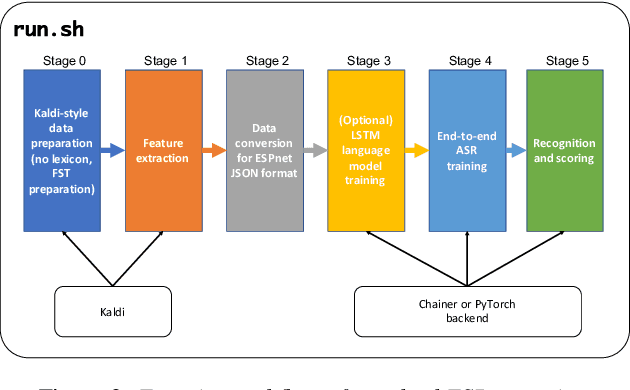
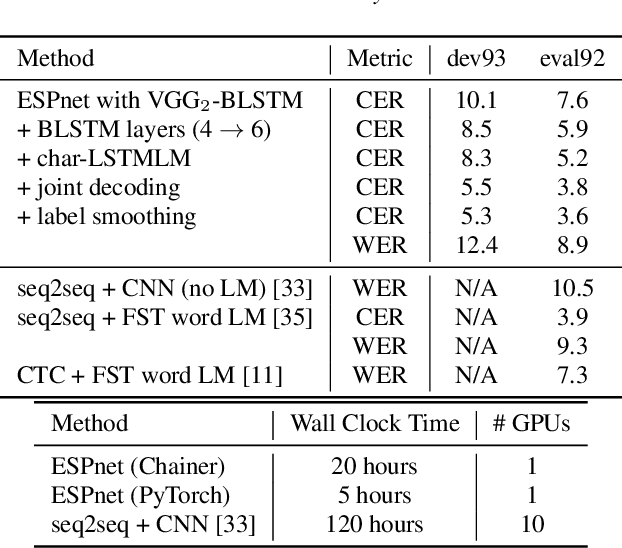
This paper introduces a new open source platform for end-to-end speech processing named ESPnet. ESPnet mainly focuses on end-to-end automatic speech recognition (ASR), and adopts widely-used dynamic neural network toolkits, Chainer and PyTorch, as a main deep learning engine. ESPnet also follows the Kaldi ASR toolkit style for data processing, feature extraction/format, and recipes to provide a complete setup for speech recognition and other speech processing experiments. This paper explains a major architecture of this software platform, several important functionalities, which differentiate ESPnet from other open source ASR toolkits, and experimental results with major ASR benchmarks.