 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemWeaver: Weaving Hybrid Memories for Traceable Long-Horizon Agentic Reasoning
Jan 26, 2026Large language model-based agents operating in long-horizon interactions require memory systems that support temporal consistency, multi-hop reasoning, and evidence-grounded reuse across sessions. Existing approaches largely rely on unstructured retrieval or coarse abstractions, which often lead to temporal conflicts, brittle reasoning, and limited traceability. We propose MemWeaver, a unified memory framework that consolidates long-term agent experiences into three interconnected components: a temporally grounded graph memory for structured relational reasoning, an experience memory that abstracts recurring interaction patterns from repeated observations, and a passage memory that preserves original textual evidence. MemWeaver employs a dual-channel retrieval strategy that jointly retrieves structured knowledge and supporting evidence to construct compact yet information-dense contexts for reasoning. Experiments on the LoCoMo benchmark demonstrate that MemWeaver substantially improves multi-hop and temporal reasoning accuracy while reducing input context length by over 95\% compared to long-context baselines.
SAGE: A Visual Language Model for Anomaly Detection via Fact Enhancement and Entropy-aware Alignment
Jul 10, 2025While Vision-Language Models (VLMs) have shown promising progress in general multimodal tasks, they often struggle in industrial anomaly detection and reasoning, particularly in delivering interpretable explanations and generalizing to unseen categories. This limitation stems from the inherently domain-specific nature of anomaly detection, which hinders the applicability of existing VLMs in industrial scenarios that require precise, structured, and context-aware analysis. To address these challenges, we propose SAGE, a VLM-based framework that enhances anomaly reasoning through Self-Guided Fact Enhancement (SFE) and Entropy-aware Direct Preference Optimization (E-DPO). SFE integrates domain-specific knowledge into visual reasoning via fact extraction and fusion, while E-DPO aligns model outputs with expert preferences using entropy-aware optimization. Additionally, we introduce AD-PL, a preference-optimized dataset tailored for industrial anomaly reasoning, consisting of 28,415 question-answering instances with expert-ranked responses. To evaluate anomaly reasoning models, we develop Multiscale Logical Evaluation (MLE), a quantitative framework analyzing model logic and consistency. SAGE demonstrates superior performance on industrial anomaly datasets under zero-shot and one-shot settings. The code, model and dataset are available at https://github.com/amoreZgx1n/SAGE.
Balanced Sparsity for Efficient DNN Inference on GPU
Nov 02, 2018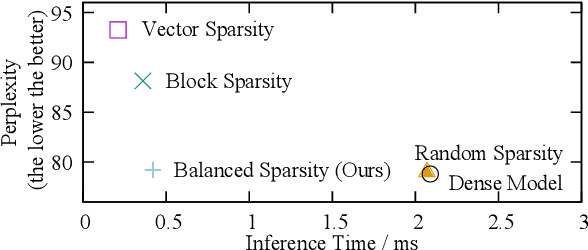
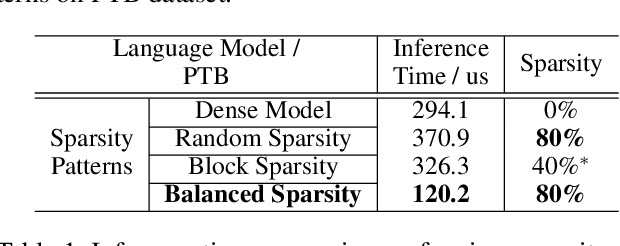

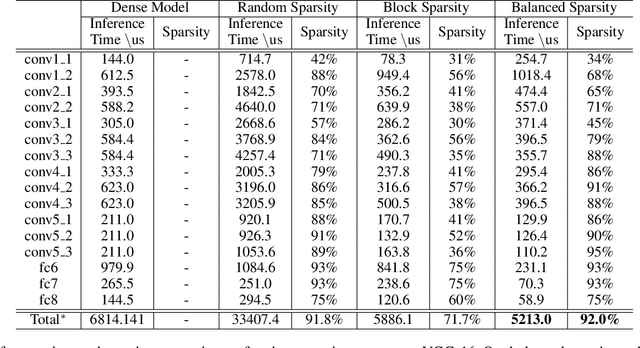
In trained deep neural networks, unstructured pruning can reduce redundant weights to lower storage cost. However, it requires the customization of hardwares to speed up practical inference. Another trend accelerates sparse model inference on general-purpose hardwares by adopting coarse-grained sparsity to prune or regularize consecutive weights for efficient computation. But this method often sacrifices model accuracy. In this paper, we propose a novel fine-grained sparsity approach, balanced sparsity, to achieve high model accuracy with commercial hardwares efficiently. Our approach adapts to high parallelism property of GPU, showing incredible potential for sparsity in the widely deployment of deep learning services. Experiment results show that balanced sparsity achieves up to 3.1x practical speedup for model inference on GPU, while retains the same high model accuracy as fine-grained sparsity.