 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Model Fusion
Papers and Code
One-Shot Federated Ridge Regression: Exact Recovery via Sufficient Statistic Aggregation
Jan 13, 2026Federated learning protocols require repeated synchronization between clients and a central server, with convergence rates depending on learning rates, data heterogeneity, and client sampling. This paper asks whether iterative communication is necessary for distributed linear regression. We show it is not. We formulate federated ridge regression as a distributed equilibrium problem where each client computes local sufficient statistics -- the Gram matrix and moment vector -- and transmits them once. The server reconstructs the global solution through a single matrix inversion. We prove exact recovery: under a coverage condition on client feature matrices, one-shot aggregation yields the centralized ridge solution, not an approximation. For heterogeneous distributions violating coverage, we derive non-asymptotic error bounds depending on spectral properties of the aggregated Gram matrix. Communication reduces from $\mathcal{O}(Rd)$ in iterative methods to $\mathcal{O}(d^2)$ total; for high-dimensional settings, we propose and experimentally validate random projection techniques reducing this to $\mathcal{O}(m^2)$ where $m \ll d$. We establish differential privacy guarantees where noise is injected once per client, eliminating the composition penalty that degrades privacy in multi-round protocols. We further address practical considerations including client dropout robustness, federated cross-validation for hyperparameter selection, and comparison with gradient-based alternatives. Comprehensive experiments on synthetic heterogeneous regression demonstrate that one-shot fusion matches FedAvg accuracy while requiring up to $38\times$ less communication. The framework applies to kernel methods and random feature models but not to general nonlinear architectures.
Robo-Dopamine: General Process Reward Modeling for High-Precision Robotic Manipulation
Dec 29, 2025The primary obstacle for applying reinforcement learning (RL) to real-world robotics is the design of effective reward functions. While recently learning-based Process Reward Models (PRMs) are a promising direction, they are often hindered by two fundamental limitations: their reward models lack step-aware understanding and rely on single-view perception, leading to unreliable assessments of fine-grained manipulation progress; and their reward shaping procedures are theoretically unsound, often inducing a semantic trap that misguides policy optimization. To address these, we introduce Dopamine-Reward, a novel reward modeling method for learning a general-purpose, step-aware process reward model from multi-view inputs. At its core is our General Reward Model (GRM), trained on a vast 3,400+ hour dataset, which leverages Step-wise Reward Discretization for structural understanding and Multi-Perspective Reward Fusion to overcome perceptual limitations. Building upon Dopamine-Reward, we propose Dopamine-RL, a robust policy learning framework that employs a theoretically-sound Policy-Invariant Reward Shaping method, which enables the agent to leverage dense rewards for efficient self-improvement without altering the optimal policy, thereby fundamentally avoiding the semantic trap. Extensive experiments across diverse simulated and real-world tasks validate our approach. GRM achieves state-of-the-art accuracy in reward assessment, and Dopamine-RL built on GRM significantly improves policy learning efficiency. For instance, after GRM is adapted to a new task in a one-shot manner from a single expert trajectory, the resulting reward model enables Dopamine-RL to improve the policy from near-zero to 95% success with only 150 online rollouts (approximately 1 hour of real robot interaction), while retaining strong generalization across tasks. Project website: https://robo-dopamine.github.io
SAGE: A Visual Language Model for Anomaly Detection via Fact Enhancement and Entropy-aware Alignment
Jul 10, 2025While Vision-Language Models (VLMs) have shown promising progress in general multimodal tasks, they often struggle in industrial anomaly detection and reasoning, particularly in delivering interpretable explanations and generalizing to unseen categories. This limitation stems from the inherently domain-specific nature of anomaly detection, which hinders the applicability of existing VLMs in industrial scenarios that require precise, structured, and context-aware analysis. To address these challenges, we propose SAGE, a VLM-based framework that enhances anomaly reasoning through Self-Guided Fact Enhancement (SFE) and Entropy-aware Direct Preference Optimization (E-DPO). SFE integrates domain-specific knowledge into visual reasoning via fact extraction and fusion, while E-DPO aligns model outputs with expert preferences using entropy-aware optimization. Additionally, we introduce AD-PL, a preference-optimized dataset tailored for industrial anomaly reasoning, consisting of 28,415 question-answering instances with expert-ranked responses. To evaluate anomaly reasoning models, we develop Multiscale Logical Evaluation (MLE), a quantitative framework analyzing model logic and consistency. SAGE demonstrates superior performance on industrial anomaly datasets under zero-shot and one-shot settings. The code, model and dataset are available at https://github.com/amoreZgx1n/SAGE.
FuseFL: One-Shot Federated Learning through the Lens of Causality with Progressive Model Fusion
Oct 27, 2024



One-shot Federated Learning (OFL) significantly reduces communication costs in FL by aggregating trained models only once. However, the performance of advanced OFL methods is far behind the normal FL. In this work, we provide a causal view to find that this performance drop of OFL methods comes from the isolation problem, which means that local isolatedly trained models in OFL may easily fit to spurious correlations due to the data heterogeneity. From the causal perspective, we observe that the spurious fitting can be alleviated by augmenting intermediate features from other clients. Built upon our observation, we propose a novel learning approach to endow OFL with superb performance and low communication and storage costs, termed as FuseFL. Specifically, FuseFL decomposes neural networks into several blocks, and progressively trains and fuses each block following a bottom-up manner for feature augmentation, introducing no additional communication costs. Comprehensive experiments demonstrate that FuseFL outperforms existing OFL and ensemble FL by a significant margin. We conduct comprehensive experiments to show that FuseFL supports high scalability of clients, heterogeneous model training, and low memory costs. Our work is the first attempt using causality to analyze and alleviate data heterogeneity of OFL.
Landmarks Are Alike Yet Distinct: Harnessing Similarity and Individuality for One-Shot Medical Landmark Detection
Mar 20, 2025
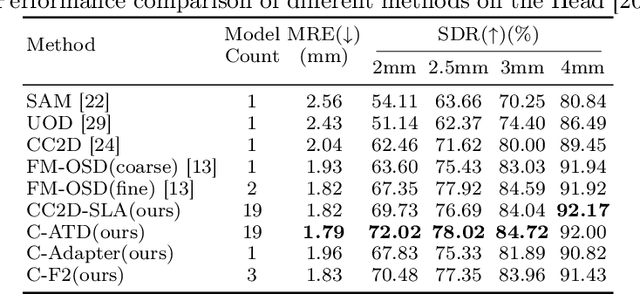
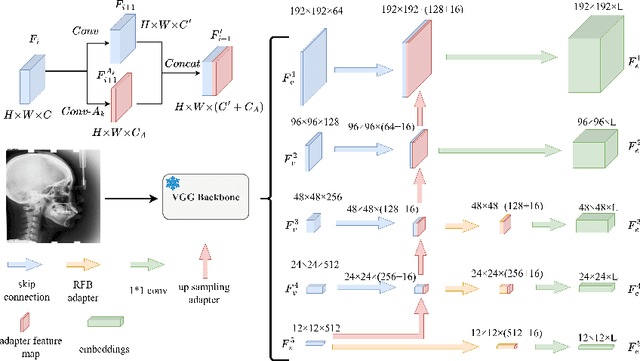
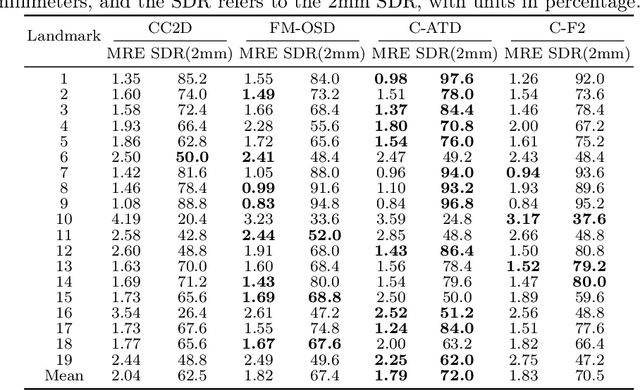
Landmark detection plays a crucial role in medical imaging applications such as disease diagnosis, bone age estimation, and therapy planning. However, training models for detecting multiple landmarks simultaneously often encounters the "seesaw phenomenon", where improvements in detecting certain landmarks lead to declines in detecting others. Yet, training a separate model for each landmark increases memory usage and computational overhead. To address these challenges, we propose a novel approach based on the belief that "landmarks are distinct" by training models with pseudo-labels and template data updated continuously during the training process, where each model is dedicated to detecting a single landmark to achieve high accuracy. Furthermore, grounded on the belief that "landmarks are also alike", we introduce an adapter-based fusion model, combining shared weights with landmark-specific weights, to efficiently share model parameters while allowing flexible adaptation to individual landmarks. This approach not only significantly reduces memory and computational resource requirements but also effectively mitigates the seesaw phenomenon in multi-landmark training. Experimental results on publicly available medical image datasets demonstrate that the single-landmark models significantly outperform traditional multi-point joint training models in detecting individual landmarks. Although our adapter-based fusion model shows slightly lower performance compared to the combined results of all single-landmark models, it still surpasses the current state-of-the-art methods while achieving a notable improvement in resource efficiency.
Guided and Variance-Corrected Fusion with One-shot Style Alignment for Large-Content Image Generation
Dec 17, 2024



Producing large images using small diffusion models is gaining increasing popularity, as the cost of training large models could be prohibitive. A common approach involves jointly generating a series of overlapped image patches and obtaining large images by merging adjacent patches. However, results from existing methods often exhibit obvious artifacts, e.g., seams and inconsistent objects and styles. To address the issues, we proposed Guided Fusion (GF), which mitigates the negative impact from distant image regions by applying a weighted average to the overlapping regions. Moreover, we proposed Variance-Corrected Fusion (VCF), which corrects data variance at post-averaging, generating more accurate fusion for the Denoising Diffusion Probabilistic Model. Furthermore, we proposed a one-shot Style Alignment (SA), which generates a coherent style for large images by adjusting the initial input noise without adding extra computational burden. Extensive experiments demonstrated that the proposed fusion methods improved the quality of the generated image significantly. As a plug-and-play module, the proposed method can be widely applied to enhance other fusion-based methods for large image generation.
Target-Augmented Shared Fusion-based Multimodal Sarcasm Explanation Generation
Feb 11, 2025



Sarcasm is a linguistic phenomenon that intends to ridicule a target (e.g., entity, event, or person) in an inherent way. Multimodal Sarcasm Explanation (MuSE) aims at revealing the intended irony in a sarcastic post using a natural language explanation. Though important, existing systems overlooked the significance of the target of sarcasm in generating explanations. In this paper, we propose a Target-aUgmented shaRed fusion-Based sarcasm explanatiOn model, aka. TURBO. We design a novel shared-fusion mechanism to leverage the inter-modality relationships between an image and its caption. TURBO assumes the target of the sarcasm and guides the multimodal shared fusion mechanism in learning intricacies of the intended irony for explanations. We evaluate our proposed TURBO model on the MORE+ dataset. Comparison against multiple baselines and state-of-the-art models signifies the performance improvement of TURBO by an average margin of $+3.3\%$. Moreover, we explore LLMs in zero and one-shot settings for our task and observe that LLM-generated explanation, though remarkable, often fails to capture the critical nuances of the sarcasm. Furthermore, we supplement our study with extensive human evaluation on TURBO's generated explanations and find them out to be comparatively better than other systems.
FedMHO: Heterogeneous One-Shot Federated Learning Towards Resource-Constrained Edge Devices
Feb 12, 2025



Federated Learning (FL) is increasingly adopted in edge computing scenarios, where a large number of heterogeneous clients operate under constrained or sufficient resources. The iterative training process in conventional FL introduces significant computation and communication overhead, which is unfriendly for resource-constrained edge devices. One-shot FL has emerged as a promising approach to mitigate communication overhead, and model-heterogeneous FL solves the problem of diverse computing resources across clients. However, existing methods face challenges in effectively managing model-heterogeneous one-shot FL, often leading to unsatisfactory global model performance or reliance on auxiliary datasets. To address these challenges, we propose a novel FL framework named FedMHO, which leverages deep classification models on resource-sufficient clients and lightweight generative models on resource-constrained devices. On the server side, FedMHO involves a two-stage process that includes data generation and knowledge fusion. Furthermore, we introduce FedMHO-MD and FedMHO-SD to mitigate the knowledge-forgetting problem during the knowledge fusion stage, and an unsupervised data optimization solution to improve the quality of synthetic samples. Comprehensive experiments demonstrate the effectiveness of our methods, as they outperform state-of-the-art baselines in various experimental setups.
Fusion Matters: Learning Fusion in Deep Click-through Rate Prediction Models
Nov 24, 2024



The evolution of previous Click-Through Rate (CTR) models has mainly been driven by proposing complex components, whether shallow or deep, that are adept at modeling feature interactions. However, there has been less focus on improving fusion design. Instead, two naive solutions, stacked and parallel fusion, are commonly used. Both solutions rely on pre-determined fusion connections and fixed fusion operations. It has been repetitively observed that changes in fusion design may result in different performances, highlighting the critical role that fusion plays in CTR models. While there have been attempts to refine these basic fusion strategies, these efforts have often been constrained to specific settings or dependent on specific components. Neural architecture search has also been introduced to partially deal with fusion design, but it comes with limitations. The complexity of the search space can lead to inefficient and ineffective results. To bridge this gap, we introduce OptFusion, a method that automates the learning of fusion, encompassing both the connection learning and the operation selection. We have proposed a one-shot learning algorithm tackling these tasks concurrently. Our experiments are conducted over three large-scale datasets. Extensive experiments prove both the effectiveness and efficiency of OptFusion in improving CTR model performance. Our code implementation is available here\url{https://github.com/kexin-kxzhang/OptFusion}.
No Re-Train, More Gain: Upgrading Backbones with Diffusion Model for Few-Shot Segmentation
Jul 23, 2024



Few-Shot Segmentation (FSS) aims to segment novel classes using only a few annotated images. Despite considerable process under pixel-wise support annotation, current FSS methods still face three issues: the inflexibility of backbone upgrade without re-training, the inability to uniformly handle various types of annotations (e.g., scribble, bounding box, mask and text), and the difficulty in accommodating different annotation quantity. To address these issues simultaneously, we propose DiffUp, a novel FSS method that conceptualizes the FSS task as a conditional generative problem using a diffusion process. For the first issue, we introduce a backbone-agnostic feature transformation module that converts different segmentation cues into unified coarse priors, facilitating seamless backbone upgrade without re-training. For the second issue, due to the varying granularity of transformed priors from diverse annotation types, we conceptualize these multi-granular transformed priors as analogous to noisy intermediates at different steps of a diffusion model. This is implemented via a self-conditioned modulation block coupled with a dual-level quality modulation branch. For the third issue, we incorporates an uncertainty-aware information fusion module that harmonizing the variability across zero-shot, one-shot and many-shot scenarios. Evaluated through rigorous benchmarks, DiffUp significantly outperforms existing FSS models in terms of flexibility and accuracy.