 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Ad retrieval via LLM-generative Commercial Intention for Sponsored Search Advertising
Apr 02, 2025



The integration of Large Language Models (LLMs) with retrieval systems has shown promising potential in retrieving documents (docs) or advertisements (ads) for a given query. Existing LLM-based retrieval methods generate numeric or content-based DocIDs to retrieve docs/ads. However, the one-to-few mapping between numeric IDs and docs, along with the time-consuming content extraction, leads to semantic inefficiency and limits scalability in large-scale corpora. In this paper, we propose the Real-time Ad REtrieval (RARE) framework, which leverages LLM-generated text called Commercial Intentions (CIs) as an intermediate semantic representation to directly retrieve ads for queries in real-time. These CIs are generated by a customized LLM injected with commercial knowledge, enhancing its domain relevance. Each CI corresponds to multiple ads, yielding a lightweight and scalable set of CIs. RARE has been implemented in a real-world online system, handling daily search volumes in the hundreds of millions. The online implementation has yielded significant benefits: a 5.04% increase in consumption, a 6.37% rise in Gross Merchandise Volume (GMV), a 1.28% enhancement in click-through rate (CTR) and a 5.29% increase in shallow conversions. Extensive offline experiments show RARE's superiority over ten competitive baselines in four major categories.
FedMHO: Heterogeneous One-Shot Federated Learning Towards Resource-Constrained Edge Devices
Feb 12, 2025



Federated Learning (FL) is increasingly adopted in edge computing scenarios, where a large number of heterogeneous clients operate under constrained or sufficient resources. The iterative training process in conventional FL introduces significant computation and communication overhead, which is unfriendly for resource-constrained edge devices. One-shot FL has emerged as a promising approach to mitigate communication overhead, and model-heterogeneous FL solves the problem of diverse computing resources across clients. However, existing methods face challenges in effectively managing model-heterogeneous one-shot FL, often leading to unsatisfactory global model performance or reliance on auxiliary datasets. To address these challenges, we propose a novel FL framework named FedMHO, which leverages deep classification models on resource-sufficient clients and lightweight generative models on resource-constrained devices. On the server side, FedMHO involves a two-stage process that includes data generation and knowledge fusion. Furthermore, we introduce FedMHO-MD and FedMHO-SD to mitigate the knowledge-forgetting problem during the knowledge fusion stage, and an unsupervised data optimization solution to improve the quality of synthetic samples. Comprehensive experiments demonstrate the effectiveness of our methods, as they outperform state-of-the-art baselines in various experimental setups.
Wave-Mamba: Wavelet State Space Model for Ultra-High-Definition Low-Light Image Enhancement
Aug 02, 2024Ultra-high-definition (UHD) technology has attracted widespread attention due to its exceptional visual quality, but it also poses new challenges for low-light image enhancement (LLIE) techniques. UHD images inherently possess high computational complexity, leading existing UHD LLIE methods to employ high-magnification downsampling to reduce computational costs, which in turn results in information loss. The wavelet transform not only allows downsampling without loss of information, but also separates the image content from the noise. It enables state space models (SSMs) to avoid being affected by noise when modeling long sequences, thus making full use of the long-sequence modeling capability of SSMs. On this basis, we propose Wave-Mamba, a novel approach based on two pivotal insights derived from the wavelet domain: 1) most of the content information of an image exists in the low-frequency component, less in the high-frequency component. 2) The high-frequency component exerts a minimal influence on the outcomes of low-light enhancement. Specifically, to efficiently model global content information on UHD images, we proposed a low-frequency state space block (LFSSBlock) by improving SSMs to focus on restoring the information of low-frequency sub-bands. Moreover, we propose a high-frequency enhance block (HFEBlock) for high-frequency sub-band information, which uses the enhanced low-frequency information to correct the high-frequency information and effectively restore the correct high-frequency details. Through comprehensive evaluation, our method has demonstrated superior performance, significantly outshining current leading techniques while maintaining a more streamlined architecture. The code is available at https://github.com/AlexZou14/Wave-Mamba.
FedRKG: A Privacy-preserving Federated Recommendation Framework via Knowledge Graph Enhancement
Jan 20, 2024Federated Learning (FL) has emerged as a promising approach for preserving data privacy in recommendation systems by training models locally. Recently, Graph Neural Networks (GNN) have gained popularity in recommendation tasks due to their ability to capture high-order interactions between users and items. However, privacy concerns prevent the global sharing of the entire user-item graph. To address this limitation, some methods create pseudo-interacted items or users in the graph to compensate for missing information for each client. Unfortunately, these methods introduce random noise and raise privacy concerns. In this paper, we propose FedRKG, a novel federated recommendation system, where a global knowledge graph (KG) is constructed and maintained on the server using publicly available item information, enabling higher-order user-item interactions. On the client side, a relation-aware GNN model leverages diverse KG relationships. To protect local interaction items and obscure gradients, we employ pseudo-labeling and Local Differential Privacy (LDP). Extensive experiments conducted on three real-world datasets demonstrate the competitive performance of our approach compared to centralized algorithms while ensuring privacy preservation. Moreover, FedRKG achieves an average accuracy improvement of 4% compared to existing federated learning baselines.
LightBTSeg: A lightweight breast tumor segmentation model using ultrasound images via dual-path joint knowledge distillation
Nov 18, 2023The accurate segmentation of breast tumors is an important prerequisite for lesion detection, which has significant clinical value for breast tumor research. The mainstream deep learning-based methods have achieved a breakthrough. However, these high-performance segmentation methods are formidable to implement in clinical scenarios since they always embrace high computation complexity, massive parameters, slow inference speed, and huge memory consumption. To tackle this problem, we propose LightBTSeg, a dual-path joint knowledge distillation framework, for lightweight breast tumor segmentation. Concretely, we design a double-teacher model to represent the fine-grained feature of breast ultrasound according to different semantic feature realignments of benign and malignant breast tumors. Specifically, we leverage the bottleneck architecture to reconstruct the original Attention U-Net. It is regarded as a lightweight student model named Simplified U-Net. Then, the prior knowledge of benign and malignant categories is utilized to design the teacher network combined dual-path joint knowledge distillation, which distills the knowledge from cumbersome benign and malignant teachers to a lightweight student model. Extensive experiments conducted on breast ultrasound images (Dataset BUSI) and Breast Ultrasound Dataset B (Dataset B) datasets demonstrate that LightBTSeg outperforms various counterparts.
Tetris-inspired detector with neural network for radiation mapping
Feb 07, 2023In recent years, radiation mapping has attracted widespread research attention and increased public concerns on environmental monitoring. In terms of both materials and their configurations, radiation detectors have been developed to locate the directions and positions of the radiation sources. In this process, algorithm is essential in converting detector signals to radiation source information. However, due to the complex mechanisms of radiation-matter interaction and the current limitation of data collection, high-performance, low-cost radiation mapping is still challenging. Here we present a computational framework using Tetris-inspired detector pixels and machine learning for radiation mapping. Using inter-pixel padding to increase the contrast between pixels and neural network to analyze the detector readings, a detector with as few as four pixels can achieve high-resolution directional mapping. By further imposing Maximum a Posteriori (MAP) with a moving detector, further radiation position localization is achieved. Non-square, Tetris-shaped detector can further improve performance beyond the conventional grid-shaped detector. Our framework offers a new avenue for high quality radiation mapping with least number of detector pixels possible, and is anticipated to be capable to deploy for real-world radiation detection with moderate validation.
Multi-stage Pre-training over Simplified Multimodal Pre-training Models
Jul 22, 2021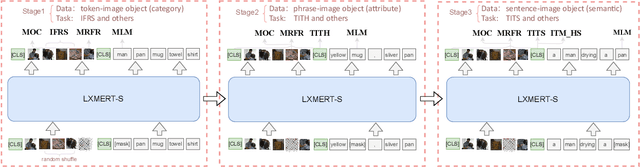
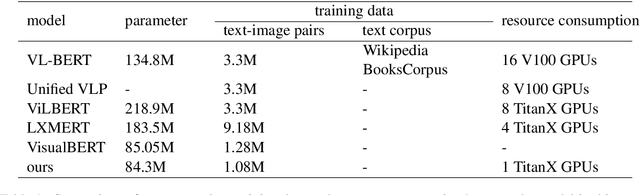
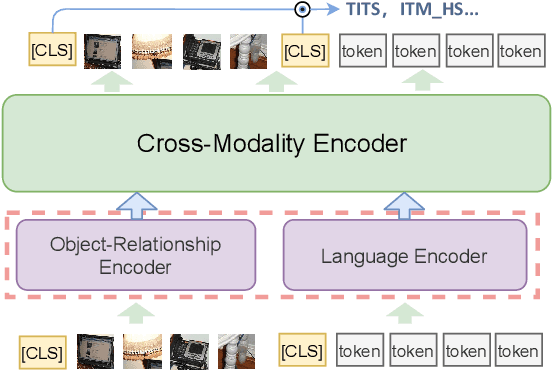
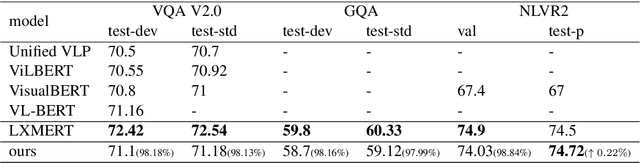
Multimodal pre-training models, such as LXMERT, have achieved excellent results in downstream tasks. However, current pre-trained models require large amounts of training data and have huge model sizes, which make them difficult to apply in low-resource situations. How to obtain similar or even better performance than a larger model under the premise of less pre-training data and smaller model size has become an important problem. In this paper, we propose a new Multi-stage Pre-training (MSP) method, which uses information at different granularities from word, phrase to sentence in both texts and images to pre-train the model in stages. We also design several different pre-training tasks suitable for the information granularity in different stage in order to efficiently capture the diverse knowledge from a limited corpus. We take a Simplified LXMERT (LXMERT- S), which has only 45.9% parameters of the original LXMERT model and 11.76% of the original pre-training data as the testbed of our MSP method. Experimental results show that our method achieves comparable performance to the original LXMERT model in all downstream tasks, and even outperforms the original model in Image-Text Retrieval task.